Clear Sky Science · fr
Pipeline de traitement d’images pour la caractérisation automatisée par IA d’une mégabibliothèque de nanoparticules
Pourquoi les toutes petites particules ont besoin de l’aide du big data
La science des matériaux moderne repose de plus en plus sur la fabrication et l’évaluation d’un très grand nombre de particules minuscule pour découvrir de meilleurs catalyseurs, batteries et autres matériaux avancés. De nouvelles méthodes permettent désormais de faire croître des millions de nanoparticules différentes sur une seule puce, mais vérifier la qualité de chacune au microscope génère bien plus d’images que ce qu’un humain peut raisonnablement examiner. Cet article décrit comment des chercheurs ont construit un pipeline automatisé de traitement d’images et d’IA qui trie rapidement les images de nanoparticules « bonnes » et « mauvaises », réduisant les coûts informatiques et accélérant les expériences tout en maintenant des décisions très fiables.
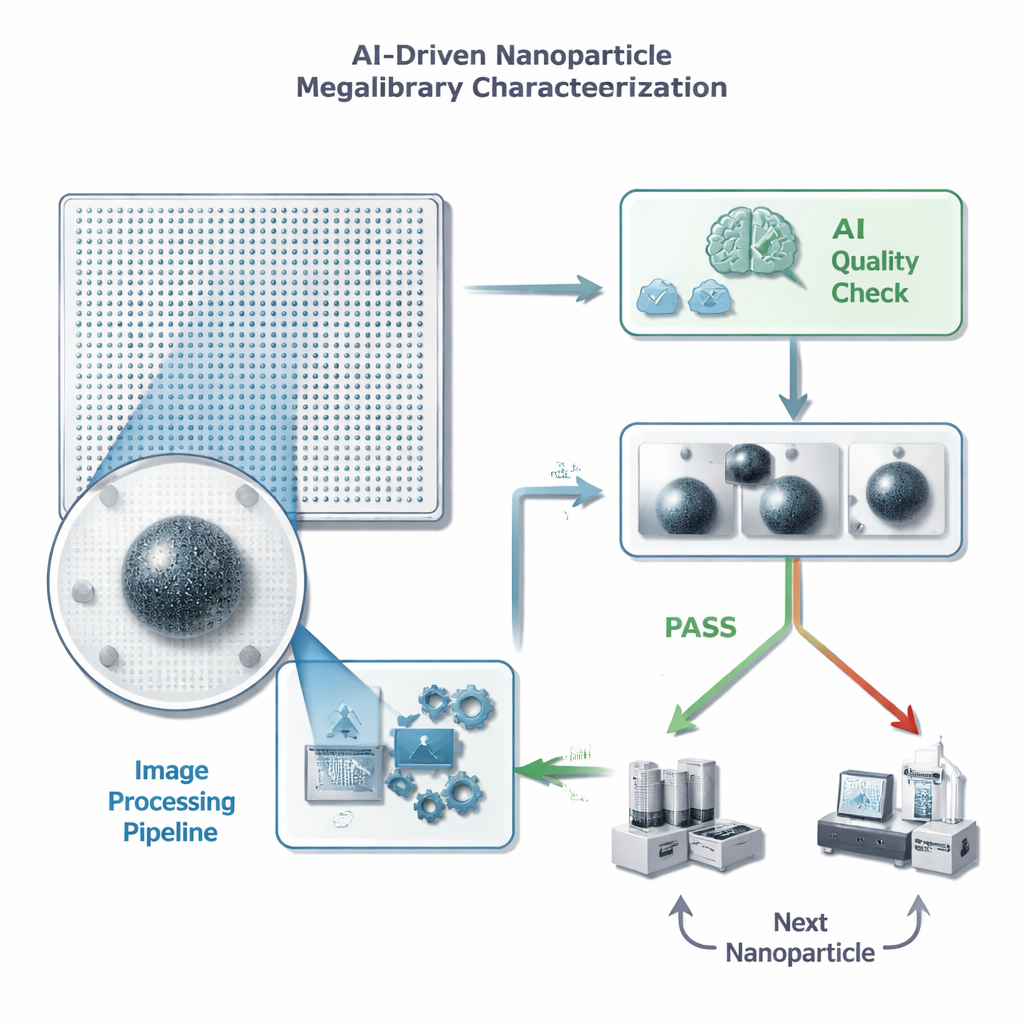
D’images sans fin à des décisions rapides
Chaque nanoparticule d’une puce de « mégabibliothèque » se trouve à une position connue et peut être imagée au microscope électronique. Avant d’investir du temps et des mesures de suivi coûteuses sur une particule, les scientifiques ont besoin d’un contrôle qualité rapide : y a‑t‑il exactement une particule bien focalisée dans le cadre, sans éléments perturbateurs ni artefacts ? Les auteurs formulent cela comme une tâche simple d’acceptation/rejet pour un modèle d’apprentissage automatique, mais avec une contrainte stricte sur le temps alloué par image — moins d’une demi‑seconde, car une puce peut contenir des millions de particules. Ils insistent aussi sur le fait que les faux positifs sont particulièrement préjudiciables : si l’IA valide par erreur une mauvaise image, elle gaspillera du temps et du stockage sur des mesures détaillées inutiles, tandis que l’oubli occasionnel d’une bonne particule nuit moins au progrès global.
