Clear Sky Science · fr
Recherche sur des modules d'amélioration de la corrélation plug-and-play en apprentissage profond multi-étiquettes
Apprendre aux machines à gérer trop d’étiquettes
Les boutiques en ligne, les archives juridiques et les bases de données médicales dépendent toutes de logiciels capables d’étiqueter rapidement chaque nouveau document avec les bons libellés. Mais les systèmes modernes font souvent face à des dizaines de milliers, voire des millions, d’étiquettes possibles — des catégories de produits aux sujets médicaux — alors que chaque texte n’a besoin que d’une poignée de libellés. Cet article présente un nouvel ajout, appelé Label Correlation Enhancement Network (LCENet), qui aide les modèles d’apprentissage profond existants à mieux exploiter la façon dont les étiquettes apparaissent naturellement ensemble dans les données réelles, conduisant à un étiquetage de texte plus précis et plus rapide.
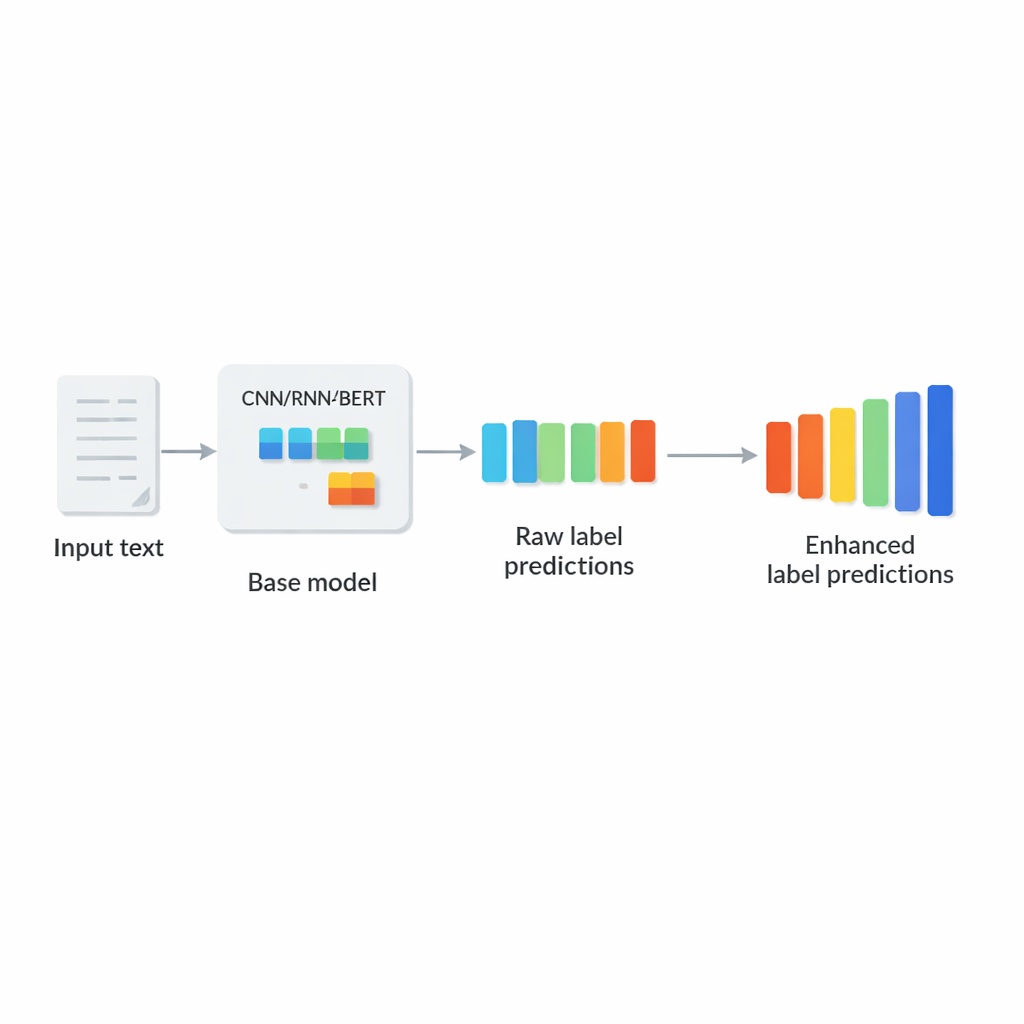
Pourquoi l’étiquetage à l’échelle du web est si difficile
Beaucoup d’applications réelles relèvent de ce que les chercheurs appellent la classification de texte multi-étiquettes extrême : donné une courte description ou un long document, le système doit choisir un petit sous-ensemble d’étiquettes pertinentes dans un catalogue énorme. Les exemples incluent l’affectation de catégories aux produits d’un site e‑commerce, l’indexation d’articles biomédicaux avec des termes MeSH, l’appariement d’annonces à des pages web, ou la cartographie de textes juridiques vers des codes légaux détaillés. Ces contextes partagent trois défis : la liste d’étiquettes est extrêmement vaste, la plupart des étiquettes sont rares, et chaque texte n’utilise que quelques étiquettes. Les techniques traditionnelles divisent le problème en nombreux classifieurs plus petits ou compressent les étiquettes en vecteurs de plus faible dimension, mais elles reposent souvent sur des comptages de mots simples et ne capturent pas pleinement le sens ni les relations entre étiquettes.
