Clear Sky Science · fr
Empreinte DNS basée sur l’activité des utilisateurs
Pourquoi vos visites web laissent une trace cachée
Chaque fois que vous naviguez sur le web, votre ordinateur interroge discrètement un annuaire particulier, appelé Système de Noms de Domaine (DNS), pour savoir comment atteindre chaque site. Ces requêtes ne disparaissent pas. Sur des jours et des semaines, elles forment un motif indiquant quels types de sites vous visitez, quand et à quelle fréquence. Cet article montre que ces motifs sont suffisamment distinctifs pour agir comme une empreinte comportementale, permettant à des algorithmes puissants de différencier des utilisateurs—même si leur adresse IP visible change—ce qui ouvre des possibilités pour la sécurité mais soulève aussi de sérieuses questions de vie privée.
L’annuaire d’Internet et vos habitudes
Le DNS sert à traduire des adresses web lisibles par l’humain, comme www.google.com, en adresses IP numériques que les ordinateurs utilisent pour communiquer. La plupart des gens n’y pensent jamais, mais chaque recherche, flux vidéo, vérification d’e‑mail ou mise à jour d’application déclenche une ou plusieurs requêtes DNS. Ces requêtes sont généralement traitées par des serveurs DNS locaux ou publics et consignées sous forme d’enregistrements simples : quelle adresse IP a demandé quel domaine, et quand. En regroupant suffisamment de ces enregistrements, on obtient une image détaillée des services en ligne sur lesquels un utilisateur s’appuie, depuis les outils professionnels et le stockage cloud jusqu’aux réseaux sociaux et aux plateformes de streaming. Alors que des travaux antérieurs exploitaient ces traces pour détecter des logiciels malveillants ou identifier des types d’appareils, cette étude pose une question plus directe : peuvent‑elles identifier des utilisateurs ou des machines uniquement à partir de leur comportement DNS récurrent ?
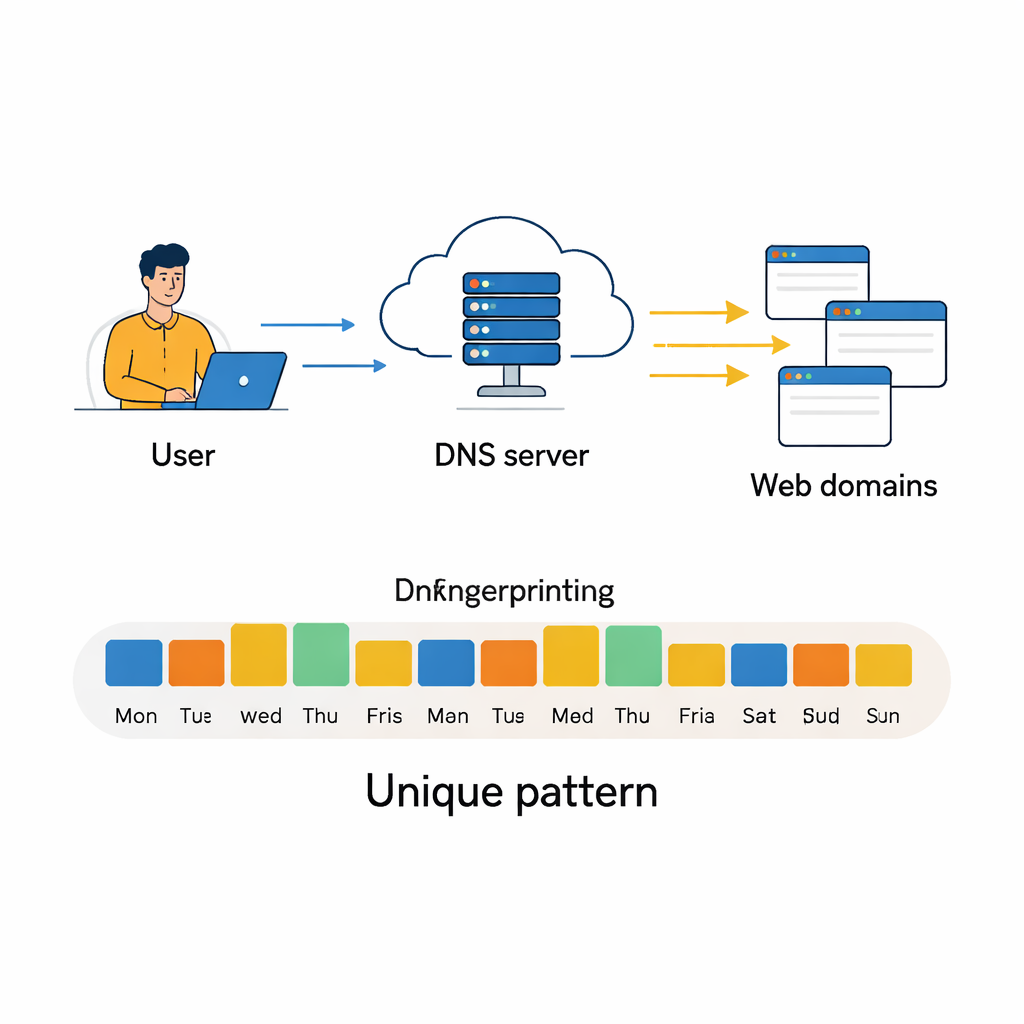
Transformer des clics quotidiens en empreinte comportementale
Les auteurs s’appuient sur un grand jeu de données DNS accessible publiquement, collecté par un fournisseur d’accès local sur trois mois. Chaque jour, ils agrègent l’activité DNS pour chaque adresse IP active en un résumé compact : nombre total de requêtes, combien de domaines différents ont été contactés et, élément crucial, comment ces domaines se répartissent en 75 catégories de