Clear Sky Science · fr
DMSCA : attention dynamique multiscalaire canal-spatial pour un meilleur encodage des caractéristiques dans les réseaux de neurones convolutifs
Apprendre aux ordinateurs à mieux faire attention
Les systèmes modernes de reconnaissance d'images repèrent des chats, des panneaux de signalisation ou des tumeurs sur des scans — mais ils ne savent pas toujours sur quoi se concentrer dans une image. Cet article présente une nouvelle méthode pour aider ces systèmes à se focaliser sur les parties les plus importantes d'une image, améliorant la précision et la fiabilité dans les conditions bruitées de la vie réelle. La méthode, appelée Dynamic Multi-Scale Channel-Spatial Attention (DMSCA), se branche sur des réseaux de neurones convolutifs existants et les aide à appréhender plus intelligemment à la fois le « quoi » et le « où » dans une image.
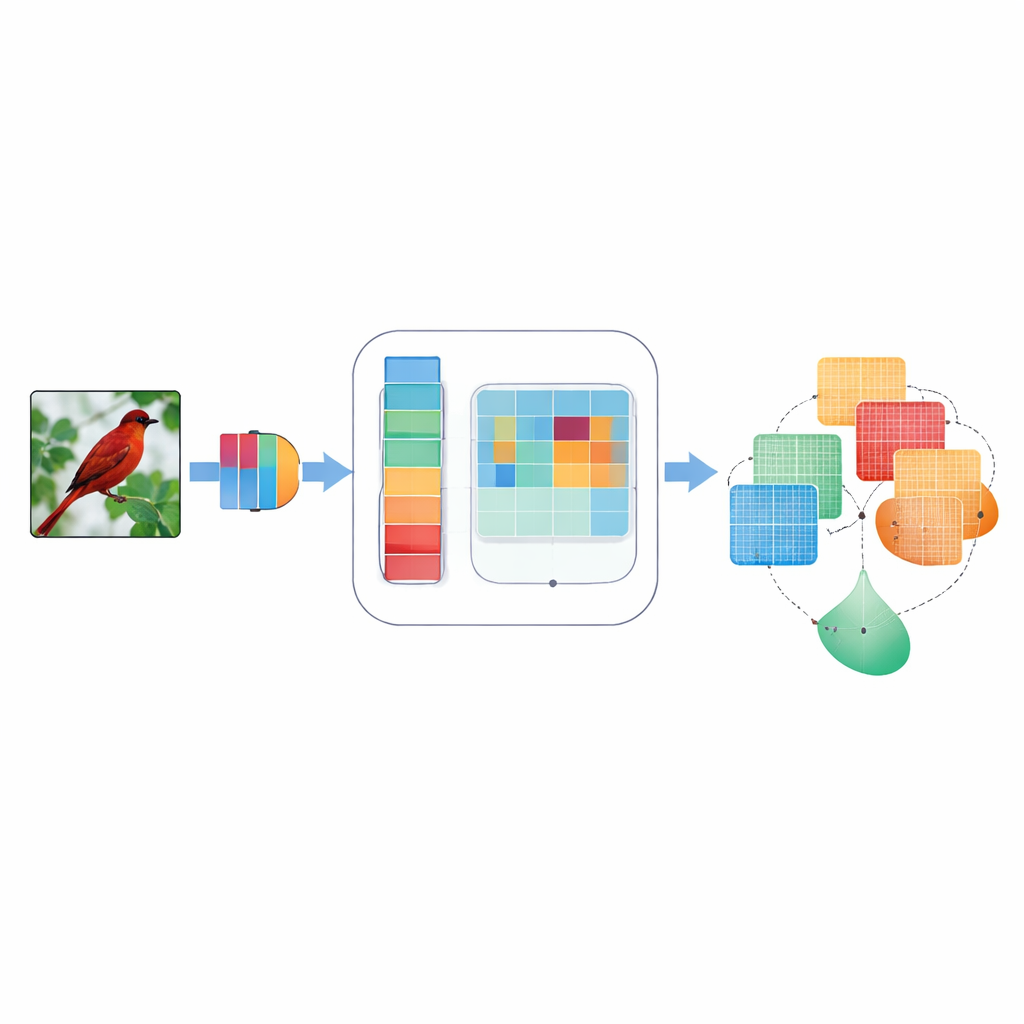
Pourquoi l'attention compte pour la vision machine
Les réseaux de neurones convolutifs, piliers de nombreuses applications visuelles, traitent en général chaque signal interne comme également important. Ainsi, le faible bord d'une aile d'oiseau et une portion de ciel peuvent recevoir une attention similaire, alors que seul l'un aide à identifier l'espèce. Des méthodes d’« attention » antérieures ont cherché à corriger cela en pondérant certains signaux internes davantage que d'autres — soit à travers les canaux analogues à la couleur, soit à travers la disposition bidimensionnelle de l'image. Mais ces approches utilisaient souvent des règles fixes conçues à la main, ne regardaient qu'une seule échelle de détail à la fois, ou combinaient l'information de façon rigide incapable de s'adapter aux images variées. Elles ont donc parfois manqué des détails fins, ignoré des directions comme « horizontal vs vertical », ou peiné lorsque les images étaient bruitées ou floues.
