Clear Sky Science · fr
Empilement vertical des conteneurs en terminal portuaire basé sur le fuzzy c-means
Pourquoi un empilement des conteneurs plus intelligent compte
Chaque année, près d’un milliard de boîtes métalliques standardisées — des conteneurs maritimes — passent par les ports du monde entier. Mettre ces boîtes rapidement sur les navires et en descendre est essentiel pour maintenir le flux des marchandises et maîtriser les coûts. Pourtant, un problème étonnamment simple ralentit les opérations : quand le conteneur dont on a besoin est enfoui sous d’autres, les grues doivent réarranger la pile, ce qui gaspille du temps et du carburant. Cet article explore une nouvelle méthode, fondée sur les données, pour empiler les conteneurs selon leur poids afin de réduire ces réarrangements coûteux, rendant les ports plus rapides et plus fiables sans nécessiter d’espace ou d’équipement supplémentaires.
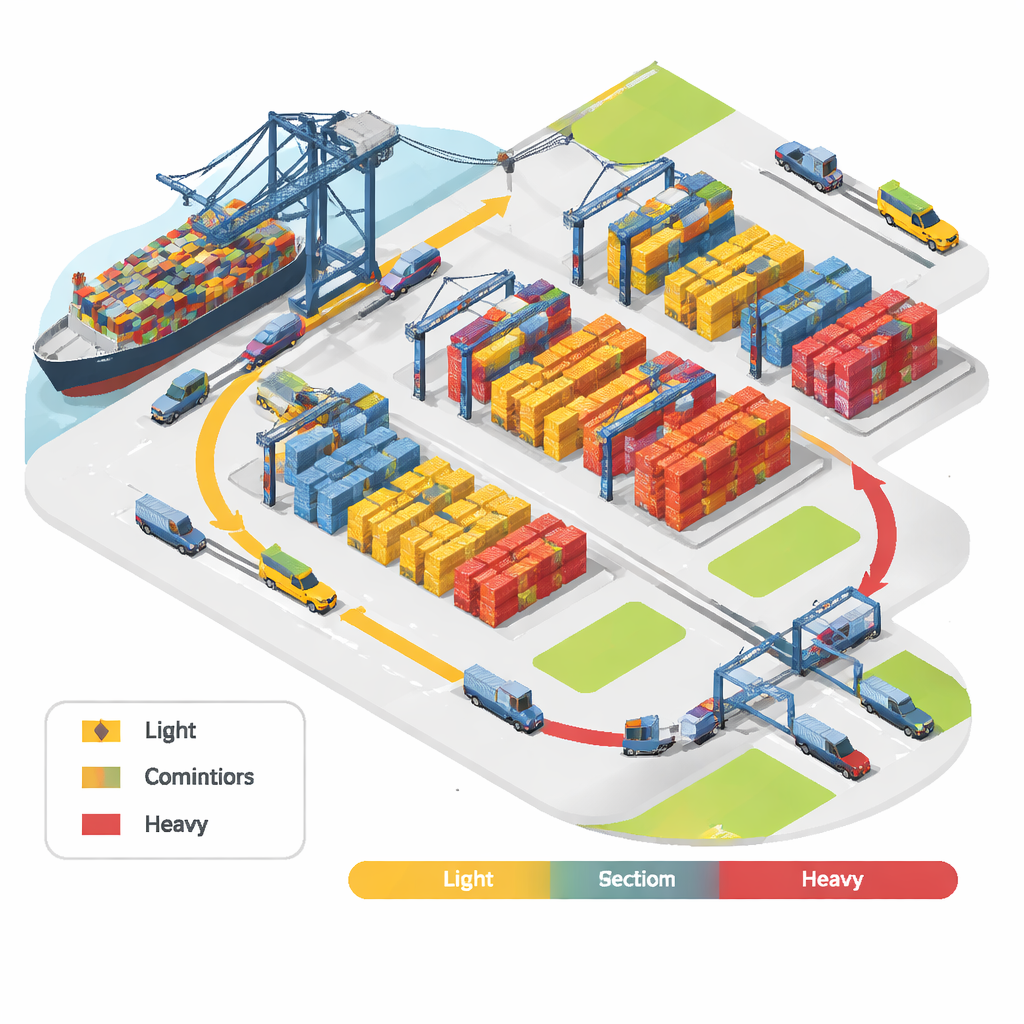
Le problème caché des piles désordonnées
Les parcs à conteneurs paraissent ordonnés de loin, mais la séquence dans laquelle les conteneurs doivent être chargés et déchargés est très incertaine. Les conteneurs à embarquer arrivent au terminal avant l’arrivée du navire, et leur ordre de chargement final est influencé par les règles de stabilité du navire et par des plans d’arrimage qui évoluent. En règle générale, les conteneurs lourds vont plus bas dans le navire, les plus légers plus haut. Toutefois, à l’arrivée des conteneurs, les opérateurs ignorent souvent si un conteneur donné sera considéré comme « lourd » ou « léger » par rapport à la cargaison finale. Les stratégies traditionnelles tentent de prioriser les lourds ou d’assigner des catégories de poids fixes, mais cela peut se retourner contre elles : un conteneur classé comme lourd un jour peut être considéré comme moyen le lendemain, entraînant des réarrangements supplémentaires lors du chargement.
