Clear Sky Science · fr
Approches spectroscopiques et apprentissage automatique pour le sous-typage clinique de la sclérodermie systémique
Pourquoi un test sanguin pour une maladie rare compte
La sclérodermie systémique est une maladie auto-immune rare qui provoque des cicatrices de la peau et des organes internes, endommageant souvent les poumons et les vaisseaux sanguins. Les médecins ont du mal à prévoir quels patients développeront les formes les plus graves, car les analyses sanguines actuelles ne racontent qu’une partie de l’histoire. Cette étude explore si un test rapide et non invasif, qui fait passer de la lumière infrarouge à travers une goutte de sang, combiné à une analyse informatique, pourrait aider à classer les patients en groupes plus précis et orienter les soins à l’avenir.
À la recherche d’indices cachés dans une goutte de sang
Plutôt que de rechercher une molécule spécifique, les chercheurs ont utilisé une technique appelée spectroscopie infrarouge, qui lit l’« empreinte » combinée de nombreuses substances chimiques présentes dans le sang en une seule fois. Chaque type de molécule — comme les lipides, les protéines et les sucres — absorbe la lumière infrarouge d’une manière légèrement différente. En mesurant ces motifs chez 59 personnes atteintes de sclérodermie systémique, l’équipe a cherché à savoir si la composition chimique globale du sang différait entre deux formes principales de la maladie (diffuse et limitée) et entre les patients avec ou sans cicatrisation pulmonaire, appelée maladie pulmonaire interstitielle.
Différences subtiles dans les lipides et les protéines
Les mesures infrarouges ont révélé une série de pics correspondant aux composants majeurs du sang, y compris les éléments constitutifs des protéines et des lipides (graisses). Lorsque les chercheurs ont moyenné les spectres entre les patients, ils ont observé de faibles mais constantes décalages dans des régions liées à la structure des protéines et aux lipides sanguins — en particulier dans des bandes connues pour refléter le repliement des protéines et l’organisation des molécules grasses. Ces différences apparaissaient en comparant la forme diffuse à la forme limitée, et de manière plus atténuée en comparant les patients avec ou sans atteinte pulmonaire. Cependant, en examinant la taille de pics individuels ou des rapports simples entre pics, les différences n’étaient pas suffisamment fortes pour être statistiquement convaincantes prises isolément.
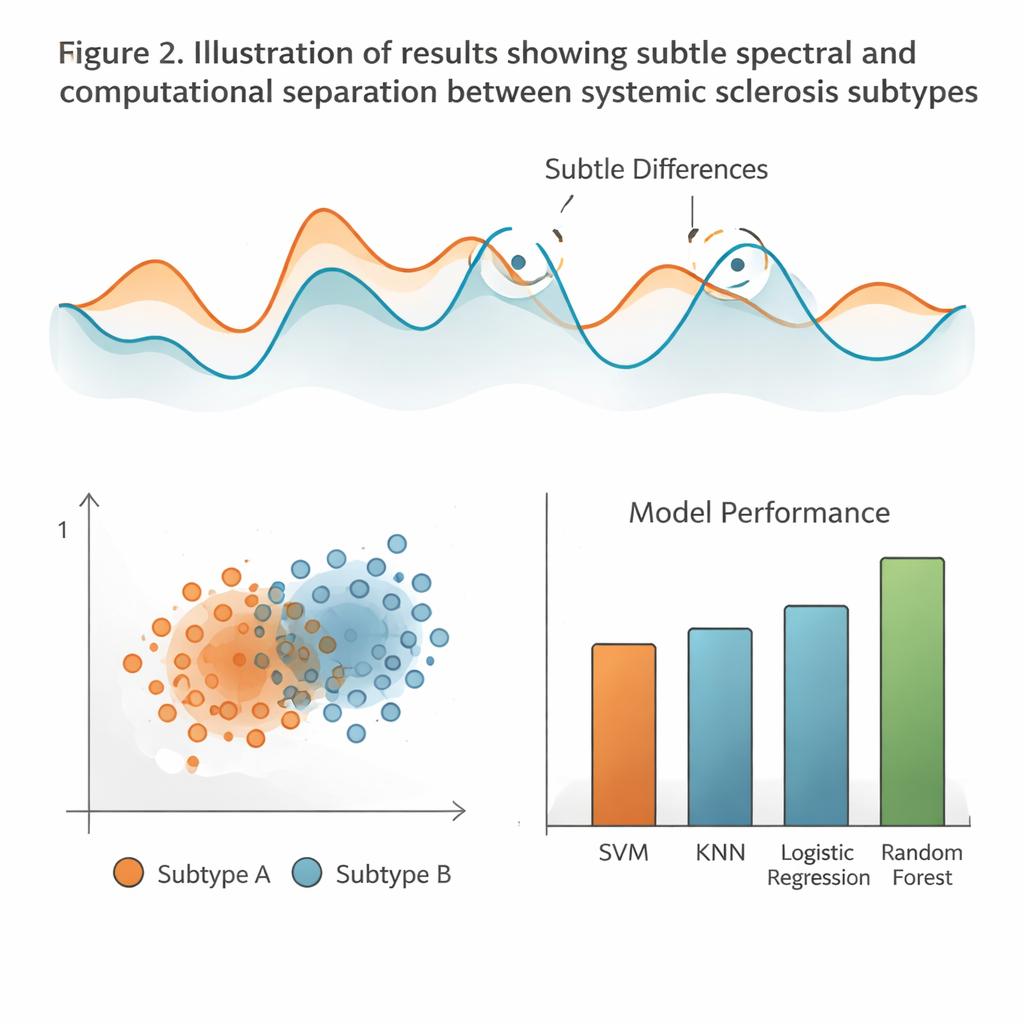
Laisser les ordinateurs trouver des motifs invisibles à l’œil nu
