Clear Sky Science · fr
Les modèles cognitifs facilitent l’inférence en temps réel des motifs latents
Pourquoi deviner des objectifs cachés importe
Chaque jour, vous lisez silencieusement les intentions des personnes autour de vous — si un conducteur va changer de voie, si un cycliste va s’arrêter, ou si un collègue cherche à aider ou à rivaliser. Ces jugements en une fraction de seconde reposent sur l’interprétation de motifs cachés à partir de mouvements visibles. L’intelligence artificielle actuelle peut être extrêmement précise en matière de prédiction, mais elle agit souvent comme une « boîte noire » incapable d’expliquer pourquoi elle a pris une décision. Cette étude se demande si des modèles psychologiques du comportement humain peuvent donner à l’IA une compréhension des motifs d’autrui plus proche de celle des humains, la rendant plus rapide, plus précise et plus digne de confiance.
Un jeu simple de poursuite et d’évitement
Pour explorer cela, les chercheurs ont conçu un jeu vidéo épuré. À chaque round de 10 secondes, un joueur humain dirigeait un « vaisseau » triangulaire au joystick tandis qu’un vaisseau contrôlé par l’ordinateur se déplaçait selon l’un de plusieurs schémas. L’humain se voyait attribuer secrètement l’un des trois objectifs : Attaquer (entrer en collision avec l’autre vaisseau), Éviter (rester loin), ou Inspecter (rester à proximité sans percuter). Le vaisseau informatique pouvait se comporter de manière agressive, timide, curieuse, défensive, ou simplement erratique. Ces combinaisons ont créé des situations où les mouvements des vaisseaux concordaient ou entraient en conflit — par exemple, un humain attaquant poursuivant un ordinateur timide qui tente constamment de fuir.
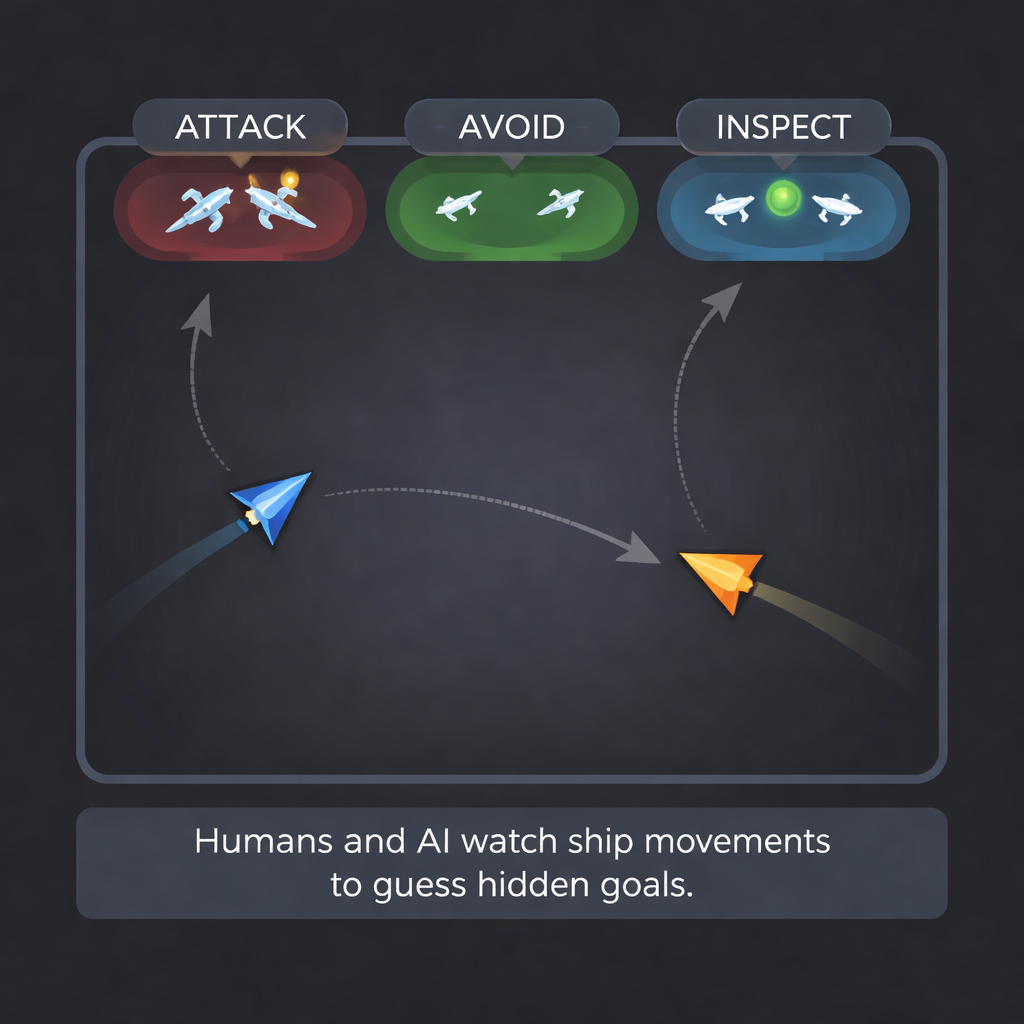
Mesurer la capacité des humains à lire des objectifs cachés
La première étape a été de déterminer dans quelle mesure les personnes elles-mêmes peuvent lire des motifs à partir du mouvement. L’équipe a pris des parties des huit pilotes de vaisseau les plus performants et a transformé chaque round en une courte vidéo. De nouveaux volontaires ont regardé ces clips et devaient deviner l’objectif du joueur humain — attaquer, éviter ou inspecter — après n’avoir vu que 