Clear Sky Science · fr
Optimisation des hyperparamètres pour améliorer les performances des modèles d’apprentissage profond pour la détection précoce des tortues invasives en Corée
Pourquoi repérer les tortues de façon plus intelligente est important
Les tortues d’eau douce peuvent sembler inoffensives en train de prendre le soleil sur un rocher, mais lorsque des espèces non indigènes envahissent rivières et étangs, elles peuvent pousser silencieusement la faune locale vers l’extinction. La Corée est aujourd’hui confrontée à ce problème avec plusieurs espèces de tortues invasives qui se propagent via le commerce et les lâchers depuis le marché des animaux de compagnie. L’étude résumée ici montre comment l’affinage de l’intelligence artificielle — et plus précisément des modèles d’apprentissage profond — peut rendre la détection automatique des tortues plus rapide et plus précise, offrant aux conservateurs un nouvel outil puissant d’alerte précoce avant que les écosystèmes ne soient irréversiblement endommagés.
Des invités indésirables dans les eaux locales
Des tortues invasives comme la tortue à oreilles rouges ont été introduites dans toute l’Asie par le commerce mondial d’animaux sauvages. Une fois relâchées, elles entrent en compétition avec les espèces natives pour la nourriture et les sites de repos, peuvent propager des maladies et s’adaptent souvent mieux aux températures en hausse que les espèces locales. La Corée classe six espèces de tortues d’eau douce comme invasives ou à haut risque. Les repérer tôt est essentiel, mais la surveillance traditionnelle dépend d’experts visitant de nombreux zones humides et vérifiant ensuite attentivement des photographies — un travail précis mais lent et limité en portée. À mesure que les drones, les pièges photographiques et les plateformes de science participative comme iNaturalist produisent toujours plus d’images, l’analyse d’images automatique devient indispensable pour suivre le rythme.
Apprendre aux ordinateurs à reconnaître les tortues
Les chercheurs se sont donné pour objectif de construire un modèle d’apprentissage profond capable à la fois de localiser les tortues invasives dans les photos et de distinguer les six espèces. Ils ont rassemblé des milliers d’images issues de la science participative sur iNaturalist et ont soigneusement revérifié chacune d’elles, supprimant les mauvaises identifications et les clichés de faible qualité. Pour chaque image exploitable, ils ont tracé un encadré autour de chaque tortue afin que le modèle puisse apprendre où apparaissent les tortues et à quoi elles ressemblent. Le jeu de données final a été divisé en ensembles d’entraînement, de validation et de test, et comprenait des éclairages, des arrière‑plans et des angles de vue variés pour garantir que le modèle soit robuste aux conditions du monde réel.
Trouver la meilleure façon d’entraîner le modèle
L’équipe a utilisé un cadre populaire de détection d’objets appelé YOLO11, en choisissant une version compacte qui équilibre rapidité et précision. Mais au lieu d’accepter les paramètres d’entraînement par défaut du logiciel — initialement réglés sur des objets du quotidien comme des voitures et des tasses — ils se sont posé une question simple : peut‑on faire mieux pour les tortues ? D’abord, ils ont comparé six « optimisateurs » différents, ces routines qui ajustent les poids internes du modèle pendant l’apprentissage. Deux d’entre eux ont mal performé ou sont devenus instables, tandis qu’une méthode classique appelée descente de gradient stochastique (SGD) a apporté les améliorations les plus fiables et les meilleurs scores sur un ensemble d’images mis de côté.
Avec le meilleur optimiseur choisi, les chercheurs se sont ensuite attaqués à 16 paramètres d’entraînement, ou hyperparamètres. Ceux‑ci contrôlent la vitesse d’apprentissage, la force contre le surapprentissage et la manière dont les images sont altérées aléatoirement pendant l’entraînement pour améliorer la généralisation. En utilisant une stratégie de recherche aléatoire — testant 300 combinaisons différentes échantillonnées dans des plages raisonnables — ils ont recherché une configuration maximisant les performances globales de détection et de classification. Des réglages clés ont évolué de manière notable : l’importance d’obtenir l’étiquette d’espèce correcte a été augmentée, la régularisation renforcée pour réduire le surapprentissage, les variations de luminosité dans l’augmentation des données ont été atténuées, et une technique complexe de mélange d’images a été moins utilisée pour que les images artificielles restent plus proches des photographies réelles.
