Clear Sky Science · fr
Une analyse comparative des performances des grands modèles de langage à l’examen de spécialité en odontologie
Pourquoi les chatbots intelligents comptent pour les dentistes de demain
L’intelligence artificielle change rapidement la manière dont médecins et dentistes apprennent et travaillent. L’un des outils les plus visibles est le chatbot conversationnel alimenté par de grands modèles de langage — le même type de technologie derrière de nombreux assistants IA populaires. Cette étude posait une question simple mais importante : si des étudiants en odontologie utilisaient ces outils pour se préparer à un examen de spécialité très compétitif en radiologie orale et maxillo-faciale, quelle serait réellement la performance des machines ?
Évaluer l’IA sur un vrai examen
Pour le savoir, les chercheurs se sont intéressés à l’Examen d’Entrée en Spécialité Dentaire (DUS) en Turquie, qui contribue à déterminer qui peut intégrer des programmes de formation avancée. À partir des sessions précédentes de cet examen national, ils ont sélectionné 208 questions à choix multiple couvrant les sujets que les spécialistes en radiologie doivent maîtriser, de la physique des radiations et des techniques d’imagerie aux tumeurs mandibulaires et aux affections des sinus. La majorité des questions était textuelle, mais un ensemble plus restreint nécessitait l’interprétation d’images radiographiques, reflétant le travail diagnostique réel.
Sept chatbots confrontés au même défi
L’équipe a ensuite soumis chaque question, en turc, à sept chatbots IA largement utilisés reposant sur différents grands modèles de langage : deux versions de ChatGPT, ainsi que Gemini, Copilot, DeepSeek, Claude et Grok. Chaque question a été saisie soigneusement et séparément afin d’éviter tout transfert d’information entre les conversations. Un deuxième chercheur a comparé chaque réponse de l’IA avec la clé officielle et a noté chacune comme correcte ou incorrecte. Enfin, les auteurs ont utilisé des tests statistiques standards pour comparer les modèles globalement et par domaines thématiques.
Qui a obtenu les meilleurs résultats — et où ils ont échoué
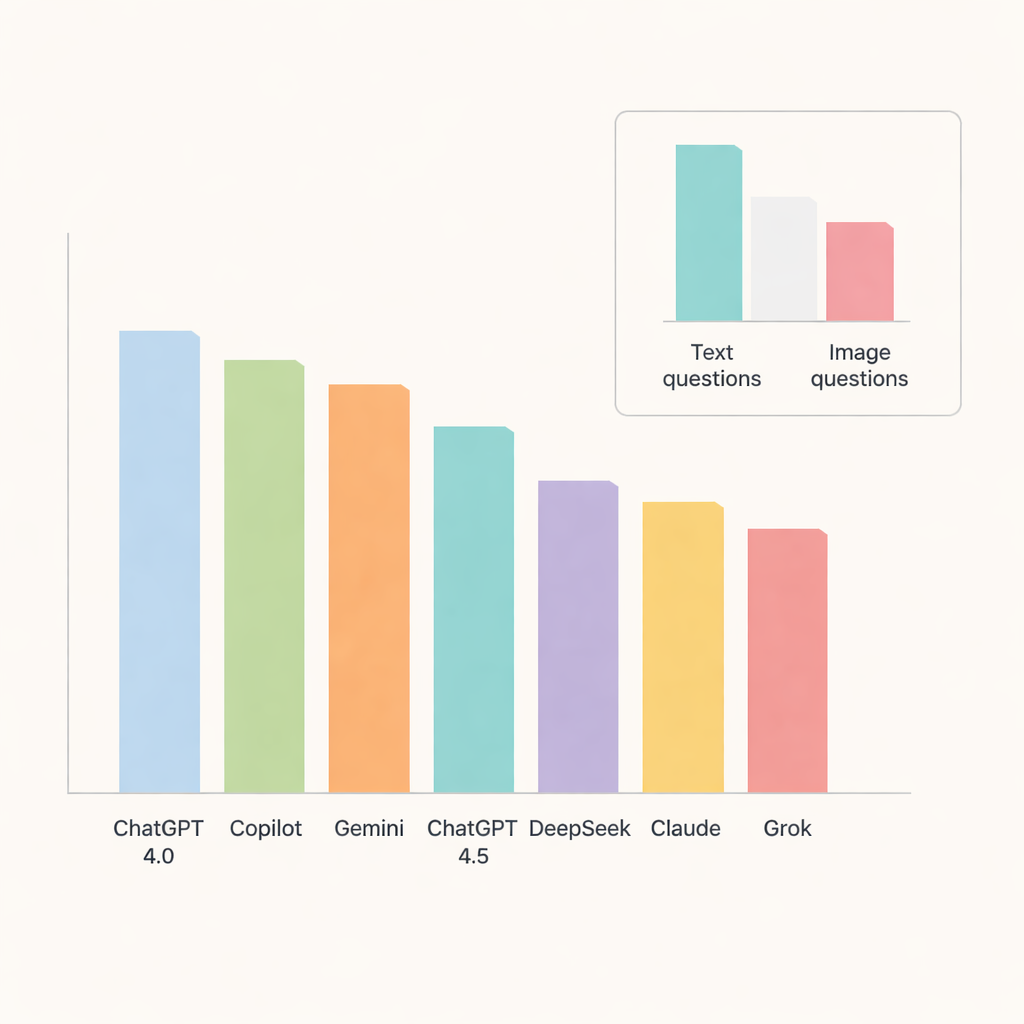
