Clear Sky Science · fr
Critiques distributionnelles jumelles sensibles au risque avec une borne inférieure de confiance lambda pour l’apprentissage par renforcement en contrôle continu
Apprendre aux robots à être prudents
Beaucoup des robots et des programmes de jeux les plus impressionnants d’aujourd’hui reposent sur l’apprentissage par renforcement, un processus d’entraînement par essai-erreur où des agents logiciels apprennent en collectant des récompenses. Mais ces agents poursuivent souvent le score le plus élevé sans tenir compte du risque associé à leurs décisions, ce qui conduit à un apprentissage instable et à des plantages occasionnels. Cet article présente une méthode appelée TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound) qui apprend à ces agents non seulement à viser haut, mais aussi à rester raisonnablement sûrs pendant l’apprentissage.
Pourquoi la stabilité est importante pour les machines apprenantes
Les algorithmes standard de contrôle continu, comme les très utilisés TD3 et Soft Actor–Critic (SAC), ont permis à des robots de courir, sauter et se maintenir en équilibre dans des simulateurs complexes. Cependant, ces méthodes évaluent typiquement chaque action à l’aide d’un seul nombre : une estimation de la récompense qu’elle rapportera à long terme. Ce score unique peut être trompeur lorsque le processus d’apprentissage est bruyant, amenant le système à surestimer la qualité de certaines actions. Le résultat est une courbe d’apprentissage qui peut sembler solide en moyenne mais varier fortement d’une exécution à l’autre, ce qui est problématique si le même algorithme doit piloter des machines réelles ou des systèmes critiques pour la sécurité.
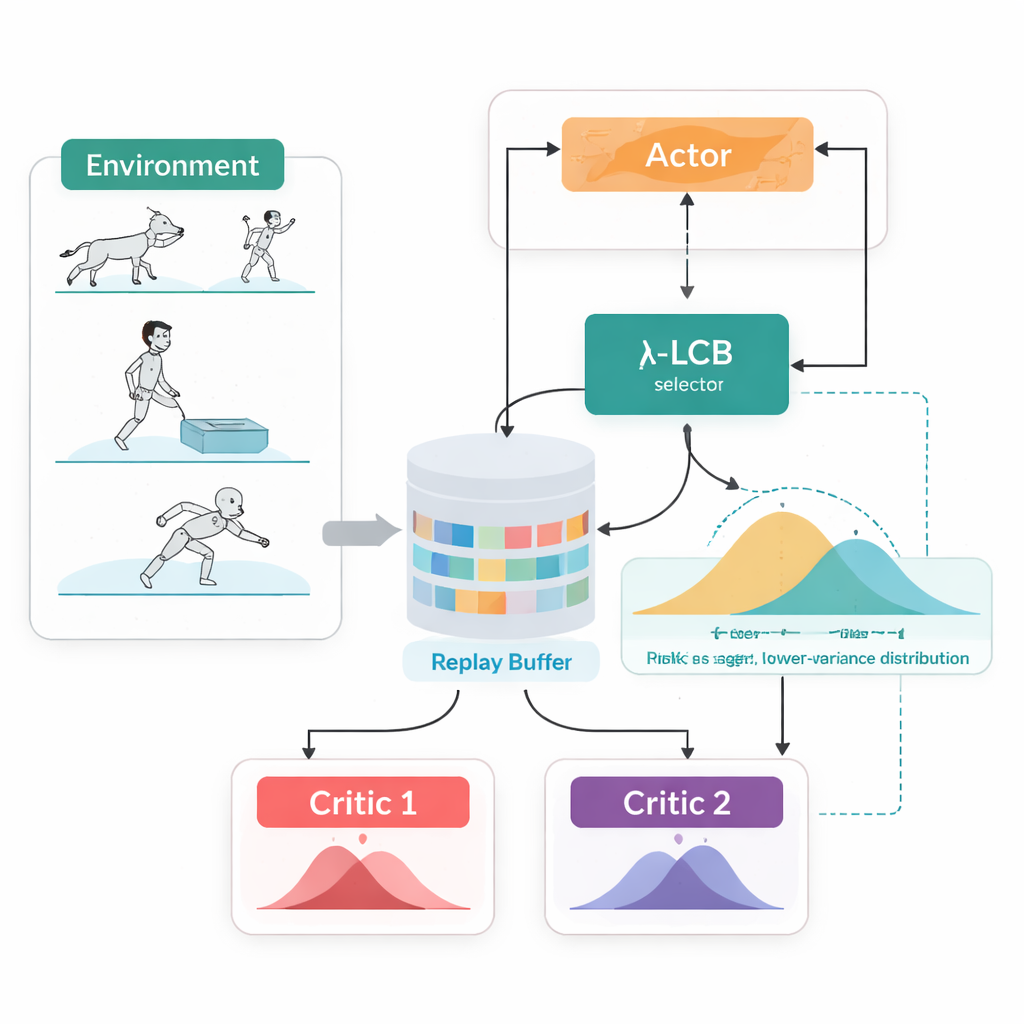
Considérer des avenirs complets, pas des nombres uniques
TDC-λ aborde ce problème en modifiant la façon dont l’agent évalue son avenir. Plutôt que de prédire une seule récompense attendue pour chaque action, il apprend deux « critiques » séparés qui chacun produisent une distribution complète des retours futurs possibles. À partir de ces distributions, l’algorithme calcule non seulement l’espérance mais aussi l’étendue des possibilités. Cette dispersion reflète l’incertitude ou le risque. En appliquant une règle simple, résumée