Clear Sky Science · fr
Modélisation longitudinale de l’état post‑COVID‑19 sur trois ans : une approche par apprentissage automatique utilisant des marqueurs cliniques, neuropsychologiques et fluides
Pourquoi les symptômes persistants du COVID restent importants
Des millions de personnes dans le monde continuent de se sentir mal des mois voire des années après une infection par le COVID‑19. Cette affection, souvent appelée COVID long ou état post‑COVID‑19, peut provoquer une fatigue accablante, un « brouillard cérébral », des troubles du sommeil et d’autres symptômes difficiles à objectiver avec des tests médicaux classiques. L’étude décrite ici a suivi un groupe d’adultes pendant trois ans après l’infection et a utilisé des techniques informatiques modernes pour explorer leurs analyses sanguines, bilans cliniques et tests cognitifs afin d’identifier des motifs révélant comment le COVID long évolue dans le temps et quelles mesures suivent le mieux la guérison ou la persistance de la maladie.
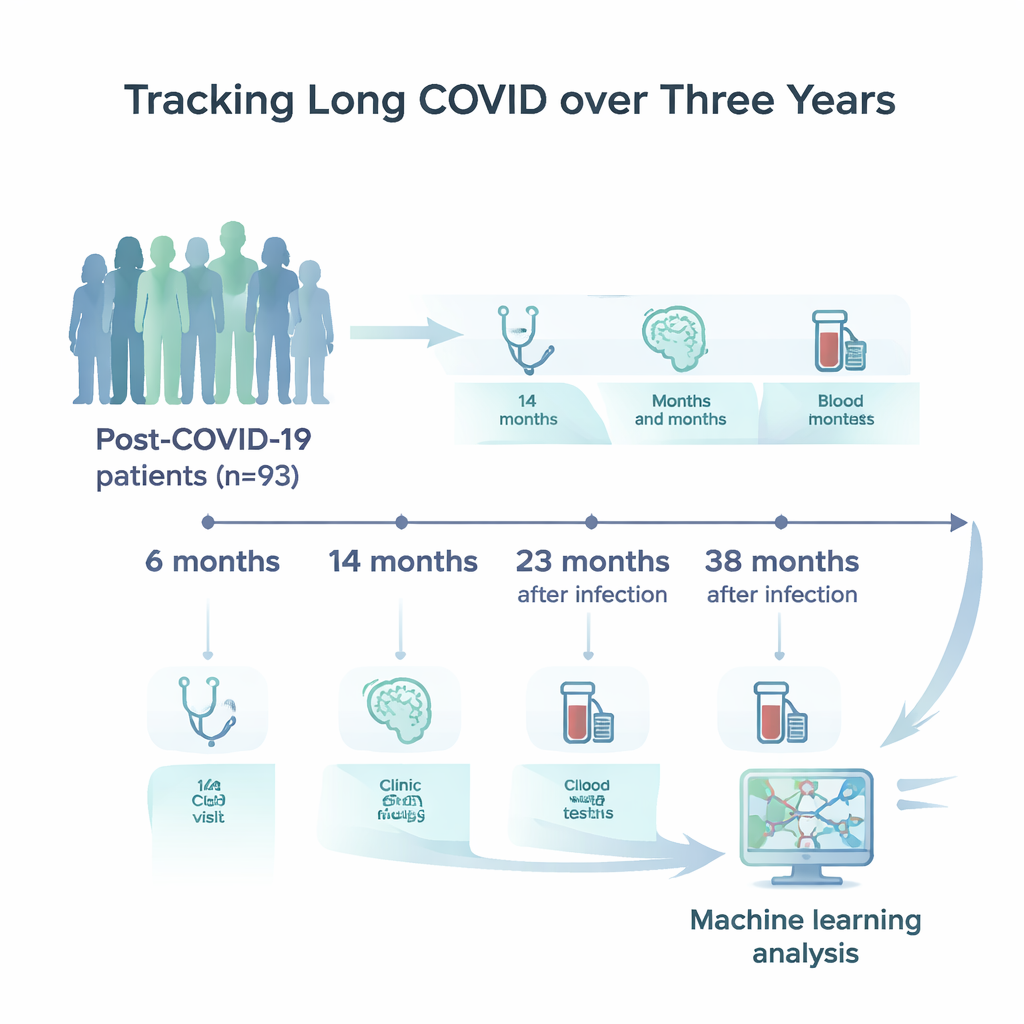
Suivre les patients sur le long terme
Des chercheurs en Allemagne ont recruté 93 adultes ayant une infection confirmée à SARS‑CoV‑2 et des plaintes neurologiques ou neuropsychologiques persistantes. Ces participants, majoritairement d’âge moyen, ont été examinés à quatre reprises : environ 6, 14, 23 et 38 mois après l’infection initiale. À chaque visite, ils ont rempli des questionnaires détaillés sur la fatigue, l’humeur et le sommeil ; ont passé des tests courts et plus complets d’attention, de mémoire et de vitesse mentale ; et ont fourni des échantillons sanguins pour un large panel d’analyses. Celles‑ci comprenaient des marqueurs de santé standard, des signaux d’inflammation, des mesures de l’activité immunitaire et des protéines spécialisées libérées lors de lésions des cellules cérébrales.
