Clear Sky Science · fr
Détection de spam SMS multilingue via augmentation par GAN pour jeux de données déséquilibrés
Pourquoi vos messages texte ont toujours besoin de protection
La plupart d’entre nous partent du principe que les textos indésirables atterriront discrètement dans un dossier spam, mais en coulisses c’est un problème très difficile. Le vrai spam est rare par rapport aux messages quotidiens, et il apparaît de plus en plus souvent en plusieurs langues à la fois. Cet article présente une nouvelle manière de repérer les SMS dangereux en combinant des modèles linguistiques puissants avec un générateur astucieux de « fausses données », afin que les filtres puissent apprendre à partir de bien plus d’exemples de messages malveillants sans mettre votre vie privée en danger.
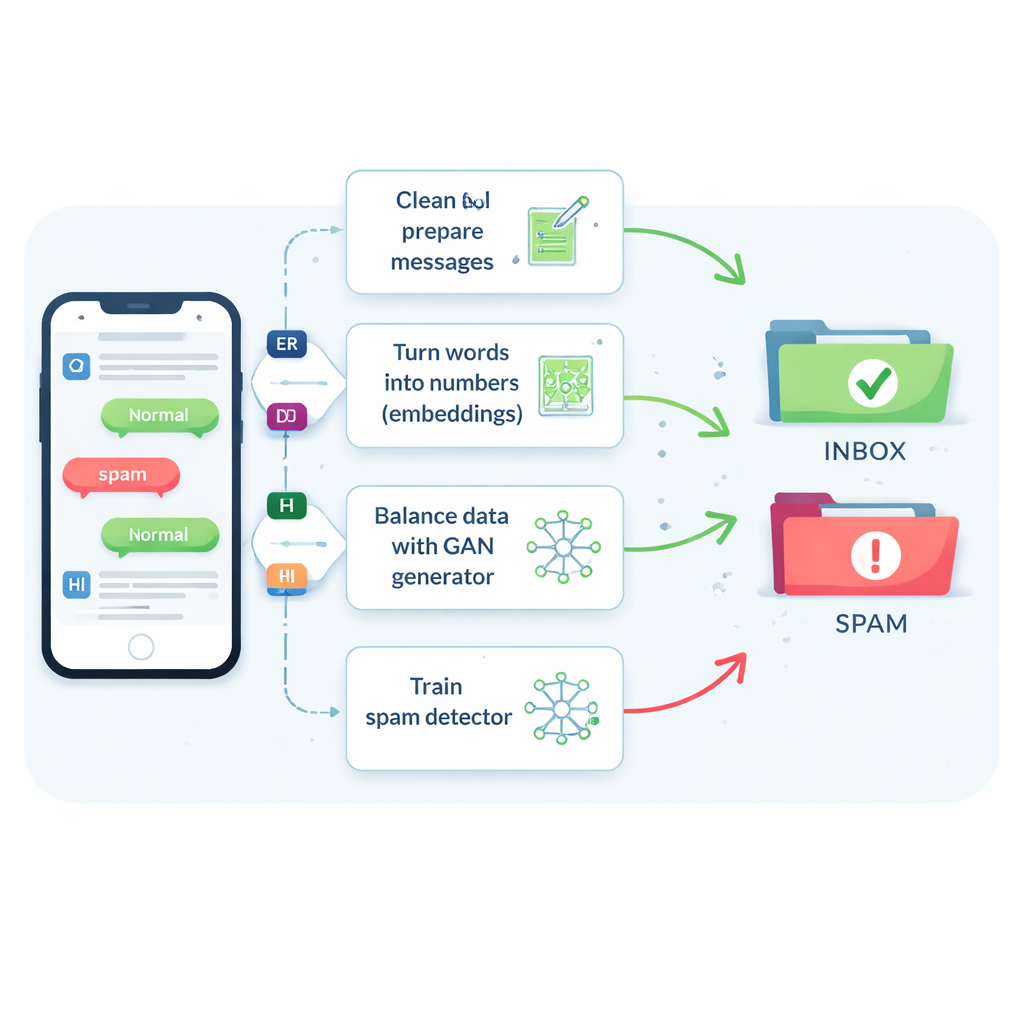
Le problème du spam rare et protéiforme
Les textos de spam représentent seulement environ un message sur sept, et pourtant en manquer une petite fraction peut exposer les personnes à des arnaques, des maliciels et au vol d’identité. Les filtres traditionnels peinent parce que les SMS sont courts, truffés d’argot et d’abréviations, et arrivent en temps réel avec peu de contexte supplémentaire. En conséquence, de nombreux systèmes ont tendance à déclarer les messages sûrs, ce qui satisfait les utilisateurs mais laisse passer des textos plus nocifs. Les vieilles astuces qui se contentent de dupliquer des spams ou d’en inventer de nouveaux en modifiant légèrement les mots peuvent aider un peu, mais elles embrouillent souvent le filtre ou créent des exemples irréalistes qui ne correspondent pas à ce que les criminels envoient réellement.