par une borne inférieure de confiance, TDC-λ privilégie le critique qui prédit un résultat plus sûr : celui qui peut être légèrement moins optimiste mais soutenu par des preuves plus cohérentes. Un seul paramètre, le paramètre de risque λ, règle de manière continue le degré de prudence de cette sélection — allant d’un comportement comparable à TD3 lorsque λ est zéro à une attitude plus conservatrice lorsque λ augmente.
Une boucle d’entraînement, deux manières d’agir
Une autre caractéristique pratique de TDC-λ est qu’il prend en charge à la fois des modalités déterministes et stochastiques pour choisir les actions au sein d’un même cadre unifié. Pendant l’entraînement, on peut opter pour une politique déterministe classique ou pour une politique gaussienne aplatie par tanh qui échantillonne des actions, favorisant l’exploration. Quelle que soit cette décision, les critiques distributionnelles jumelles sont entraînées de la même manière, et l’évaluation utilise toujours l’action moyenne déterministe. Ce choix profite à des résultats antérieurs montrant que le comportement déterministe au moment du test fonctionne souvent aussi bien, voire mieux que l’échantillonnage, tout en permettant des politiques riches et propices à l’exploration pendant l’apprentissage.
Mettre la méthode à l’épreuve
Les auteurs ont évalué TDC-λ sur cinq tâches de référence MuJoCo populaires où des robots simulés comme HalfCheetah, Hopper, Ant, Walker2d et Humanoid doivent apprendre à se déplacer efficacement. Sur ces tâches, la nouvelle méthode égalait ou améliorait la performance finale de baselines solides tels que TD3, DDPG, SAC et une approche avancée basée sur les flux appelée MEOW, tout en montrant systématiquement une variabilité plus faible entre les exécutions répétées. Dans les tâches plus difficiles et de plus grande dimension comme Humanoid, des valeurs légèrement supérieures de λ — donc des estimations cibles plus prudentes — ont conduit aux meilleurs retours à long terme et aux bandes de performance les plus serrées. Des expériences supplémentaires sur d’autres simulateurs (PyBullet et NVIDIA Isaac) et des diagnostics suivant la variabilité du signal d’apprentissage ont corroboré la constatation que TDC-λ rend l’apprentissage plus stable sans le ralentir.