Empilements verticaux et pourquoi l’équilibre des poids importe
Les ports utilisent différentes façons d’organiser les conteneurs : côte à côte en rangées (horizontal), empilés par type similaire en colonnes (vertical), ou un hybride des deux. Cette étude se concentre sur l’empilement vertical, où des conteneurs de caractéristiques similaires sont placés dans la même pile en colonne. L’empilement vertical est attrayant car il facilite l’accès à un conteneur d’un intervalle de poids donné sans perturber trop d’autres. Mais en réalité, le nombre de conteneurs dans chaque intervalle de poids change d’un voyage à l’autre. Si les groupes de poids sont définis par des seuils rigides — par exemple tous les 5 tonnes — beaucoup de conteneurs proches des limites de groupe se retrouvent dans des piles différentes alors qu’ils pèsent pratiquement la même chose. Cela augmente la variation de poids à l’intérieur des piles et réduit les bénéfices de l’empilement vertical.
Laisser les données tracer les frontières
Les auteurs proposent une nouvelle stratégie appelée empilement vertical séquentiel basé sur le Fuzzy C-means, ou FVSS. Plutôt que de décider à l’avance où placer les limites de chaque groupe de poids, la méthode examine les données historiques de poids des navires sur la même route et laisse un algorithme de clustering flou identifier des regroupements naturels. « Flou » signifie ici qu’un poids de conteneur peut appartenir en partie à plusieurs groupes, reflétant l’absence de frontière nette entre, par exemple, moyen et lourd. L’algorithme choisit combien de clusters conviennent le mieux aux données passées de chaque navire et identifie un centre de poids pour chaque cluster. Le parc est alors prédivisé en un nombre de piles proportionnel au nombre de conteneurs qui tombent typiquement dans chaque groupe de poids, et chaque pile reçoit un poids de référence basé sur ces centres.
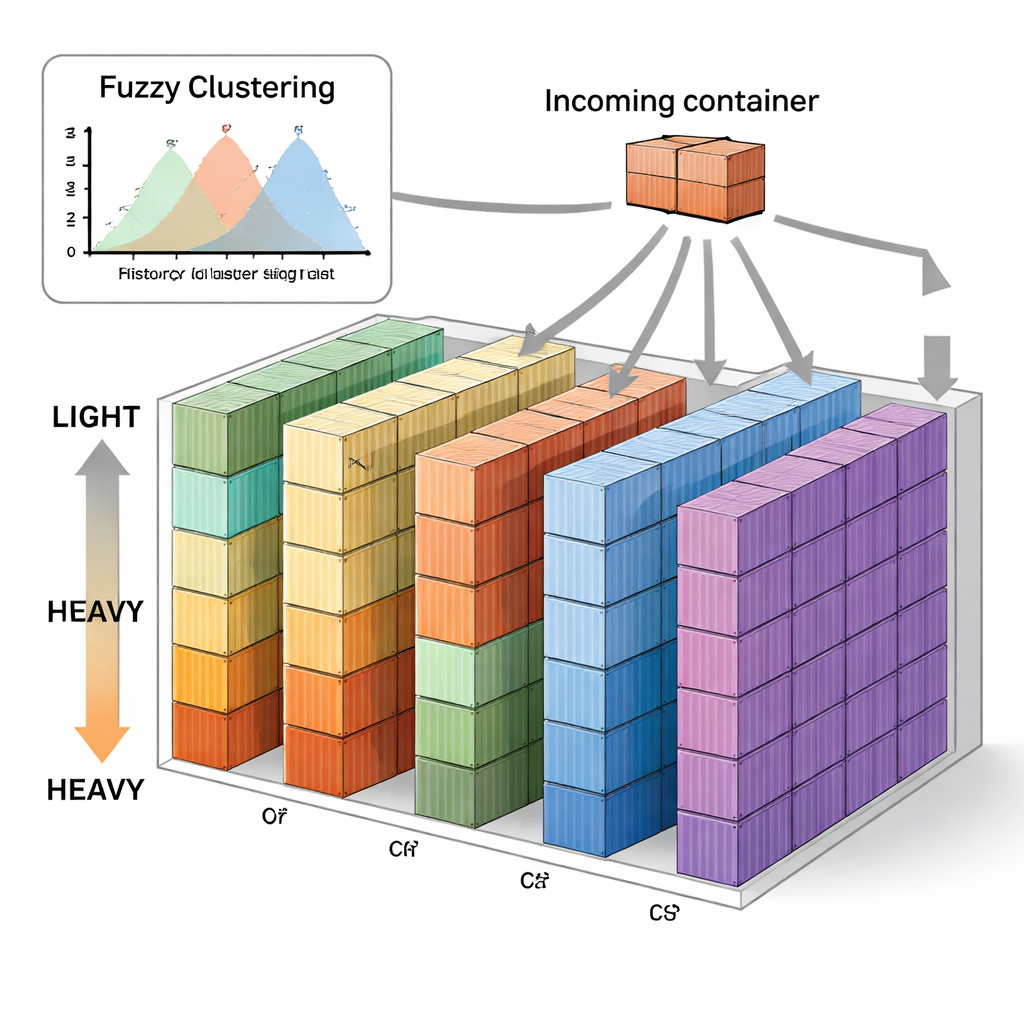
Règles simples pour des décisions en temps réel