Apprendre aux machines à comprendre le sens des messages
Les auteurs commencent par comparer huit algorithmes d’apprentissage différents, depuis des outils familiers comme les machines à vecteurs de support et les arbres de décision jusqu’à des réseaux neuronaux plus avancés qui lisent le texte comme une séquence, tels que les réseaux à mémoire long terme (LSTM). Ils testent aussi cinq manières de transformer les mots en nombres exploitables par l’ordinateur. Des comptages simples de la fréquence d’apparition de chaque mot (connus sous le nom de sac de mots ou TF–IDF) sont rapides mais aveugles au sens. Les « embeddings » plus récents comme Word2Vec et GloVe rapprochent numériquement les mots aux significations similaires dans un espace numérique. Les plus avancés sont les modèles basés sur les transformeurs comme BERT, qui adaptent la représentation d’un mot selon la phrase environnante, aidant le système à distinguer, par exemple, un rappel amical d’une arnaque convaincante.
Utiliser un spam « faux » intelligent pour corriger un jeu de données déséquilibré
L’innovation centrale concerne la manière dont l’étude traite la pénurie d’exemples de spam. Plutôt que de générer des phrases entières factices, l’équipe entraîne un type de réseau neuronal appelé réseau antagoniste génératif (GAN) directement sur les embeddings numériques des messages de spam. Une partie du GAN, le générateur, apprend à créer des points synthétiques similaires au spam dans cet espace de haute dimension, tandis qu’une autre partie, le discriminateur, apprend à les distinguer des vrais. Par cette rivalité, le générateur produit de nouveaux embeddings de spam réalistes qui enrichissent l’ensemble d’entraînement. Un contrôle de qualité basé sur la similarité veille à ne conserver que les exemples synthétiques qui ressemblent étroitement au spam authentique, réduisant ainsi le risque de données absurdes susceptibles d’induire en erreur le classificateur.
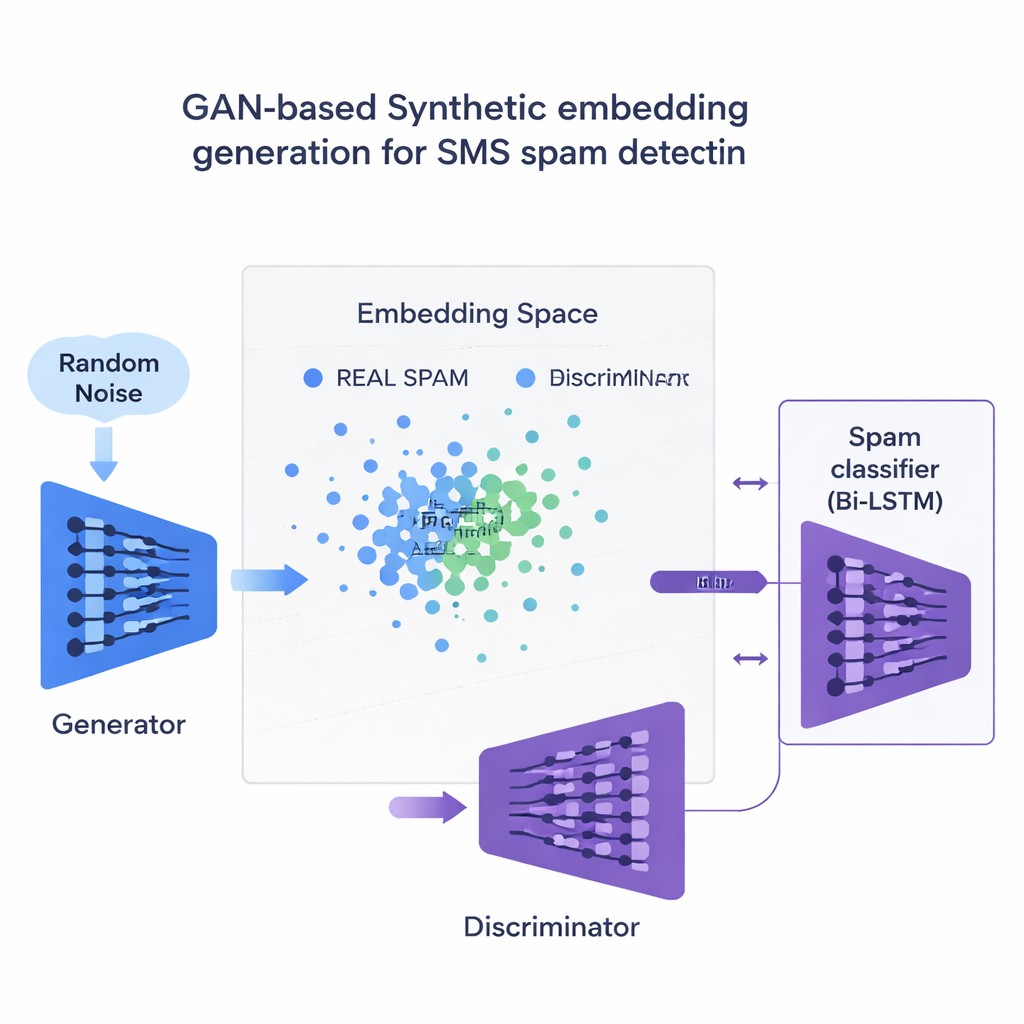
Résultats selon les langues et les appareils