Ce que les modèles profonds standard manquent encore
Les approches modernes d’apprentissage profond, telles que les réseaux convolutionnels, récurrents et les modèles basés sur Transformer comme BERT, ont beaucoup amélioré la compréhension du texte en apprenant des représentations sémantiques riches. Pourtant, presque tous font une simplification cruciale à l’étape finale : une fois le texte encodé en vecteur, ils prédisent chaque étiquette indépendamment. En pratique, toutefois, les étiquettes interagissent fortement. Un article médical étiqueté « diabète » est plus susceptible d’impliquer aussi « résistance à l’insuline », et un appareil étiqueté « smartphone » est généralement lié à « électronique » et « dispositifs de communication ». Ignorer ces patrons empêche les modèles d’utiliser des étiquettes à haute confiance pour soutenir des étiquettes plus faibles, et ils peuvent même produire des combinaisons qui n’ont pas de sens ensemble.
Un module plug-in qui apprend les relations d’étiquettes
Les auteurs proposent LCENet comme un module léger, plug-and-play, qui se place après n’importe quel classifieur de texte profond existant. Au lieu de modifier la façon dont le modèle de base lit le texte, LCENet prend les scores bruts d’étiquettes qu’il produit et les fait passer à travers un « goulot d’étranglement » compact qui oblige le système à découvrir une représentation de faible dimension où les étiquettes reliées se regroupent. Des fonctions d’activation non linéaires permettent ensuite au module de capturer des associations complexes d’ordre supérieur, pas seulement des liens pair-à-pair simples. Une connexion résiduelle, ou de contournement, alimente les scores originaux directement vers la sortie aux côtés des scores corrigés, ce qui stabilise l’entraînement et garantit que l’add-on ne peut pas facilement dégrader les performances. Essentiellement, LCENet réduit le nombre de paramètres supplémentaires d’une quantité qui croîtrait en carré du nombre d’étiquettes à une croissance beaucoup plus gérable, linéaire, ce qui le rend faisable même pour des centaines de milliers d’étiquettes.
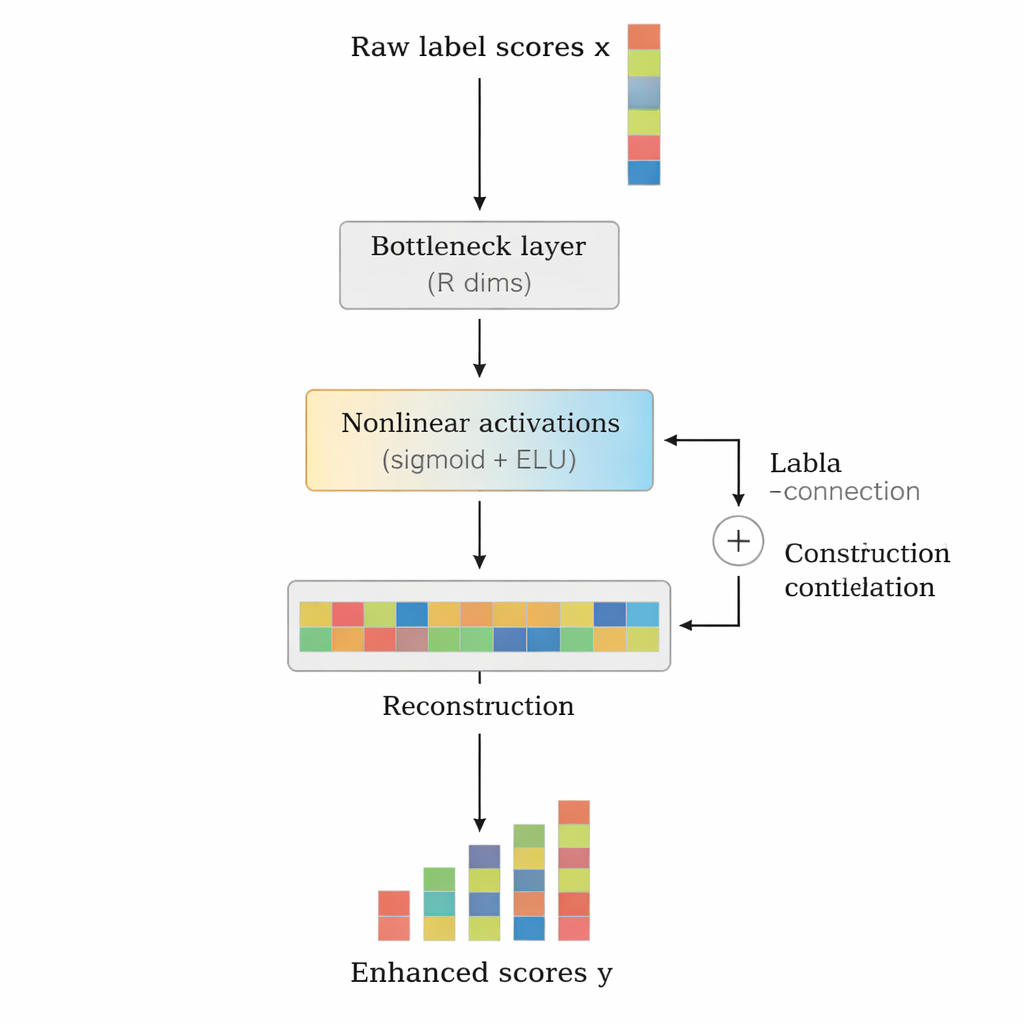
Démontrer les bénéfices sur modèles et jeux de données
