Clear Sky Science · fr
Super-résolution de visages réels basée sur des réseaux antagonistes génératifs et d'alignement de visages
Des visages plus nets à partir de photos floues
Quiconque a essayé de zoomer sur un visage dans une vieille vidéo de surveillance ou une petite photo sur les réseaux sociaux connaît la frustration : plus on agrandit, plus le visage se transforme en une tache pixelisée. Cet article présente une nouvelle approche d'intelligence artificielle capable de transformer ces images de visages réelles et de faible qualité en images beaucoup plus nettes, tout en préservant mieux l'identité et l'expression de la personne. Les implications sont évidentes pour les caméras de sécurité, la criminalistique photographique et même les applications grand public d'amélioration de photos.
Pourquoi les visages flous sont si difficiles à réparer
Rendre net un petit visage flou n'est pas une simple question « d'ajout de pixels ». Les méthodes traditionnelles reposaient sur des règles conçues à la main ou des motifs simples, et les techniques récentes d'apprentissage profond apprenaient souvent à partir d'images dégradées artificiellement : prendre un visage propre en haute résolution, le flouter et le réduire, puis apprendre à un réseau à inverser le processus. Le problème est que les images du monde réel — comme celles des caméras de surveillance ou des vidéos compressées — sont dégradées de manière chaotique et imprévisible. Le flou, le bruit et les artefacts de compression ne correspondent que rarement aux exemples synthétiques propres utilisés pour l'entraînement, si bien que des modèles qui brillent en laboratoire échouent souvent sur des séquences réelles. Pire encore, ils peuvent produire des visages plausibles qui ne ressemblent plus à la personne d'origine.
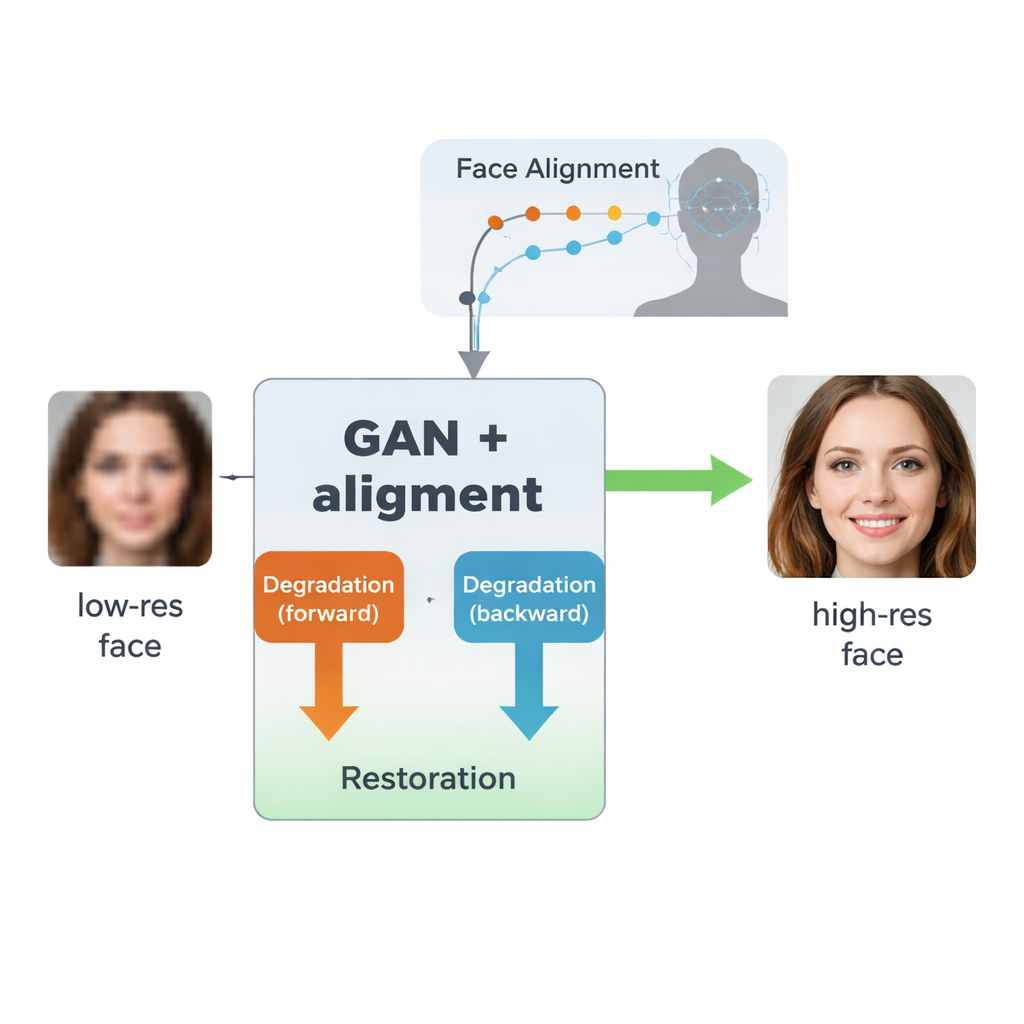
Une boucle d'apprentissage bidirectionnelle pour les images réelles