Parmi tous les chatbots, ChatGPT 4.0 se démarque, répondant correctement à environ 91 % des questions. Copilot et Gemini suivent de près avec des précisions autour de la tranche haute des 80 %, tandis que ChatGPT 4.5, DeepSeek, Claude et Grok restent quelque peu en retrait. En examinant les sujets plus en détail, les modèles ont particulièrement bien performé en pathologie orale et maladies des glandes salivaires, où la précision approchait ou dépassait 90 %. En revanche, l’anatomie radiographique et les calcifications des tissus mous se sont révélées nettement plus difficiles, faisant baisser les scores à travers les systèmes et indiquant des domaines où l’IA peine encore à saisir des détails fins.
Les images restent plus difficiles que le texte
Un test clé était de savoir si les chatbots pouvaient traiter les images aussi bien que le texte. Là, leurs limites sont apparues clairement. La précision a chuté nettement sur les questions basées sur des images, même pour les modèles les plus performants. ChatGPT 4.0, Gemini et Copilot ont dominé cette catégorie mais n’ont tout de même répondu correctement qu’à environ deux tiers des questions visuelles. DeepSeek a obtenu les pires résultats sur les images, avec un peu plus d’un tiers de bonnes réponses. Pour la plupart des modèles, la différence de performance entre le texte et l’image était suffisamment importante pour être statistiquement significative, soulignant que l’interprétation des images médicales reste un défi pour l’IA générale d’aujourd’hui.
Ce que cela signifie pour les étudiants et les patients
La conclusion de l’étude est que les chatbots modernes peuvent être des aides puissantes dans la formation dentaire, notamment pour réviser des connaissances et s’entraîner à des questions de type examen en radiologie. Cependant, même les systèmes les plus avancés commettent suffisamment d’erreurs — en particulier sur des sujets exigeant une forte composante visuelle ou très spécialisés — pour ne pas pouvoir remplacer en toute sécurité le jugement d’un expert. Pour les étudiants et les cliniciens, ces outils sont à considérer comme des partenaires d’étude intelligents ou des aides à la décision, et non comme des autorités autonomes. Utilisés avec prudence et supervision appropriée, ils peuvent accélérer l’apprentissage et élargir l’accès à des explications de qualité, tandis que la responsabilité finale pour le diagnostic et le traitement reste fermement entre les mains de professionnels formés.
Citation: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Mots-clés: formation dentaire, intelligence artificielle, grands modèles de langage, radiologie orale et maxillo-faciale, examens médicaux