1, 4, 7 ou 10 secondes de mouvement. Dans plusieurs groupes, y compris des participants avec et sans diagnostic d’autisme, les gens ont correctement identifié l’objectif environ deux fois sur trois. La précision augmentait avec la durée d’observation du round, et les performances étaient similaires entre les groupes, fournissant une référence humaine solide pour la comparaison.
Un plan psychologique du mouvement
Plutôt que d’alimenter directement des données brutes de type vidéo dans un réseau neuronal, les auteurs ont construit un modèle cognitif pour capturer les forces susceptibles de guider le mouvement d’une personne. Leur modèle « poursuite d’objectifs global-locaux » (GLOP) suppose qu’un joueur équilibre plusieurs forces simultanément : maintenir une distance préférée par rapport à l’adversaire (trop près semble dangereux, trop loin fait rater des opportunités), rester dans des positions utiles à l’écran plutôt que d’être coincé dans un coin, et s’aligner ou anticiper le rythme et la direction de l’autre vaisseau. Ces facteurs sont combinés en une unique direction « motivationnelle » de mouvement, avec des termes supplémentaires reflétant la fluidité du déplacement et le degré d’aléa dans le contrôle.
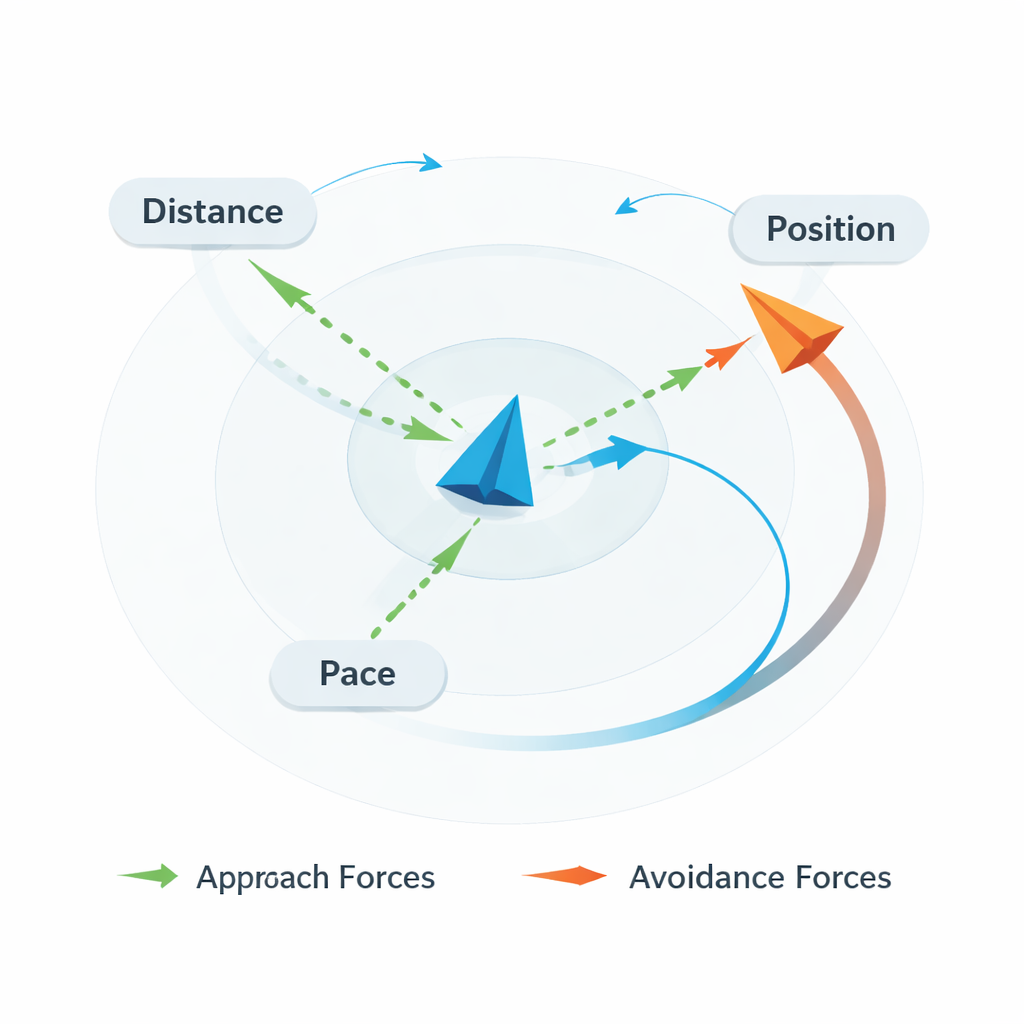
Apprendre à l’IA à lire les esprits à partir du mouvement
Pour rendre ce modèle utile en temps réel, les chercheurs ont simulé 100 000 rounds de jeu en utilisant de nombreux réglages différents des paramètres GLOP. Ils ont ensuite entraîné un réseau neuronal récurrent à ingérer des séquences de positions des vaisseaux et à estimer rapidement les paramètres latents — tels que la distance préférée ou l’importance accordée à la position globale. Ce réseau a pu récupérer plusieurs paramètres clés avec grande précision à partir de seulement quelques secondes de mouvement. Ensuite, ils ont entraîné un ensemble de classifieurs pour deviner l’objectif du joueur de trois façons différentes : directement à partir des données de position brutes, à partir de statistiques récapitulatives simples (comme la distance moyenne et l’approche versus l’évitement), ou à partir des paramètres inférés par le modèle cognitif. Enfin, ils ont construit des classifieurs « ensemblistes » combinant ces sources.
