Clear Sky Science · fr
Correction des étiquettes bruitées par distillation comparative : une approche d'adaptation de domaine
Pourquoi les données désordonnées sont un problème croissant
L'intelligence artificielle moderne prospère grâce aux données, mais ces dernières sont souvent erronées, incomplètes ou étiquetées de façon incohérente. Lorsque les étiquettes sont bruitées — par exemple une photo de chat étiquetée comme chien — les systèmes d'apprentissage peuvent être induits en erreur, perdant en précision et en fiabilité. Cet article s'attaque à ce problème concret : comment entraîner des systèmes de reconnaissance d'images qui restent performants même lorsque les étiquettes d'entraînement sont imparfaites et que les images proviennent d'environnements différents, comme des boutiques en ligne versus des photos du monde réel.
Apprendre entre différents mondes
En pratique, les modèles d'IA apprennent souvent à partir d'un « monde source » où les étiquettes sont soigneusement vérifiées, puis doivent fonctionner dans un « monde cible » où les étiquettes sont rares et sujettes à l'erreur. Par exemple, des objets de bureau photographiés en studio sont propres et correctement étiquetés, tandis que des photos prises par webcam ou au quotidien des mêmes objets sont désordonnées et étiquetées de façon inconsistante. Les méthodes traditionnelles d'adaptation de domaine cherchent à combler cet écart en alignant les statistiques globales des deux mondes. Cependant, elles supposent généralement que les étiquettes cibles, lorsqu'elles sont disponibles, sont correctes — une hypothèse risquée qui s'effondre dans les applications réelles avec des annotations collaboratives, des capteurs de faible qualité ou des outils d'annotation automatique.
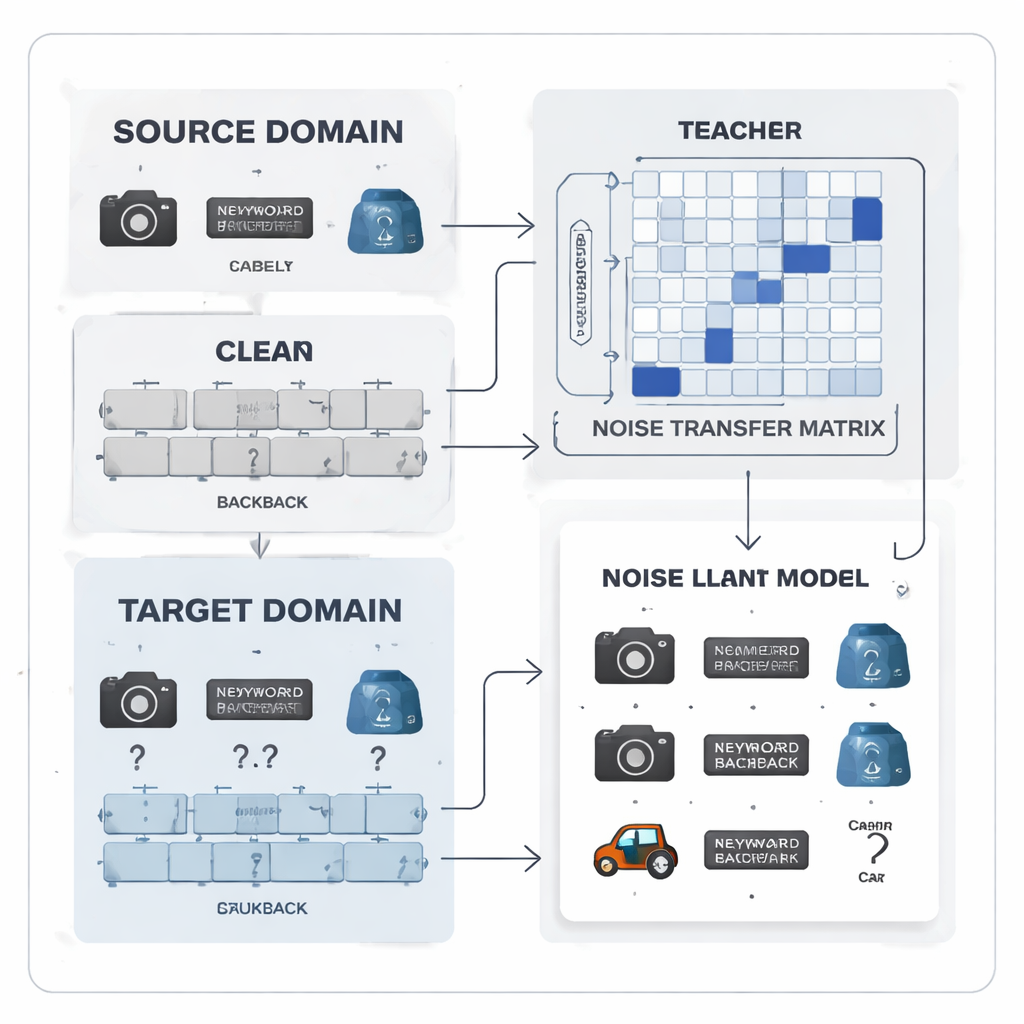
Transformer les erreurs d'étiquetage en motif apprenable
Les auteurs proposent de considérer le bruit d'étiquetage non pas comme un chaos aléatoire mais comme un motif apprenable. Ils introduisent une « matrice de transfert de bruit », un tableau qui capture la probabilité pour qu'une classe vraie soit incorrectement étiquetée comme une autre. Plutôt que d'estimer cette matrice à partir d'un petit nombre d'exemples parfaits « ancrés » — ce qui est irréaliste quand les étiquettes sont bruitées et les classes déséquilibrées — la matrice est apprise directement pendant l'entraînement. Pour démarrer l'apprentissage, la méthode construit des « prototypes » de catégorie, empreintes moyennes de caractéristiques pour chaque classe extraites par un modèle pré-entraîné puissant. La similarité entre ces prototypes sert à initialiser la matrice de sorte que les catégories confusables, comme des outils de bureau similaires, soient plus fortement liées dès le départ, donnant au système une capacité précoce à corriger les étiquettes.