Laisser les ordinateurs découvrir les motifs cachés
Plutôt que d’examiner un symptôme ou une analyse à la fois, l’équipe a eu recours à l’apprentissage automatique, une branche de l’intelligence artificielle capable d’analyser simultanément de nombreuses variables et de repérer des relations subtiles. Ils ont entraîné plusieurs modèles informatiques pour répondre à une question précise : à partir des données combinées d’une consultation, l’algorithme peut‑il déterminer de quelle année de suivi provient cette visite ? Autrement dit, le profil d’une personne à 6 mois est‑il suffisamment différent de son profil à 2 ou 3 ans pour être identifié ? Les chercheurs ont traité soigneusement les valeurs manquantes, utilisé la validation croisée pour éviter le sur‑apprentissage sur un petit échantillon, et comparé différentes familles de modèles, des arbres de décision simples aux méthodes de gradient boosting plus sophistiquées.
Quels signaux disent le temps le mieux
Les modèles ont obtenu des performances remarquables. Lorsqu’ils comparaient des visites éloignées dans le temps — par exemple la première et la quatrième visite — certains algorithmes ont correctement attribué l’année dans bien plus de 90 % des cas. Même entre des points temporels plus proches, la précision restait élevée, baissant seulement légèrement entre la troisième et la quatrième visite, ce qui suggère que le profil des patients change plus lentement aux stades ultérieurs. Les méthodes les plus performantes étaient des modèles de gradient boosting basés sur des arbres, qui excellent à détecter des relations non linéaires. Pour ouvrir la « boîte noire » et comprendre ce qui motivait ces décisions, l’équipe a utilisé des outils d’explicabilité appelés SHAP et LIME qui classent les caractéristiques qui poussent une prédiction dans un sens ou dans l’autre.
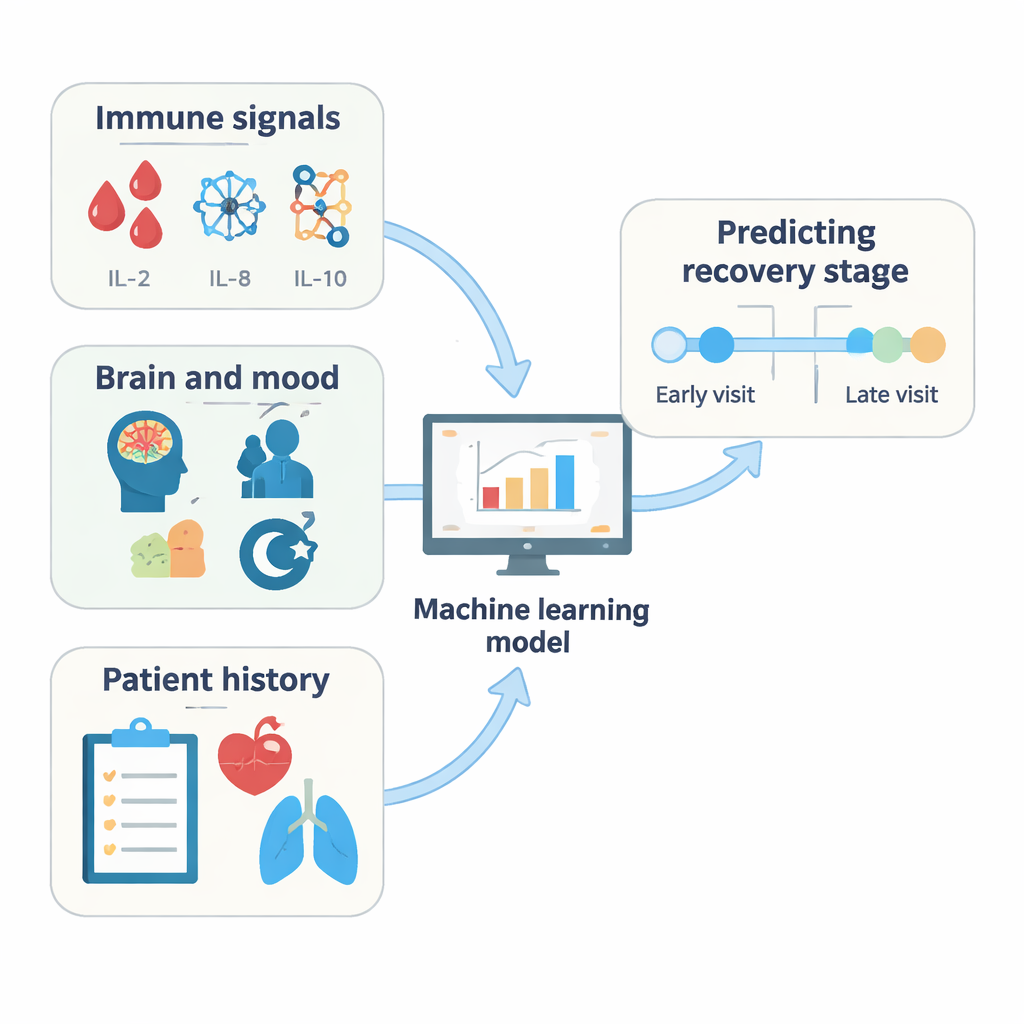
Indices immunitaires, brouillard cérébral et importance changeante
