Clear Sky Science · fr
MSRCTNet : un nouveau réseau de triplets capsules multi‑échelle pour l’élimination efficace des images redondantes dans les vidéos d’endoscopie capsulaire sans fil
Avaler une caméra, se noyer dans les images
Imaginez diagnostiquer des maladies digestives en avalant une caméra de la taille d’une vitamine qui photographie silencieusement l’ensemble de votre tube digestif. L’endoscopie capsulaire sans fil rend déjà cela possible, mais chaque examen produit environ 55 000 images, dont la plupart se ressemblent presque. Les médecins doivent parcourir ce flot visuel pour repérer de petites zones de saignement, d’inflammation ou des tumeurs. L’étude derrière MSRCTNet pose une question simple mais cruciale : un système intelligent peut‑il éliminer en toute sécurité les images quasi identiques, pour que les médecins ne voient que ce qui compte vraiment ?
Pourquoi trop d’images peut poser problème
L’endoscopie conventionnelle nécessite un tube flexible introduit par la bouche ou le rectum, une procédure que beaucoup de patients trouvent désagréable et qui n’atteint pas toujours l’ensemble de l’intestin grêle. L’endoscopie capsulaire résout cela en laissant une pilule‑caméra dériver dans l’intestin et prendre des photos chaque seconde. L’inconvénient est la surcharge : seulement environ 1 % des images contiennent une information clairement utile, tandis que le reste répète majoritairement les mêmes replis de tissu. Examiner de tels volumes est lent et fatigant, ce qui augmente le risque qu’un clinicien épuisé manque une lésion subtile. Les méthodes informatiques antérieures tentaient d’aider en regroupant les images similaires, en compressant les données ou en s’appuyant sur des indices simples de couleur et de texture, mais elles échouaient souvent quand l’éclairage changeait, que l’intestin bougeait de façon complexe ou que des anomalies rares n’apparaissaient que dans quelques exemples.
Une façon plus intelligente de repérer la répétition