Les auteurs s'appuient sur un type d'IA appelé réseau antagoniste génératif (GAN), qui apprend à créer des images réalistes en opposant deux réseaux neuronaux : l'un génère des images, l'autre juge leur réalisme. Leur architecture, inspirée d'un modèle antérieur nommé SCGAN, utilise une structure en « semi-cycle » avec deux boucles complémentaires. Dans la boucle avant, des visages réels en haute résolution sont volontairement dégradés par une branche pour produire des versions synthétiques en basse résolution, puis restaurés par une branche de restauration partagée. Dans la boucle arrière, des visages réels de très faible qualité sont améliorés par cette même branche de restauration puis à nouveau dégradés par une autre branche pour ressembler aux images basse résolution réelles. En imposant la cohérence dans les deux sens — dégrader puis restaurer, ou restaurer puis dégrader — le système apprend un modèle réaliste de la manière dont les visages sont abîmés en pratique, et comment inverser ce processus sans jamais avoir besoin de paires parfaitement appariées d'images réelles basse et haute qualité.
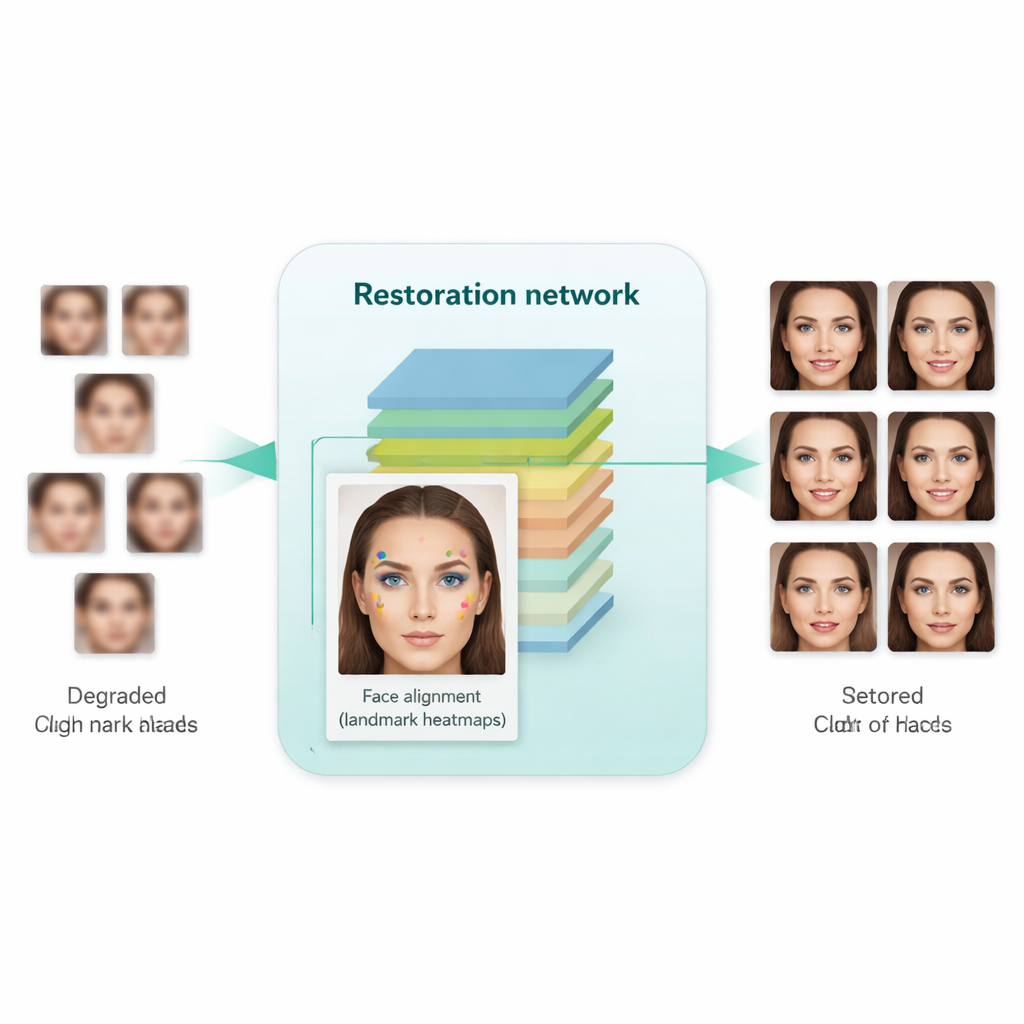
Apprendre au réseau à reconnaître la structure réelle d'un visage
Une innovation clé de ce travail est d'apprendre au système non seulement à rendre les images plus nettes, mais aussi à respecter la structure sous-jacente du visage humain. Pour cela, les auteurs intègrent un réseau d'alignement de visage séparé, conçu initialement pour localiser des repères tels que les coins des yeux, la pointe du nez et le contour de la bouche. Ce réseau d'alignement prédit des « cartes de chaleur » qui mettent en évidence l'emplacement attendu de chaque repère. Pendant l'entraînement, le modèle compare les cartes de chaleur issues de l'image restaurée avec celles d'un visage réel en haute résolution de la même personne, et pénalise les discordances. Crucialement, cela utilise un modèle d'alignement pré-entraîné et ne nécessite pas d'annotations manuelles de repères pour chaque image d'entraînement. Le résultat est une forme de guidage géométrique : le réseau d'amélioration est incité à placer correctement les yeux, le nez et la bouche en termes de position et de forme, au lieu de simplement recouvrir le flou par des textures génériques ressemblant à un visage.
Quelle est l'efficacité en pratique ?