Pour tester si LCENet est réellement général, les auteurs l’ont rattaché à quatre modèles profonds très différents, y compris des architectures basées sur CNN et BERT, ainsi que des systèmes conçus spécifiquement pour des contextes biomédicaux et d’étiquettes extrêmes. Ils ont évalué ces combinaisons sur trois jeux de référence publics : un corpus juridique européen (EUR-Lex), un jeu de données produits Amazon (AmazonCat-13K), et une imposante collection Wikipedia avec plus d’un demi-million d’étiquettes (Wiki-500K). Sur l’ensemble des modèles, des jeux de données et de six métriques axées sur le classement, LCENet a systématiquement amélioré les performances, augmentant parfois la précision en top-1 de plus de cinq points de pourcentage sur le plus grand jeu de données. Les courbes d’entraînement ont en outre montré que LCENet réduit souvent de moitié le nombre d’étapes d’entraînement nécessaires pour atteindre une précision donnée, car la structure de corrélation d’étiquettes ajoutée fournit dès le départ des signaux d’apprentissage plus clairs.
Pourquoi cela compte pour les systèmes quotidiens
Pour les praticiens qui s’appuient déjà sur des modèles profonds pour étiqueter des textes, LCENet offre un moyen pratique d’améliorer la précision et la vitesse d’entraînement sans repenser leurs systèmes ni collecter de nouveaux types d’annotations. Il considère l’espace d’étiquettes lui-même comme une source de connaissance, apprenant quelles étiquettes tendent à apparaître ensemble ou à s’exclure mutuellement, puis ajustant les prédictions en conséquence. Bien qu’il ait été développé pour le texte, la même idée d’améliorer les prédictions en utilisant des relations apprises entre sorties pourrait s’appliquer aux images, aux données multimodales et à d’autres tâches de prédiction structurée. En termes simples, LCENet aide les machines à « se souvenir » de la façon dont les étiquettes se relient, afin qu’elles devinent moins comme des cases isolées et davantage comme un humain informé qui comprend comment les concepts s’articulent.
Citation: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Mots-clés: classification de texte multi-étiquettes extrême, corrélation d'étiquettes, apprentissage profond, classification de texte, réseaux de neurones