MSRCTNet (Multi‑Scale Capsule Triplet Network) est un système d’apprentissage profond conçu pour fonctionner comme un filtre intelligent pour les vidéos capsulaires. Plutôt que de traiter chaque image comme une simple surface plate, le système analyse simultanément des motifs à plusieurs échelles — les textures fines de la muqueuse et les formes plus larges de la paroi intestinale — tout en utilisant un mécanisme d’attention pour mettre en valeur les détails les plus informatifs. Ces descripteurs enrichis sont ensuite transmis à une couche de type capsule qui préserve la façon dont les parties de l’image se rapportent spatialement les unes aux autres, par exemple l’orientation et l’agencement des replis ou des lésions. Enfin, un module de similarité spécialisé compare des triplets d’images — une image de référence, une qui devrait être similaire et une qui devrait être différente — afin d’apprendre une représentation où les images réellement redondantes forment des grappes serrées et les images distinctives se détachent.
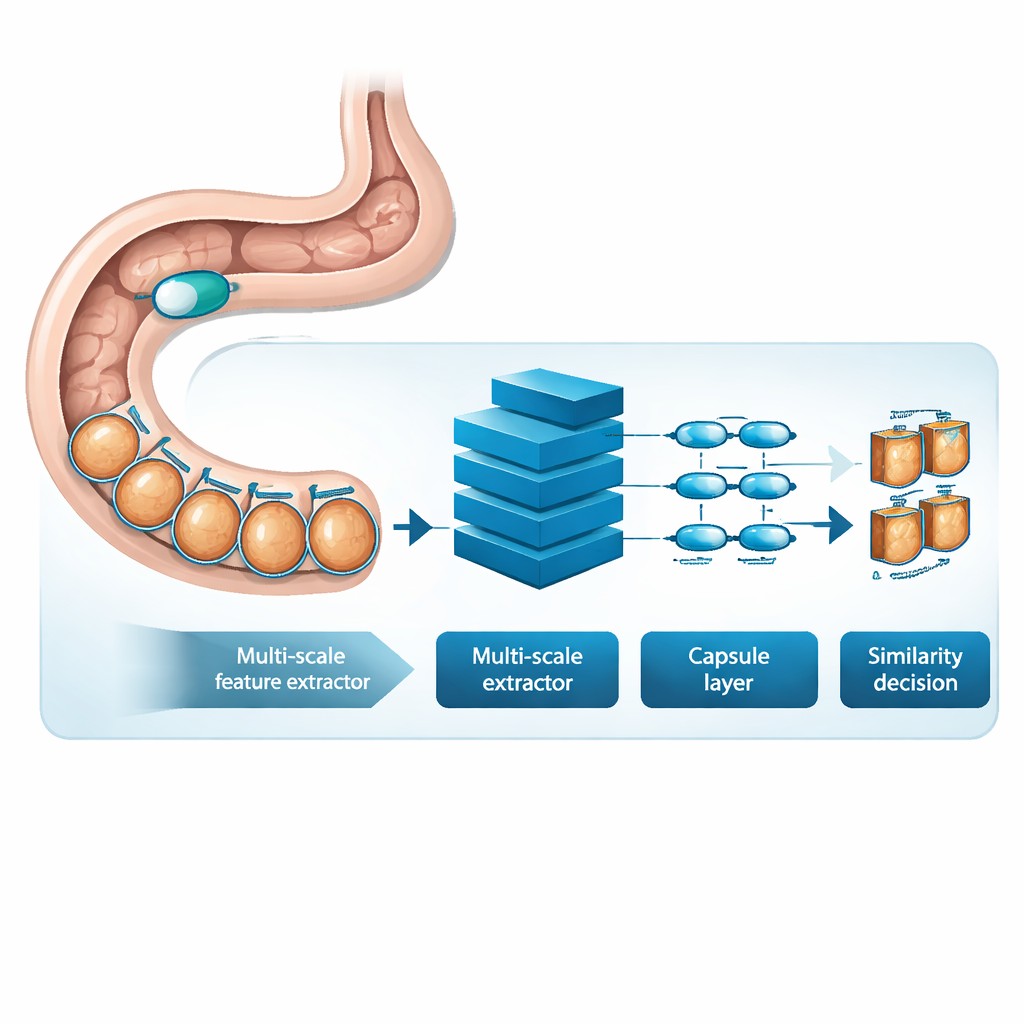
Apprendre à partir d’examens patients réels
Pour tester MSRCTNet, les chercheurs ont rassemblé un large jeu de données de 257 362 images provenant de 60 examens par capsule réalisés dans un hôpital en Chine. Les images comprenaient du tissu normal, des régions obscurcies par des bulles et des anomalies nettes comme des saignements et des inflammations, toutes étiquetées par des cliniciens expérimentés. Le système a été entraîné à juger si des paires d’images étaient similaires ou non, en combinant deux objectifs d’apprentissage : l’un qui rapproche les images d’une même catégorie et écarte celles de catégories différentes, et un autre qui apprend au réseau à indiquer directement si une paire est similaire. Une fois entraîné, le modèle parcourt une vidéo trois images à la fois et décide lesquelles des images voisines sont réellement redondantes. En appliquant des règles simples à ces décisions de similarité, il élimine les vues répétées tout en conservant des images clés représentatives.