Dépasser la référence humaine
Tous les classifieurs d’IA ont égalé ou dépassé la performance humaine, mais la manière dont l’information leur était présentée était déterminante. Les réseaux qui se fondaient uniquement sur le mouvement brut ou uniquement sur les paramètres du modèle se comportaient de manière similaire aux humains, à environ 66 % de précision. Les classifieurs recevant de simples statistiques récapitulatives faisaient mieux, et les meilleurs résultats provenaient de la combinaison de ces statistiques avec les paramètres du modèle cognitif, atteignant environ 72 % de précision. Ces systèmes informés par le modèle s’entraînaient aussi plus rapidement et de façon plus stable que ceux nourris uniquement de données brutes. Lorsqu’on suivait la précision image par image pendant chaque round, l’IA pouvait mettre à jour son hypothèse sur l’objectif caché d’un joueur en moins du temps entre deux rafraîchissements d’écran, inférant effectivement l’intention en temps réel.
Ce que cela signifie pour l’IA du quotidien
Pour un non-spécialiste, la conclusion est que l’intégration de théories psychologiques dans l’IA peut aider les machines à comprendre non seulement ce que font les gens, mais pourquoi ils le font. En traduisant des mouvements désordonnés en un petit nombre de motifs interprétables — par exemple la proximité désirée par quelqu’un ou la manière dont il pèse sécurité et opportunité — le système devient à la fois plus précis et plus facile à expliquer. Dans des applications futures telles que les voitures autonomes ou les équipes homme–IA, ce type de « front-end cognitif » pourrait aider l’IA à anticiper plus tôt et de manière plus fiable les intentions des autres agents, évitant potentiellement collisions et malentendus tout en fournissant des explications compréhensibles par les humains comme « l’autre conducteur essaie probablement de se rabattre, pas simplement de dériver. »
Citation: Fitch, A.K., Kvam, P.D. Cognitive models facilitate real-time inference of latent motives. Sci Rep 16, 6444 (2026). https://doi.org/10.1038/s41598-026-37587-8
Mots-clés: théorie de l’esprit, modélisation cognitive, inférence d’intention, interaction humain–IA, IA explicable