Un module d'attention plus intelligent
DMSCA est conçu comme un petit module amovible pouvant s'insérer dans des architectures connues telles que ResNet sans en modifier la structure globale. En interne, il coordonne six composants étroitement liés qui travaillent ensemble plutôt qu'isolément. Une partie résume l'image entière pour capturer le contexte global, tandis qu'une autre apprend l'importance de chaque canal interne, en utilisant une « température » réglable qui peut rendre les décisions plus nettes ou plus souples selon les besoins. Côté spatial, DMSCA utilise simultanément plusieurs tailles de fenêtres pour capter à la fois de minuscules textures et de plus grandes formes, et prête explicitement attention aux directions horizontale et verticale afin que de longs bords ou rayures ne soient pas estompés. Enfin, au lieu de simplement additionner ces informations, le module apprend, pixel par pixel, combien faire confiance à l'information « quoi » issue des canaux versus l'information « où » issue de l'espace.
Examiner les images à plusieurs échelles et directions
Pour décider où regarder dans une image, DMSCA compresse d'abord les nombreux canaux internes en une carte compacte à deux couches qui met en évidence à la fois les tendances d'arrière-plan et les caractéristiques saillantes. Cette carte est ensuite passée à travers plusieurs filtres parallèles de tailles différentes. Les petits filtres détectent des détails fins comme le pelage ou les plumes, tandis que les filtres plus grands saisissent des formes telles que des têtes ou des corps entiers. En parallèle, une unité directionnelle balaye séparément les lignes et les colonnes, préservant la position exacte des structures importantes. Ces vues horizontale et verticale interagissent ensuite entre elles, de sorte qu'un signal vertical fort peut, par exemple, renforcer les localisations horizontales pertinentes. Le résultat est une carte d'attention riche qui indique au réseau non seulement qu'une zone est importante, mais où elle se situe et à quelle échelle.
Laisser le réseau décider de l'importance
Comme différentes parties d'une image peuvent requérir des stratégies distinctes, DMSCA n'impose pas de recette fixe pour combiner l'information canal et spatiale. À la place, il construit une petite « porte » qui examine les deux types d'information et décide — indépendamment pour chaque pixel — quelle pondération attribuer à chacun. Dans un arrière-plan encombré, le système peut s'appuyer davantage sur les canaux saillants, tandis qu'autour de bords d'objet nets il peut privilégier les indices spatiaux. Une étape finale d'activation adaptative agit ensuite comme un variateur appris, renforçant les régions réellement informatives et atténuant le bruit résiduel. Ce processus en plusieurs étapes aide à orienter l'attention du réseau vers des régions cohérentes liées aux objets, comme le confirment des cartes de chaleur visuelles et des mesures quantitatives de la correspondance avec les objets de référence.
