Clear Sky Science · fr
Modèle de prévision de la qualité de l’air basé sur un cadre hybride d’apprentissage profond
Pourquoi des prévisions d’air plus propres comptent pour vous
Lorsque le smog enveloppe une ville, les gens doivent soudainement prendre des décisions pratiques : est‑il sûr de courir dehors, d’envoyer les enfants à l’école ou de maintenir les usines en activité ? Ces choix dépendent de notre capacité à prévoir de petites particules polluantes appelées PM2.5, suffisamment fines pour pénétrer profondément dans les poumons. Cette étude présente un nouveau modèle informatique qui exploite les progrès récents de l’intelligence artificielle pour prédire les niveaux de PM2.5 dans les villes chinoises de façon plus précise et plus rapide que de nombreux outils existants, offrant potentiellement au public et aux décideurs des alertes plus fiables et plus anticipées.
Des ciels enfumés aux données intelligentes
La pollution atmosphérique est devenue une menace sanitaire persistante dans de nombreuses zones urbaines, en particulier dans le nord de la Chine, où des niveaux élevés de PM2.5 sont associés à des maladies respiratoires et cardiovasculaires. Les villes exploitent désormais des réseaux denses de stations de surveillance qui enregistrent chaque heure les PM2.5, d’autres polluants et les conditions météorologiques locales. Les méthodes traditionnelles de prévision reposent sur des mathématiques simplifiées ou des modèles physiques élaborés manuellement, qui peinent à saisir la réalité chaotique et non linéaire des vents tourbillonnants, des variations de température et de l’activité humaine. En revanche, la nouvelle approche, baptisée CBLA, laisse les données « parler d’elles‑mêmes » en entraînant des réseaux neuronaux modernes sur plusieurs années d’observations provenant de Pékin et de Guangzhou.
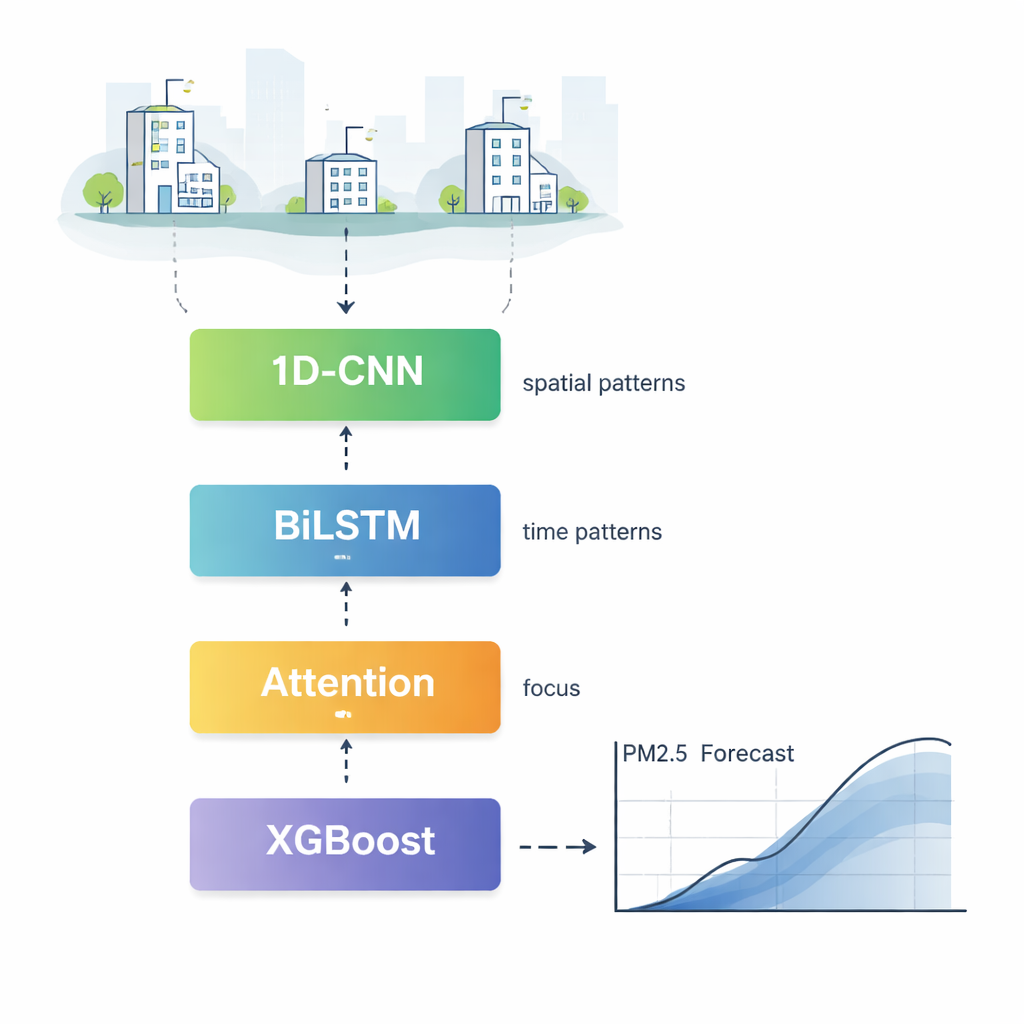
Comment fonctionne le nouveau moteur de prévision