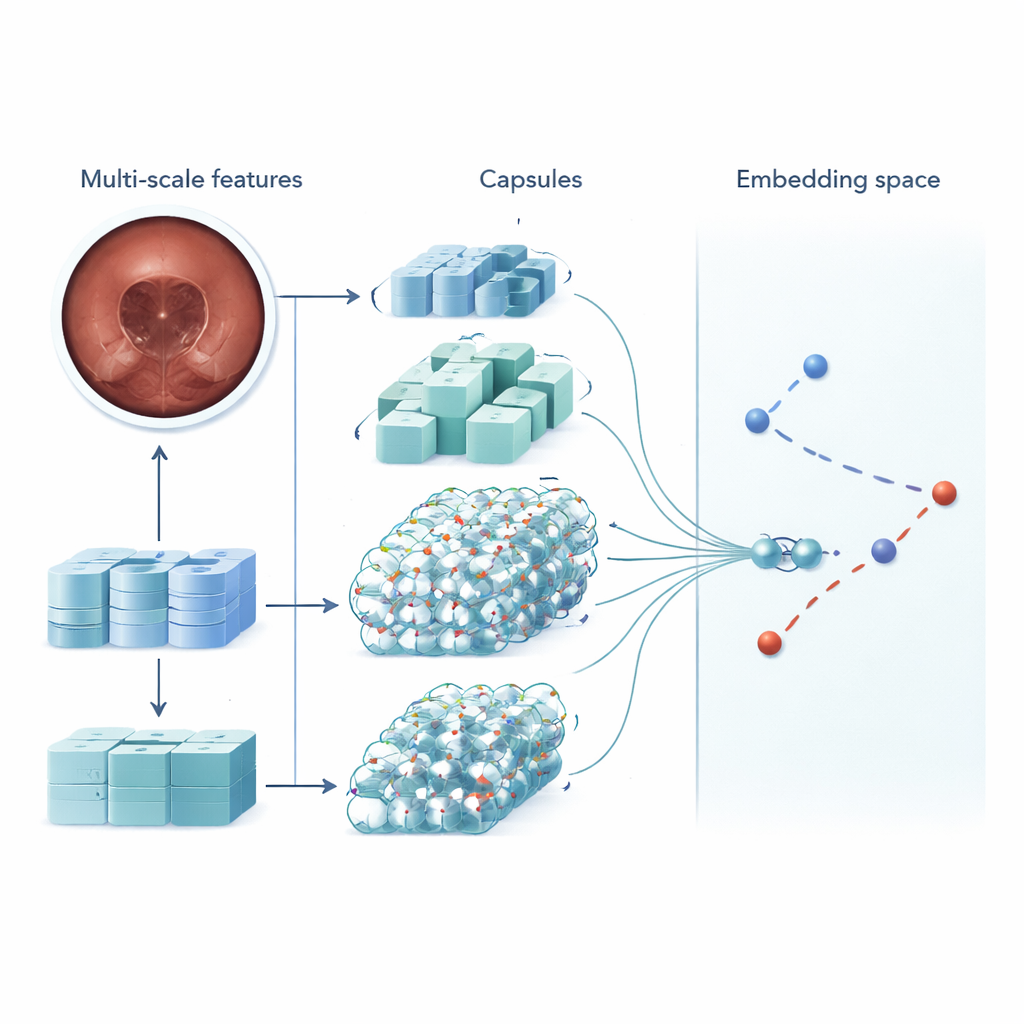
Vitesse, précision et moins de problèmes manqués
Sur les données de test, MSRCTNet a correctement géré la redondance d’images dans environ 96 % des cas, avec un taux de fausses alertes inférieur à 3 % et un taux d’images manquées inférieur à 0,2 %. En pratique, pour un examen de 50 000 images, cela correspond à manquer moins de 100 images potentiellement pertinentes — un nombre suffisamment faible pour que les images environnantes fournissent encore du contexte à six images par seconde. Comparé à plusieurs techniques antérieures basées sur le regroupement, l’analyse de mouvement ou des réseaux neuronaux plus simples, MSRCTNet s’est montré à la fois plus précis et plus robuste lorsque les données étaient déséquilibrées, c’est‑à‑dire quand les images normales l’emportaient largement sur les rares lésions. Le système fonctionnait aussi rapidement : environ 0,02 seconde par image, soit près de 15 minutes pour réduire un examen complet à environ 2 500 images clés, un volume bien plus maniable pour la relecture humaine.
Ce que cela signifie pour les patients et les médecins
Pour les patients, l’avancée décrite dans cet article ne change pas la capsule qu’ils avalent, mais elle pourrait rendre leur examen plus efficace. En éliminant automatiquement les images presque identiques sans seuils réglés à la main ni heuristiques fragiles, MSRCTNet permet aux cliniciens de concentrer leur attention sur un résumé concis et riche en informations du parcours à travers le tube digestif. L’approche préserve les constatations cliniquement importantes tout en réduisant la fatigue et le temps passé devant la console de lecture, ce qui pourrait rendre les examens capsulaires non invasifs plus attrayants et plus largement utilisés. En substance, la méthode transforme un torrent d’images en une sélection soigneusement organisée, rapprochant la promesse de l’intelligence artificielle d’une prise en charge quotidienne des maladies digestives.
Citation: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Mots-clés: endoscopie capsulaire sans fil, résumé vidéo médical, apprentissage profond, élimination des images redondantes, imagerie gastro‑intestinale