Nettoyer la vue avant que l’IA n’examine
Plutôt que d’envoyer des images brutes et bruitées directement dans un grand réseau neuronal complexe, l’équipe a conçu un pipeline de traitement d’images personnalisé qui « nettoie » d’abord les images. Le pipeline élimine le bruit de fond, aiguise les contours, recadre étroitement autour de la particule, puis réduit l’image à une taille beaucoup plus petite. De manière cruciale, ce prétraitement rend les traits faibles plus visibles et imite l’apparence d’une image à plus fort grossissement sans réimager l’échantillon. Le résultat est une image compacte et à fort contraste qui peut être entrée dans un réseau neuronal relativement simple, réduisant à la fois le temps d’entraînement et les besoins de stockage tout en préservant les détails importants pour les jugements de qualité.
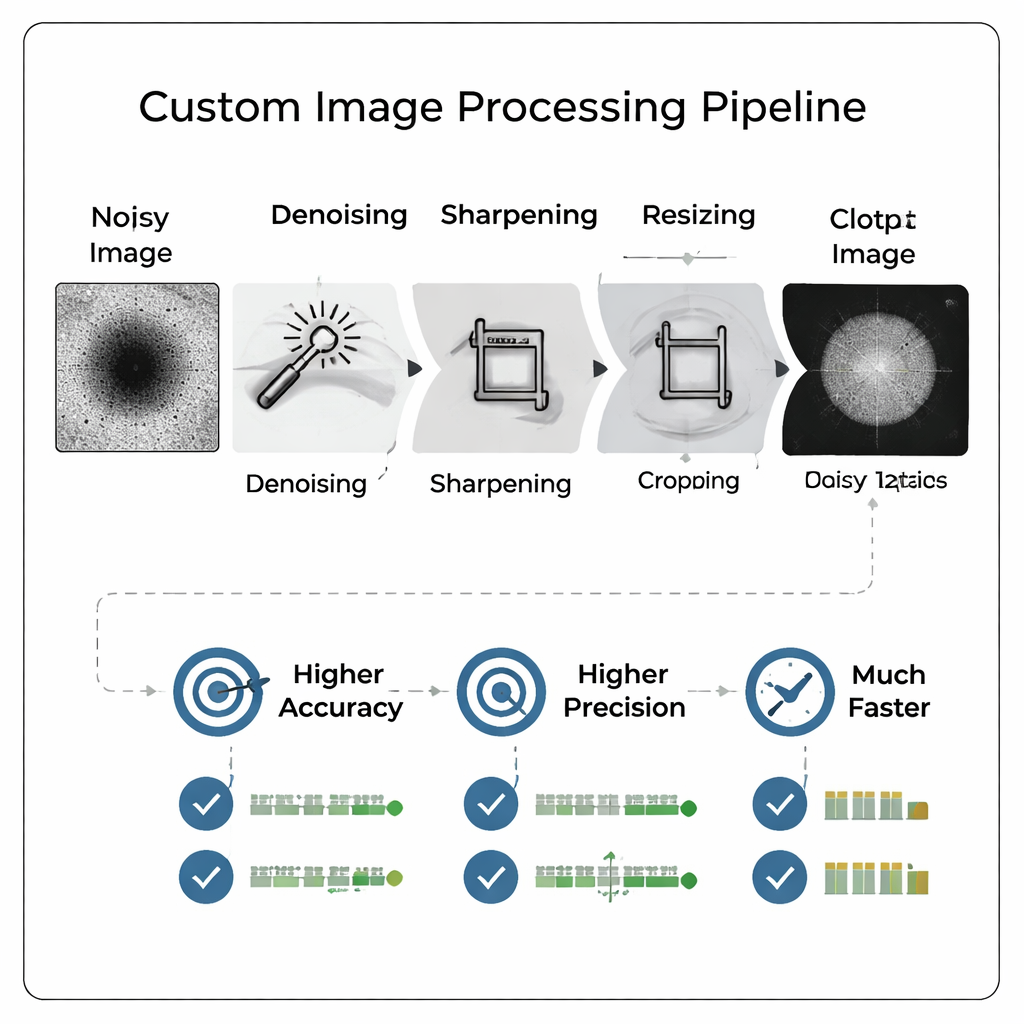
Des images plus intelligentes surpassent des modèles plus gros
Les chercheurs ont comparé de manière rigoureuse de nombreuses variantes de pipeline et de résolutions, entraînant au total 800 modèles différents pour évaluer l’impact de la taille d’image et du traitement sur la performance. Ils ont constaté que des images soigneusement traitées à des résolutions modestes (par exemple 128×128 pixels) permettaient à un petit réseau convolutionnel de surpasser un modèle antérieur bien plus volumineux découvert par recherche d’architecture automatisée et entraîné sur des images complètes en 512×512. La précision s’est améliorée de plus de 13 points de pourcentage, tandis que le rappel — la capacité à détecter correctement les bonnes particules — a augmenté de plus de 18 points. La précision (precision), mesure clé pour éviter les efforts gaspillés sur de mauvaises particules, a atteint environ 96 %, et la métrique de performance combinée favorisée par les auteurs s’est également améliorée.
Faire plus avec beaucoup moins de données