Travail d'équipe enseignant–étudiant pour des signaux plus propres
Au cœur du système se trouve une paire réseau enseignant–étudiant. L'enseignant repose sur un grand modèle de vision auto-supervisé qui a appris des représentations visuelles riches à partir de vastes données non étiquetées. L'étudiant est un réseau plus léger qui doit bien fonctionner sur les données cibles bruitées. L'enseignant produit des scores de prédiction « souples » qui révèlent à quel point les classes sont liées ; à partir de ces scores, la méthode construit une matrice de corrélation des classes qui résume quelles étiquettes ont tendance à coexister. Cette matrice sert de guide, orientant la matrice de transfert de bruit vers des corrections plus réalistes. En parallèle, l'étudiant est formé à reproduire le comportement de l'enseignant via un processus connu sous le nom de distillation, tandis que l'apprentissage contrastif encourage les deux réseaux à produire des représentations internes similaires pour différentes vues augmentées d'une même image et des représentations distinctes pour des objets différents.
Stabiliser les corrections et éviter la surconfiance
Laisser la matrice de transfert de bruit évoluer librement pourrait la rendre instable ou trop sensible aux valeurs aberrantes. Pour l'empêcher, les auteurs utilisent une astuce mathématique basée sur la décomposition en valeurs singulières, qui décompose la matrice en directions de base. En pénalisant le « volume » global implicite de ces directions, la méthode décourage les distorsions extrêmes qui amplifieraient le bruit. Un autre problème apparaît lorsque le modèle devient trop sûr de lui, attribuant presque toute la probabilité à une seule classe ; sous de telles prédictions nettes, il devient difficile de corriger des étiquettes erronées. Pour y remédier, la méthode ajoute une forme de régularisation d'entropie, basée sur l'entropie de Tsallis, qui maintient les probabilités de prédiction plus lissées. Cela facilite le réajustement partiel de la masse de probabilité d'une classe incorrecte vers des alternatives plus plausibles par la matrice de transfert de bruit.