CBLA agit comme une équipe hiérarchisée de spécialistes qui examinent les données de pollution sous différents angles avant de voter pour une prévision finale. D’abord, un composant appelé réseau de convolution unidimensionnel parcourt les mesures provenant de nombreuses stations de surveillance pour identifier des motifs récurrents dans l’espace, par exemple la façon dont la fumée tend à se propager d’un quartier à l’autre. Ensuite, un réseau à mémoire bidirectionnelle lit les historiques de pollution dans le sens direct et inverse du temps, apprenant comment les niveaux d’aujourd’hui dépendent à la fois des conditions récentes et des conditions un peu plus anciennes. Un mécanisme d’attention met alors en évidence les heures et les caractéristiques les plus influentes, permettant au modèle de se concentrer davantage, par exemple, sur le pic marqué d’hier et les vents forts plutôt que sur des mesures lointaines et moins pertinentes.
Ajouter la météo pour affiner le tableau
La pollution ne se déplace pas isolément ; elle est portée par la météo changeante. Pour intégrer proprement cette information, les auteurs ajoutent une seconde étape qui alimente à la fois la prévision préliminaire du réseau neuronal et des données météorologiques détaillées — telles que la vitesse du vent, l’humidité et la température — dans un puissant algorithme basé sur des arbres appelé XGBoost. Cette étape agit comme un prévisionniste expérimenté qui recoupe l’estimation initiale avec la météo actuelle, ajustant la prédiction à la hausse ou à la baisse. Les tests montrent que cette combinaison réduit les erreurs de prédiction typiques et améliore l’adéquation entre la sortie du modèle et les mesures réelles, notamment lors d’accumulations soudaines de pollution ou d’événements de dispersion.
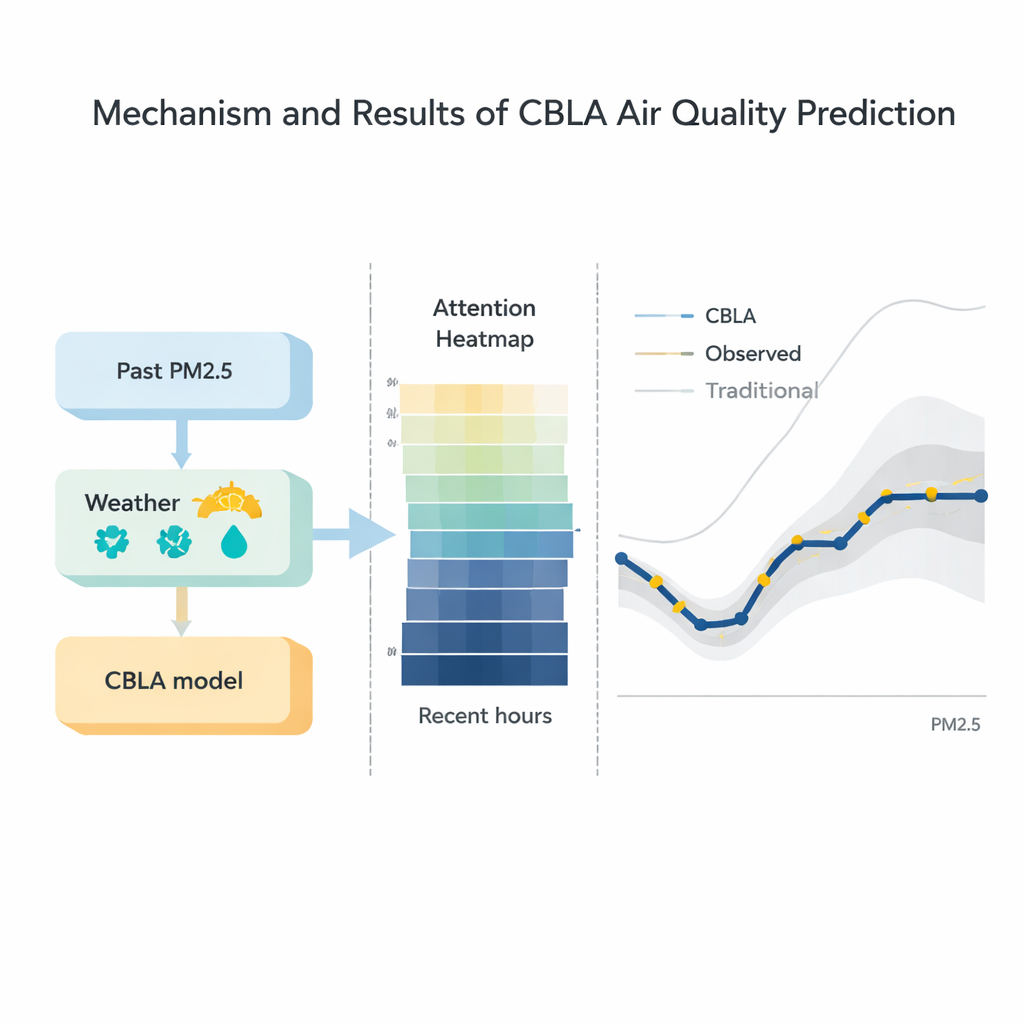
Comparaison avec des modèles concurrents