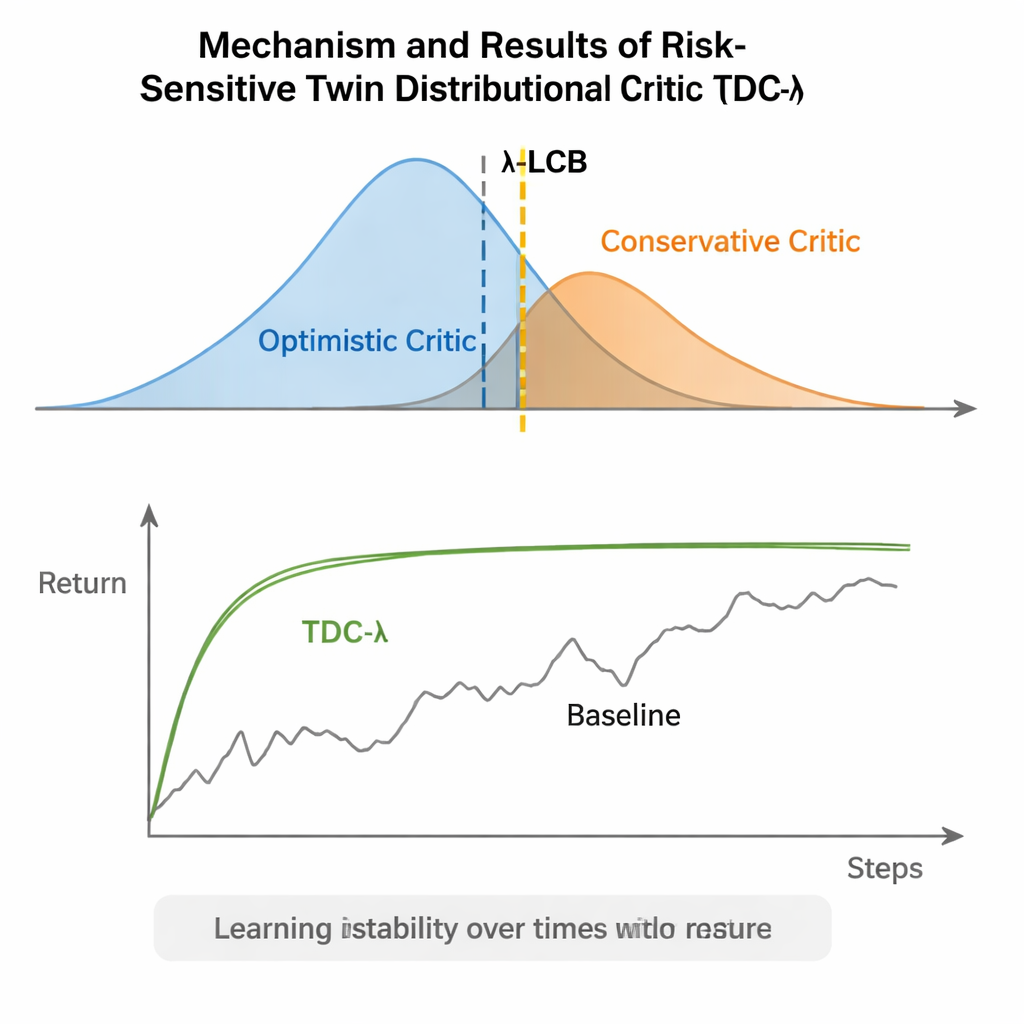
Un réglage simple pour un apprentissage plus sûr
En termes simples, TDC-λ offre aux systèmes d’apprentissage par renforcement une « marge de sécurité » lorsqu’ils décident combien se fier à leur propre optimisme. En apprenant des distributions complètes des résultats possibles puis en privilégiant le critique le plus sûr à l’aide du bouton λ, l’algorithme réduit les oscillations importantes lors de l’entraînement tout en préservant une performance finale élevée. Pour les praticiens, cela fournit un moyen pratique de construire des contrôleurs plus fiables pour les robots et autres systèmes de contrôle continu : commencer avec un λ modérément conservateur et l’ajuster en fonction de la volatilité observée du processus d’apprentissage. Le message plus large est que façonner soigneusement les cibles d’apprentissage de l’agent peut apporter une grande partie de la robustesse souvent attribuée à des architectures plus complexes, rendant l’apprentissage par renforcement avancé à la fois plus stable et plus accessible.
Citation: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Mots-clés: apprentissage par renforcement, contrôle continu, apprentissage sensible au risque, critiques distributionnelles, robotique