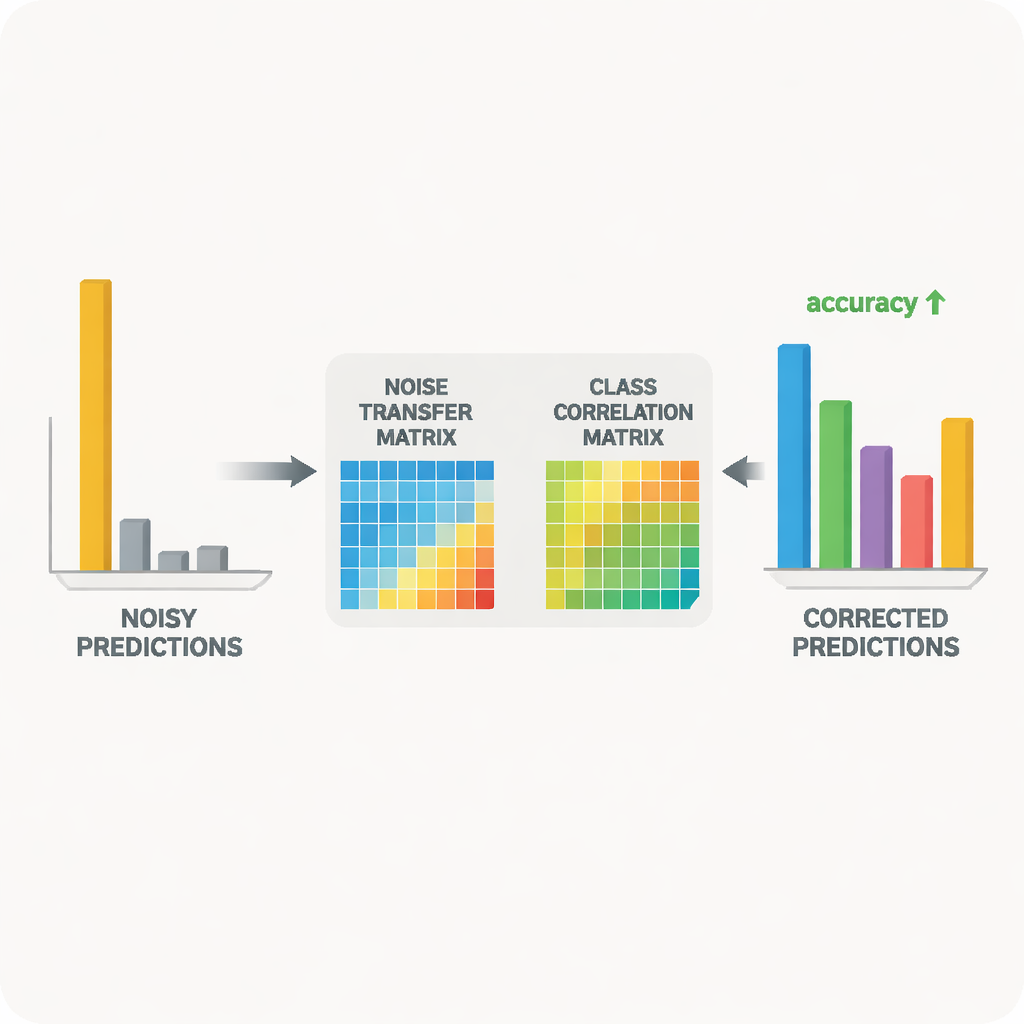
Valider l'idée sur des collections d'images réelles
Les chercheurs ont testé leur approche sur deux bancs d'essai largement utilisés pour la reconnaissance d'objets inter-domaines : Office-31 et Office-Home, qui comprennent des images d'objets de bureau courants dans plusieurs styles tels que photos produit, clip art et instantanés du monde réel. Sur une variété de tâches « entraîner sur un style, tester sur un autre », leur méthode a égalé ou dépassé les algorithmes de pointe, en particulier dans les cas les plus difficiles où le décalage entre domaines est le plus important. Des études détaillées ont montré que chaque composant — le contrôle de volume pour la matrice de bruit, l'orientation par la corrélation des classes et le lissage par entropie — apportait des gains mesurables. Des visualisations de la matrice apprise et de l'espace des caractéristiques ont confirmé que, au fil de l'entraînement, les exemples mal étiquetés étaient progressivement rapprochés de leurs catégories correctes et que les distributions d'images source et cible devenaient mieux alignées.
Ce que cela signifie pour les systèmes d'IA du quotidien
Pour un non-spécialiste, la conclusion essentielle est que ce travail rend les modèles d'IA plus tolérants aux erreurs humaines et mécaniques dans l'étiquetage des données, en particulier lorsque ces modèles doivent passer de conditions de laboratoire propres à des environnements réels plus désordonnés. En apprenant explicitement comment les étiquettes ont tendance à se tromper et en utilisant un puissant modèle enseignant pour guider les corrections, la méthode peut assainir des signaux d'entraînement bruités et produire des classificateurs plus précis et plus robustes. Bien que l'approche nécessite un calcul supplémentaire, elle ouvre la voie à un avenir où de grands jeux de données imparfaits collectés « dans la nature » pourront être exploités de façon plus sûre et efficace, réduisant notre dépendance à l'annotation manuelle fastidieuse.
Citation: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Mots-clés: étiquettes bruitées, adaptation de domaine, distillation des connaissances, classification d'images, apprentissage semi-supervisé