Clear Sky Science · fr
Une architecture légère de réseau neuronal convolutionnel pour la détection de violences dans des séquences vidéo
Surveiller les foules pour que les humains n’aient pas à le faire
Des concerts et stades aux stations de métro et centres commerciaux, des caméras observent désormais presque tous les espaces fréquentés. Pour autant, la plupart de ces flux vidéo sont encore surveillés par des yeux humains fatigués qui peuvent facilement manquer les premiers signes d’une bagarre ou d’une bousculade. Cet article explore comment une forme d’intelligence artificielle mince et rapide peut analyser des vidéos en direct pour repérer des comportements violents en temps réel, même sur du matériel peu coûteux, aidant ainsi le personnel de sécurité à intervenir rapidement avant que les situations ne dégénèrent.
Pourquoi repérer la violence en vidéo est si difficile
À première vue, demander à un ordinateur de distinguer « bagarre » de « pas de bagarre » paraît simple : détecter des personnes qui se frappent. En réalité, le problème est plus complexe. L’éclairage peut être médiocre ou changer brusquement, la foule peut obstruer la vue et les caméras sont placées selon des angles très variés. Un concert bondé semble chaotique même lorsqu’il n’y a rien de dangereux, tandis qu’un match de boxe paraît violent mais est parfaitement normal dans un ring. Les systèmes de vision traditionnels analysaient des motifs de mouvement et des contours conçus à la main image par image ; bien qu’ils fonctionnent en laboratoire, ils étaient souvent trop lents ou pas assez précis pour des réseaux de surveillance chargés du monde réel.
Un cerveau plus léger pour les flux caméra
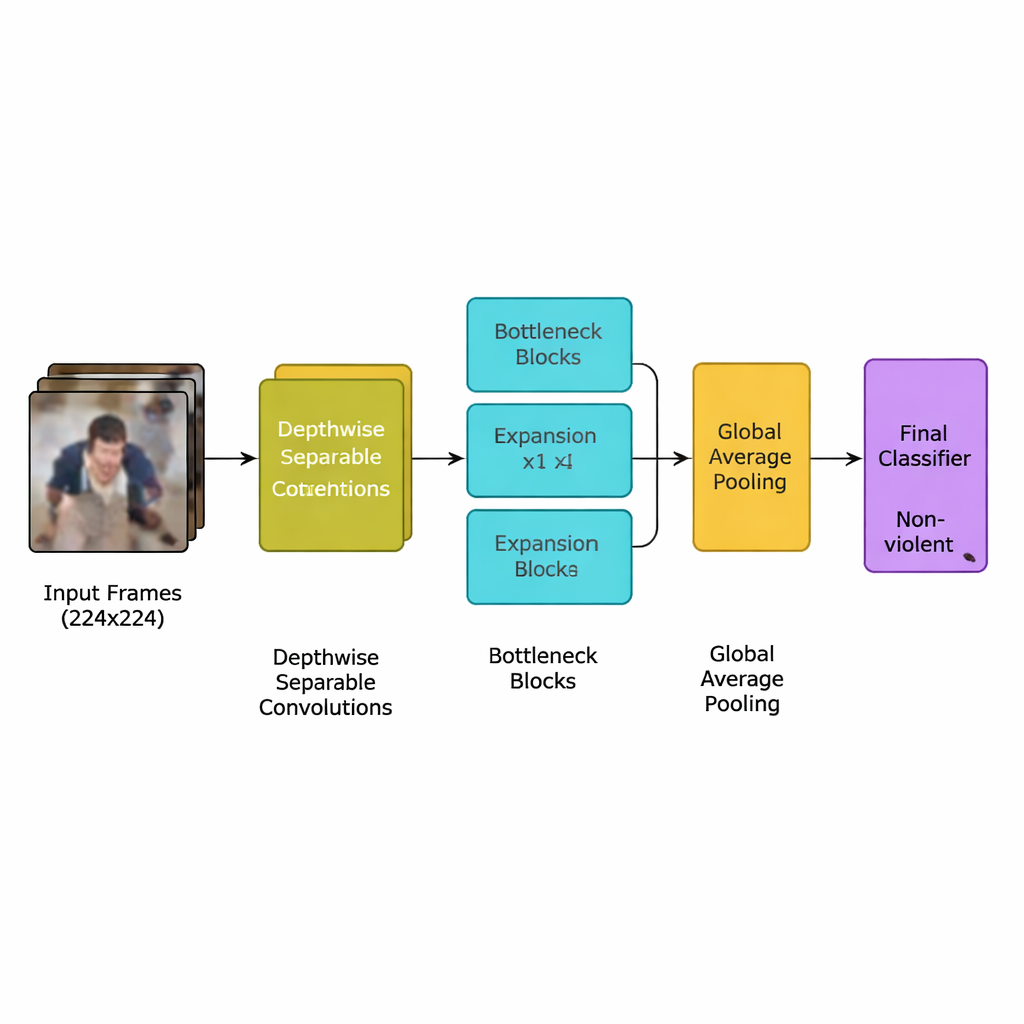
Les auteurs présentent un nouveau modèle d’apprentissage profond conçu spécifiquement pour cette tâche : un réseau neuronal convolutionnel (CNN) léger dérivé d’une famille efficace de modèles connue sous le nom de MobileNetV2. Plutôt que d’utiliser de nombreuses couches lourdes exigeant des processeurs graphiques puissants, le réseau s’appuie sur des convolutions séparables en profondeur — de petits calculs ciblés qui réduisent drastiquement le nombre d’opérations. Il utilise aussi des blocs « goulot d’étranglement inversé » qui élargissent brièvement puis compressent l’information pour préserver les indices de mouvement importants tout en éliminant les redondances. Par-dessus cela, l’équipe ajoute un mécanisme d’attention appelé squeeze‑and‑excitation, qui aide le réseau à se concentrer sur les motifs de mouvement spatio‑temporels les plus typiques des incidents violents, tout en ignorant les détails de fond distrayants.
Du flux brut aux alertes de violence