Pour approfondir l’analyse des données, l’équipe s’est tournée vers les statistiques multivariées et l’apprentissage automatique. D’abord, ils ont utilisé une méthode qui compresse des milliers de points de données infrarouges en quelques nouvelles coordonnées capturant la majeure partie de la variation entre les échantillons. Dans cet espace réduit, les échantillons des deux sous-types de la maladie avaient tendance à se regrouper séparément le long de l’axe principal, suggérant une différence biochimique sous-jacente réelle, bien qu’un recouvrement notable subsistât. Ensuite, les chercheurs ont entraîné plusieurs modèles informatiques pour classer les spectres sanguins, notamment des arbres de décision, k plus proches voisins, machines à vecteurs de support, réseaux de neurones et forêts aléatoires. Après un réglage minutieux, ces modèles ont atteint une précision modérée pour distinguer les formes diffuse et limitée, la forêt aléatoire offrant les meilleures performances globales, tandis que les distinctions basées sur la cicatrisation pulmonaire ou d’autres caractéristiques cliniques étaient plus faibles.
Promesses et limites d’un test sanguin émergent
Bien que les modèles d’apprentissage automatique aient fait mieux que le hasard, leur fiabilité et leur capacité à fournir des probabilités robustes n’étaient pas encore suffisantes pour un usage clinique courant. Les résultats ont été affectés par le nombre modeste de patients et par des déséquilibres entre les groupes, qui peuvent amener certains modèles à favoriser le sous-type le plus fréquent. Les auteurs soulignent que de meilleurs prétraitements des spectres, une sélection plus intelligente des régions les plus informatives et des cohortes de patients plus larges et diversifiées sont nécessaires. Ils suggèrent également que combiner les empreintes infrarouges avec d’autres techniques modernes, comme la métabolomique ou le profilage protéique, pourrait affiner le signal.
Ce que cela pourrait signifier pour les patients
Pour les personnes vivant avec une sclérodermie systémique, ce travail ne change pas immédiatement le diagnostic ou le traitement, mais il ouvre la voie à un avenir où un test sanguin simple et peu coûteux pourrait aider les médecins à classer les patients en sous-groupes biologiquement pertinents et à détecter précocement des signes d’atteinte pulmonaire. L’étude montre que la signature chimique globale du sang porte des informations sur le comportement de la maladie, et que des algorithmes intelligents peuvent commencer à lire cette signature. Avec des améliorations et des études à plus grande échelle, cette approche pourrait devenir un complément utile aux tests existants, améliorant l’évaluation du risque et guidant des soins plus personnalisés.
Citation: Miziołek, B., Miszczyk, J., Paja, W. et al. Spectroscopic and machine learning approaches for clinical subtyping in systemic sclerosis. Sci Rep 16, 6929 (2026). https://doi.org/10.1038/s41598-026-37690-w
Mots-clés: sclérodermie systémique, spectroscopie infrarouge, biomarqueurs sanguins, apprentissage automatique, maladie pulmonaire interstitielle