À travers plusieurs analyses, un tableau cohérent est apparu. Les niveaux de molécules inflammatoires dans le sang — en particulier certaines interleukines comme IL‑2, IL‑8 et IL‑10 — figuraient parmi les indices les plus puissants pour distinguer les premiers des suivis ultérieurs. Les mesures de la réponse en anticorps contre le virus, en particulier les anticorps ciblant la protéine spike (qui reflètent aussi la vaccination au fil du temps), étaient également des indicateurs forts. Du côté cognitif, les tests de mémoire verbale et de recherche de mots, ainsi que les scores liés à la fatigue et à la somnolence, apportaient des informations importantes, surtout aux stades précoces après l’infection. Avec le temps, les marqueurs immunitaires ont eu tendance à gagner en poids dans les modèles, tandis que certaines mesures neuropsychologiques devenaient moins centrales, suggérant que les moteurs biologiques du COVID long peuvent évoluer au fil des années.
Ce que cela signifie pour les patients et la prise en charge
Pour les non‑spécialistes, le message clé est que le COVID long n’est pas seulement un ensemble vague de plaintes. Lorsqu’on le suit attentivement sur plusieurs années, des signaux objectifs dans le sang et dans les tests cognitifs évoluent de façon identifiable par des algorithmes. Cette étude suggère qu’une combinaison de marqueurs immunitaires, de niveaux d’anticorps et d’évaluations ciblées de la cognition et de la fatigue pourrait aider les médecins à surveiller qui se rétablit, qui reste à risque de complications durables et quels patients pourraient bénéficier en priorité de traitements émergents centrés sur le système immunitaire. Bien que des études plus larges et complémentaires soient nécessaires avant que ces outils n’entrent dans la pratique courante, ce travail illustre comment l’intelligence artificielle peut contribuer à transformer la réalité complexe du COVID long en informations plus nettes et exploitables pour les patients et les cliniciens.
Citation: Walders, J., Wetz, S., Costa, A.S. et al. Longitudinal modeling of Post-COVID-19 condition over three years: A machine learning approach using clinical, neuropsychological, and fluid markers. Sci Rep 16, 6517 (2026). https://doi.org/10.1038/s41598-026-37635-3
Mots-clés: COVID long, apprentissage automatique, inflammation, symptômes cognitifs, biomarqueurs immunitaires