Les chercheurs testent 120 combinaisons différentes de modèles, d’embeddings et de méthodes d’équilibrage des données, à la fois sur un jeu de données SMS en anglais et sur une version multilingue traduite en français, allemand et hindi. De manière générale, les embeddings contextuels comme BERT surpassent les approches plus anciennes basées sur le comptage de mots. La meilleure configuration — un LSTM bidirectionnel alimenté par des embeddings BERT et entraîné avec des exemples de spam générés par GAN — atteint un score F1 d’environ 97,6 % sur les messages en anglais et 94,4 % sur l’ensemble multilingue, dépassant légèrement les systèmes existants à la pointe de la technologie. Surtout, cela se fait tout en maintenant les fausses alertes extrêmement basses, exigence importante pour que les mots de passe à usage unique et les alertes bancaires ne soient pas cachés par erreur aux utilisateurs. L’étude compare également cette stratégie de GAN à des outils d’équilibrage plus courants comme SMOTE et ADASYN, et constate que le GAN produit des données d’entraînement plus propres, plus réalistes et offre des performances globales légèrement supérieures.
Ce que cela signifie pour les utilisateurs quotidiens
Pour les non-spécialistes, la conclusion est que les filtres anti-spam commencent à comprendre le sens et le contexte de vos messages, pas seulement les mots isolés, et peuvent être « entraînés » avec des données synthétiques soigneusement conçues plutôt qu’en accédant à davantage de vos textes réels. En travaillant directement dans l’espace où le sens des messages est encodé, la méthode proposée donne aux systèmes de sécurité une image plus riche de l’apparence du spam dans plusieurs langues, sans les inonder de faux maladroits. Cela augmente la probabilité que les messages dangereux soient détectés et que les messages légitimes soient livrés, offrant une protection plus solide et plus adaptable pour les utilisateurs mobiles à mesure que les arnaqueurs changent de tactiques.
Citation: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Mots-clés: Détection de spam SMS, Augmentation de données par GAN, Incrustations textuelles BERT, Cybersécurité multilingue, Hameçonnage mobile