Une fois le parc configuré de cette façon, les opérations quotidiennes suivent une règle simple. À l’arrivée de chaque conteneur, sa classe de poids approximative est déterminée à l’aide des clusters flous. S’il y a de la place dans les piles réservées à cette classe, le conteneur y est placé. Si ces piles sont pleines ou si plusieurs options sont possibles, le système choisit la pile dont le poids de référence est le plus proche du poids réel du conteneur. Avec le temps, cela guide doucement les conteneurs de poids similaire vers les mêmes piles sans optimisation complexe ni entraînement continu d’apprentissage automatique. Les auteurs ont testé cette approche sur dix mois de données réelles du terminal de Busan en Corée, en la comparant à plusieurs méthodes connues, incluant l’empilement aléatoire, une stratégie hybride horizontal–vertical et des techniques antérieures basées sur des mélanges gaussiens et l’apprentissage en ligne.
Ce que les résultats signifient pour les ports
La mesure clé de l’étude est l’étendue de la variation des poids des conteneurs à l’intérieur de chaque pile — une dispersion plus faible signifie qu’il est plus facile de trouver des conteneurs appropriés lors du chargement du navire avec moins de réarrangements. Sur plusieurs navires et deux configurations de parc (5 et 10 piles), la stratégie FVSS a réduit la variance des poids bien plus que les approches concurrentes, avec des améliorations allant jusqu’à 78 % par rapport à l’empilement aléatoire et des gains substantiels par rapport à d’autres méthodes avancées. De façon cruciale, la performance est restée solide même lorsque les chercheurs ont délibérément altéré les poids des conteneurs pour simuler des erreurs et des changements de dernière minute. Pour les exploitants portuaires, cela signifie qu’ils peuvent obtenir des opérations de grue plus fluides et des temps de rotation des navires plus courts en s’appuyant sur un ensemble de règles automatisé mais transparent, facile à mettre à jour au fil des voyages, sans investir dans une infrastructure informatique lourde ou des systèmes d’apprentissage complexes.
Citation: Lee, S., Lee, SH., Choi, S.C. et al. Fuzzy C-means clustering based vertical container stacking in container terminals. Sci Rep 16, 6891 (2026). https://doi.org/10.1038/s41598-026-37994-x
Mots-clés: terminaux à conteneurs, empilement en parc, clustering flou, logistique maritime, efficacité opérationnelle