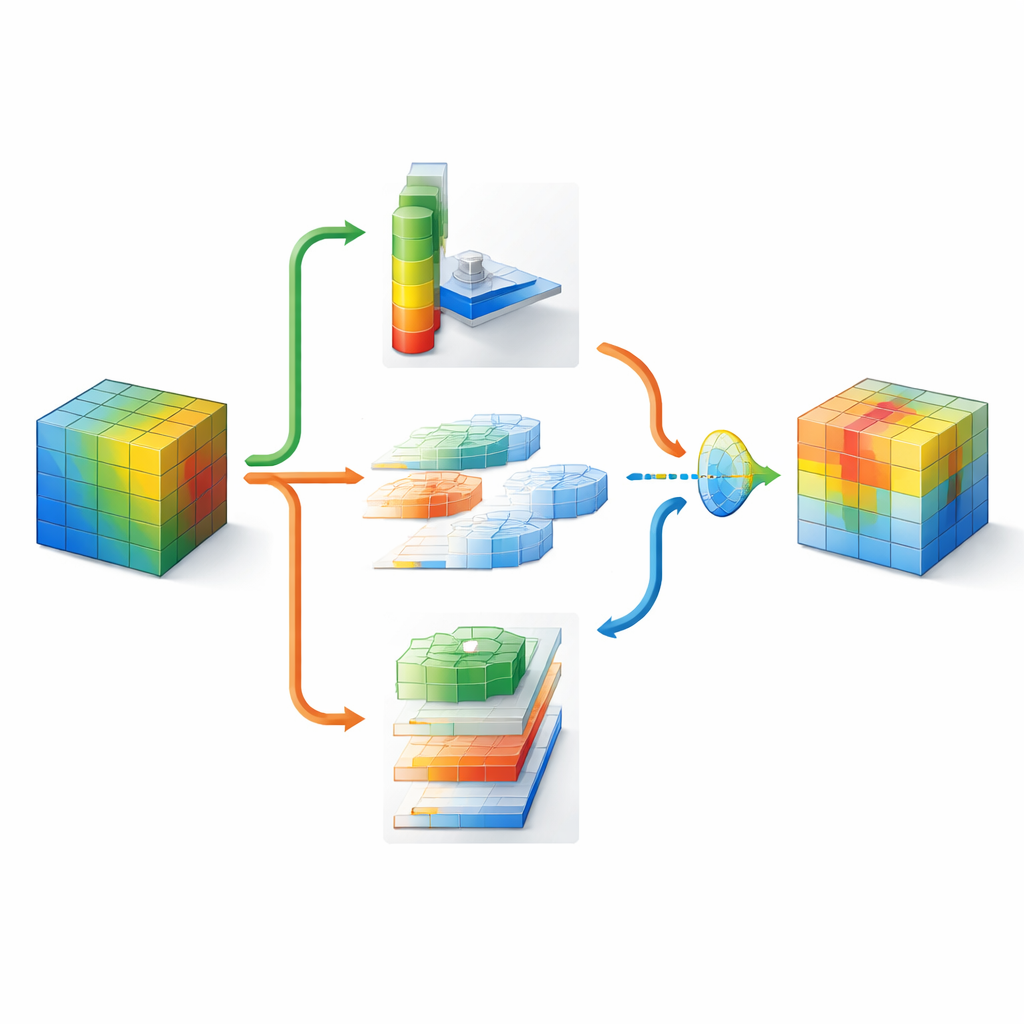
Une vision plus nette avec un surcoût modeste
Les auteurs ont évalué DMSCA sur plusieurs bancs d'essai standards, allant de petits ensembles d'images minuscules au grand corpus ImageNet. Lorsqu'il est ajouté à des modèles ResNet populaires, DMSCA améliore systématiquement la précision de classification — d'environ 2 points de pourcentage sur les petits jeux et 1,5 point sur ImageNet — surpassant plusieurs méthodes d'attention existantes. Il rend aussi les modèles plus robustes aux dégradations courantes d'image comme le bruit, le flou ou la forte compression, et améliore les performances sur des tâches associées telles que la détection d'objets et l'étiquetage de scènes. Ces gains s'obtiennent avec une augmentation modérée du coût de calcul et de la mémoire. En termes simples, DMSCA offre aux réseaux convolutifs un moyen plus flexible et contextuel de décider quoi regarder et quoi ignorer, rapprochant la vision machine de la focalisation sélective de la vision humaine.
Citation: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Mots-clés: mécanismes d'attention, reconnaissance d'images, réseaux de neurones convolutifs, représentation des caractéristiques, vision par ordinateur robuste