Un des résultats les plus marquants est que le traitement importe davantage que la taille brute de l’image. Lorsque l’équipe a comparé des modèles entraînés sur de simples images « uniquement réduites » à ceux utilisant le pipeline complet, les images traitées l’ont systématiquement emporté — même lorsqu’elles étaient réduites à des tailles extrêmement petites comme 16×16 pixels. En fait, le meilleur modèle utilisant des images traitées en 16×16 a surpassé le meilleur modèle utilisant des images non traitées en 128×128 sur presque toutes les métriques. Le pipeline s’est aussi avéré le plus utile aux faibles grossissements du microscope, où les images sont normalement plus difficiles à interpréter. Comme les images à faible grossissement sont plus rapides à acquérir, cela permet aux laboratoires de scanner les puces plus vite sans sacrifier la qualité des décisions.
Des décisions plus rapides pour des laboratoires autonomes
En combinant un traitement d’images intelligent avec un modèle d’IA épuré, les auteurs ont réduit les temps d’entraînement de plusieurs heures sur un superordinateur à moins d’une minute sur un seul processeur graphique. Une fois entraîné, le système peut traiter et classer une nouvelle image en environ 75 millisecondes, bien en deçà de l’objectif de 500 millisecondes et bien plus rapide qu’un évaluateur humain. En termes pratiques, cela se traduit par un criblage rapide et fiable des mégabibliothèques de nanoparticules, aidant les chercheurs à concentrer des instruments coûteux sur les candidats les plus prometteurs. À mesure que les laboratoires évoluent vers des systèmes de découverte plus automatisés et « autonomes », des approches comme celle‑ci — nettoyer d’abord les données, puis appliquer une IA rationalisée — offrent un moyen puissant de transformer des flux d’images écrasants en informations scientifiques exploitables.
Citation: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Mots-clés: nanoparticules, traitement d’images, apprentissage automatique, découverte de matériaux, microscopie électronique