Les chercheurs ont entraîné leur système sur une grande collection de visages de haute qualité et un ensemble distinct de visages réellement de faible qualité issus de jeux de données du monde réel. Ils l'ont ensuite testé sur des benchmarks synthétiques (où des images de référence propres sont disponibles) et sur des images réelles (où seul le réalisme visuel et des mesures statistiques peuvent être utilisés). Comparée aux méthodes antérieures — y compris des outils bien connus comme Real-ESRGAN, GFPGAN et le SCGAN original — la nouvelle approche a produit des images non seulement plus naturelles et moins déformées, mais ayant aussi conduit à de meilleures performances sur des tâches pratiques. Lorsque les images améliorées ont été traitées par des détecteurs de visage standard et un modèle populaire de reconnaissance faciale (FaceNet), la précision de détection et de vérification s'est notablement améliorée, indiquant que les détails liés à l'identité étaient mieux préservés. Parallèlement, des métriques automatiques de qualité ont suggéré que les visages générés étaient plus proches, en distribution, des photos haute résolution réelles.
Qu'est-ce que cela signifie pour un usage quotidien ?
En termes simples, ce travail montre qu'il est possible d'obtenir des visages plus nets et plus fiables à partir d'images de mauvaise qualité en combinant deux idées : apprendre un modèle réaliste de la manière dont les images sont détériorées dans le monde réel, et utiliser l'information des repères faciaux pour préserver la structure du visage. Plutôt que de « deviner » un visage plus plaisant, le système est guidé pour reconstruire la bonne personne avec des yeux, une bouche et une silhouette plus clairs. Cela rend la méthode particulièrement prometteuse pour des applications comme la sécurité, la criminalistique et la restauration d'archives, où la clarté visuelle et l'identité correcte sont cruciales et où des versions haute qualité d'origine sont rarement disponibles.
Citation: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Mots-clés: super-résolution de visages, réseaux antagonistes génératifs, alignement de visages, reconnaissance faciale, restauration d'image