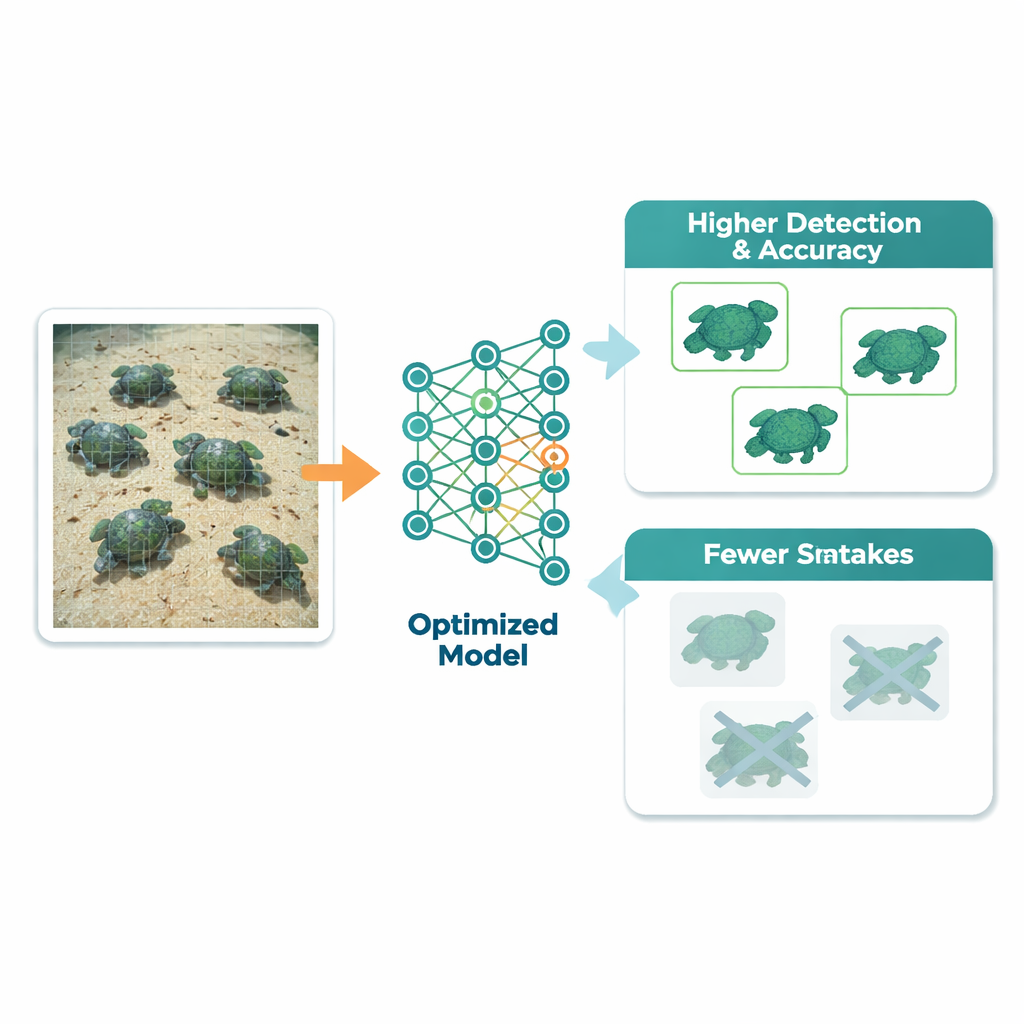
Des yeux plus aiguisés, moins de confusions
Au final, le modèle optimisé a clairement surpassé une version entraînée avec les valeurs par défaut standard. Pour mesurer la capacité du système à trouver et à étiqueter correctement les tortues, l’étude a utilisé un score appelé moyenne des précisions (mean average precision). À un seuil de correspondance couramment utilisé, ce score est passé de 0,959 à 0,973, et sur une plage de seuils plus exigeante il a grimpé de 0,815 à 0,841. L’exactitude globale de classification au niveau des espèces est passée de 89,9 % à 92,7 %. Particulièrement notable est la réduction des confusions entre espèces qui se ressemblent : par exemple, une tortue souvent interprétée comme une autre dans le modèle par défaut a été bien plus fréquemment identifiée correctement après l’ajustement. Ces gains ont été obtenus avec presque aucun surcoût de temps d’entraînement et seulement un léger ralentissement lors du traitement de nouvelles images.
Ce que cela signifie pour la protection de la faune
Pour un non‑spécialiste, ces chiffres signifient que les ordinateurs deviennent sensiblement meilleurs pour repérer les bonnes tortues dans des images encombrées et du monde réel, et pour différencier des espèces difficiles à distinguer. En choisissant soigneusement la manière dont le modèle apprend — plutôt qu’en se reposant sur des réglages génériques — les auteurs montrent que les systèmes de détection précoce des espèces invasives peuvent gagner en précision sans collecter de nouvelles données ni développer entièrement de nouveaux algorithmes. Déployés sur des pièges photographiques, des drones ou des flux de photos issus de la science participative, de tels modèles optimisés pourraient alerter les gestionnaires plus tôt lorsqu’une tortue invasive apparaît ou se propage, contribuant à protéger la faune native et la santé des écosystèmes d’eau douce.
Citation: Baek, JW., Kim, JI., Mun, MH. et al. Hyperparameter optimization to enhance the performance of deep learning models for the early detection of invasive turtles in Korea. Sci Rep 16, 7561 (2026). https://doi.org/10.1038/s41598-026-37636-2
Mots-clés: tortues invasives, apprentissage profond, surveillance de la faune, optimisation des hyperparamètres, conservation de la biodiversité