Le système complet suit un pipeline clair. D’abord, les flux vidéo sont découpés en images (frames), et seule une image sur cinq est conservée pour éliminer les quasi‑doublons tout en préservant les mouvements soudains qui signalent souvent une bagarre. Les images sont redimensionnées à une taille standard de 224×224 pixels, légèrement floutées pour réduire le bruit de fond, puis retournées ou pivotées aléatoirement pendant l’entraînement afin que le modèle apprenne à gérer différents points de vue de caméra. Ces images préparées alimentent le CNN léger, qui convertit progressivement les pixels bruts en motifs de comportement de foule de plus haut niveau. Après une étape finale d’agrégation (pooling) qui résume chaque image, un petit classificateur produit une décision simple : violent ou non‑violent. Parce que le modèle n’utilise qu’environ 1,94 million de paramètres — moins que ses ancêtres MobileNet et MobileNetV2 — il peut s’exécuter en temps réel sur des dispositifs modestes placés près des caméras plutôt que dans un centre de données distant.
Mettre le système à l’épreuve
Pour vérifier si ce design compact pouvait rivaliser avec des réseaux plus volumineux, les chercheurs l’ont entraîné et évalué sur deux jeux de référence largement utilisés. Le Real‑Life Violence Situations Dataset contient 2 000 courts extraits récupérés sur YouTube montrant des scènes quotidiennes et de vraies bagarres dans des lieux variés. Le Hockey Fight Dataset propose 1 000 extraits de matchs de hockey professionnel, partagés entre jeu ordinaire et rixes sur la glace. Sur ces jeux de données, le modèle proposé a correctement étiqueté environ 97 % des clips en situations de la vie réelle et 94 % pour les vidéos de hockey, égalant ou surpassant des CNN plus grands comme InceptionV3 et VGG‑19 tout en utilisant beaucoup moins de calculs. Des tests croisés entre les deux jeux — entraînement sur l’un et test sur l’autre — ont montré que le système conservait des performances raisonnables, ce qui suggère qu’il capture des motifs de mouvement généraux plutôt que de mémoriser un seul environnement.
Ce que cela signifie pour la sécurité au quotidien
Pour les non‑spécialistes, l’idée principale est qu’il est désormais possible de construire des systèmes de caméras qui signalent automatiquement et rapidement les violences probables, à moindre coût et sans avoir besoin de serveurs géants ni d’une surveillance humaine constante. L’étude montre qu’un réseau neuronal soigneusement rogné et ajusté peut surveiller de nombreux flux simultanément, envoyer des alertes lorsqu’il détecte un comportement dangereux et tourner sur du matériel basse consommation adapté aux hubs de transport, écoles, hôpitaux et rues de la ville. Si des défis subsistent — comme gérer des scènes très sombres, des foules denses ou l’intégration d’indices sonores — le travail ouvre la voie à un futur où des caméras intelligentes servent de capteurs d’alerte précoces infatigables, aidant les équipes de sécurité à mieux protéger les personnes tout en réduisant la charge sur les observateurs humains.
Citation: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Mots-clés: détection de violences, surveillance vidéo, CNN léger, MobileNetV2, sûreté publique