contenu telles que « Activités générales », « Logiciels / Matériel » ou « Réseaux sociaux ». Ils ne conservent que les adresses IP apparaissant au moins 80 % des jours, garantissant un historique suffisant par utilisateur, et éliminent soigneusement les caractéristiques redondantes ou presque vides. Ils appliquent aussi des outils statistiques pour détecter les champs fortement corrélés, filtrer les valeurs extrêmes de volume de requêtes, puis compressent les données avec une analyse en composantes principales afin de préserver la plupart des variations utiles dans beaucoup moins de dimensions. En visualisant les données nettoyées avec une technique appelée t‑SNE, ils observent que de nombreuses adresses IP forment des groupes serrés et bien séparés—un signe précoce que la classification automatique peut être réalisable.
Mettre à l’épreuve des modèles d’apprentissage automatique
Avec cet ensemble de données traité, l’équipe considère l’identification des utilisateurs comme un vaste problème de classification : étant donné une journée de statistiques DNS, déterminer à laquelle des 1 727 adresses IP elle appartient. Ils comparent une série de modèles, depuis des méthodes classiques comme le Naive Bayes et les forêts aléatoires jusqu’à des outils plus avancés tels que XGBoost et des réseaux neuronaux profonds. Chaque modèle est entraîné et validé sur différentes versions des données (brutes, re‑échelonnées, standardisées ou à dimension réduite) et évalué sur la fréquence à laquelle il attribue correctement la bonne classe, ainsi que sur des mesures de précision et de rappel. Les modèles traditionnels s’en tirent plutôt bien—les forêts aléatoires atteignent environ 73 % de précision, et XGBoost dépasse 81 % tout en distinguant correctement plus de 99 % des classes. Mais les meilleurs résultats viennent des réseaux neuronaux, en particulier un réseau de neurones convolutionnel (CNN) personnalisé qui traite le vecteur de caractéristiques comme une image unidimensionnelle du comportement quotidien.
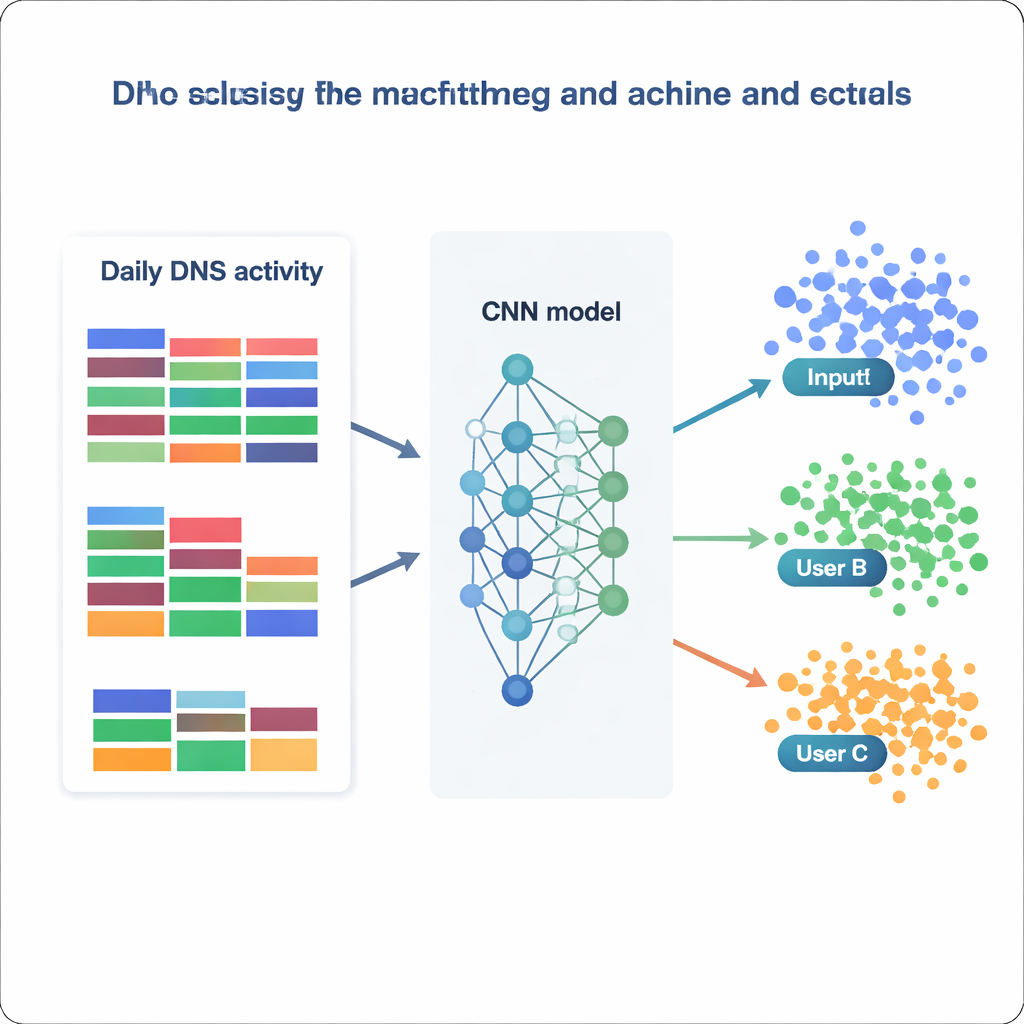
Jusqu’où un modèle peut‑il connaître « qui » vous êtes ?