Les chercheurs ont comparé CBLA avec un large éventail d’alternatives, des techniques classiques comme la régression et les modèles ARIMA aux hybrides d’apprentissage profond sophistiqués combinant réseaux de graphes et transformeurs. Sur trois jeux de données réels, CBLA a systématiquement produit la plus faible erreur moyenne et l’ajustement le plus serré aux niveaux observés de PM2.5. Fait important, il a atteint une précision comparable à celle de certains des modèles modernes les plus avancés tout en ne nécessitant qu’environ un tiers de leur temps d’entraînement sur du matériel standard. Les visualisations du mécanisme d’attention ont révélé que le modèle accorde naturellement le plus de poids aux quelques heures les plus récentes et à des facteurs physiquement significatifs tels que la vitesse du vent et les niveaux passés de PM2.5, offrant un aperçu de la façon dont ses décisions s’alignent sur l’intuition météorologique.
Ce que cela signifie pour la vie quotidienne
En termes pratiques, l’étude montre que la combinaison soignée de plusieurs techniques d’IA peut produire un outil de prévision de la pollution non seulement plus précis, mais aussi plus rapide et plus facile à interpréter. Les gestionnaires urbains pourraient utiliser un tel modèle pour déclencher des avis sanitaires, ajuster des restrictions de circulation ou réduire préventivement les heures d’activité industrielle avant les pics dangereux de smog. Pour les habitants, de meilleures prévisions signifient des conseils plus clairs sur le moment où porter un masque, faire fonctionner des purificateurs d’air ou garder les enfants à l’intérieur. Bien que le travail se concentre sur les villes chinoises et les PM2.5, le même cadre pourrait être adapté à d’autres régions et polluants, ouvrant la voie à un avenir où des prévisions fondées sur les données aideraient des millions de personnes à respirer un peu plus facilement.
Citation: Yin, C., Li, W., Li, T. et al. Air quality prediction model based on deep learning hybrid framework. Sci Rep 16, 7084 (2026). https://doi.org/10.1038/s41598-026-37896-y
Mots-clés: prévision de la qualité de l’air, PM2.5, apprentissage profond, pollution urbaine, météorologie