Le meilleur CNN, entraîné sur des données normalisées, identifie correctement l’adresse IP source sur près de 87 % des jours mis de côté et prédit avec succès 1 694 des 1 727 adresses IP distinctes. En termes pratiques, cela signifie que la plupart des utilisateurs—ou de petits groupes derrière une IP partagée—affichent des schémas DNS stables et reconnaissables dans le temps. En examinant sur quelles caractéristiques les modèles s’appuient le plus, les auteurs identifient deux stratégies complémentaires. Certains modèles s’appuient fortement sur des catégories très communes, comme les services professionnels généraux ou les logiciels, capturant des habitudes larges. D’autres, comme XGBoost, tirent une puissance additionnelle de catégories rares mais révélatrices liées à la sécurité, à la politique ou à des centres d’intérêt de niche. Ensemble, ces résultats montrent que même des statistiques agrégées et simples—sans consulter la liste complète des noms de domaine—peuvent encoder suffisamment de structure pour ré‑identifier les utilisateurs avec une fiabilité remarquable.
Promesses, limites et enjeux de confidentialité
Pour les forces de l’ordre et les défenseurs des réseaux, les empreintes DNS pourraient devenir un outil précieux pour traquer des récidivistes, repérer des machines compromises ou détecter des botnets qui utilisent des adresses IP changeantes pour échapper aux blocages. En même temps, l’étude met en évidence des limites claires : les empreintes DNS sont les plus stables lorsqu’une IP publique est associée à un seul utilisateur, ce qui est plus réaliste dans les réseaux IPv6 modernes que dans l’IPv4 d’aujourd’hui où de nombreux utilisateurs partagent une même adresse via le NAT. Les changements fréquents de serveurs DNS ou l’utilisation de réseaux Wi‑Fi publics affaiblissent aussi le signal. Surtout, ce travail souligne un risque pour la vie privée difficile à percevoir pour l’utilisateur ordinaire. Parce que la journalisation DNS est largement invisible et passive, le pistage comportemental peut se produire sans installer de cookies ni de scripts intrusifs. Les auteurs publient ouvertement leur jeu de données et leurs modèles, arguant qu’une recherche transparente est nécessaire pour que la société puisse peser les bénéfices de sécurité de l’empreinte DNS face à son potentiel de surveillance silencieuse et décider quelles protections et quelles politiques devraient encadrer cette nouvelle forme puissante d’identification en ligne.
Citation: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Mots-clés: Empreinte DNS, pistage des utilisateurs, vie privée sur Internet, sécurité réseau, apprentissage automatique