Clear Sky Science · fr
Améliorer la recherche cross-modale via l’optimisation du graphe d’étiquettes et des fonctions de perte hybrides
Rechercher plus intelligemment entre images et mots
Chaque jour, nous faisons défiler des océans de photos, de vidéos et de textes. Trouver exactement ce que nous voulons — par exemple, toutes les images correspondant à une courte légende — dépend de la capacité des ordinateurs à relier images et langage. Cet article explore une nouvelle façon de rendre cette liaison plus précise, en particulier dans des scènes réelles et désordonnées où de nombreuses idées et objets coexistent. Le résultat : des outils de recherche plus intelligents qui « comprennent » mieux notre intention, pas seulement ce que nous tapons.
Pourquoi plusieurs sens dans une même image comptent
Une image montre rarement une seule chose. Une photo d’une baleine en train de sauter en mer peut impliquer l’océan, le ciel, les vagues, le vent et la faune simultanément. Lorsque nous étiquetons une telle image, nous attachons souvent plusieurs labels liés entre eux de manière subtile. Les systèmes de recherche existants traitent généralement ces étiquettes comme s’il s’agissait de cases indépendantes. Cette simplification jette des indices utiles : si « baleine » apparaît souvent avec « mer », la présence de l’un devrait augmenter la probabilité de l’autre. Ce travail se concentre sur la capture de ces liens cachés entre étiquettes afin qu’une recherche sur une idée puisse aussi trouver des images et des textes exprimant des idées proches.

Construire un réseau d’étiquettes connectées
Les auteurs présentent une technique appelée réseau de convolution graphique à deux couches, ou L2-GCN, pour modéliser les relations entre étiquettes. En termes simples, chaque étiquette (comme « ciel » ou « baleine ») est traitée comme un nœud d’un réseau, et les liens entre nœuds reflètent la fréquence d’apparition conjointe de ces étiquettes. La méthode permet à chaque étiquette « d’écouter » à plusieurs reprises ses voisines, en mêlant l’information des étiquettes apparentées tout en conservant sa propre identité. Après ce processus, le système obtient des descriptions d’étiquettes enrichies qui capturent mieux la structure des scènes réelles, des idées parallèles (« mer » et « plage ») aux relations plus hiérarchiques (« animal » et « baleine »).
Apprendre à faire partager un espace commun aux images et aux textes
Bien sûr, les étiquettes ne sont qu’une partie de l’histoire ; le système doit aussi apprendre à partir des images et des textes eux-mêmes. Le cadre utilise des outils établis pour transformer les pixels bruts et les mots en caractéristiques numériques, puis projette les deux types de données dans un espace partagé où leurs significations peuvent être comparées directement. Un module adversarial — vaguement inspiré du principe de poussée-tirage des réseaux antagonistes génératifs — empêche le modèle de s’accrocher aux particularités propres aux images ou au texte. Cela aide l’espace partagé à se concentrer sur le contenu plutôt que sur le format, de sorte qu’une photo d’une rue animée et une courte légende la décrivant se retrouvent proches l’une de l’autre dans cette carte commune du sens.
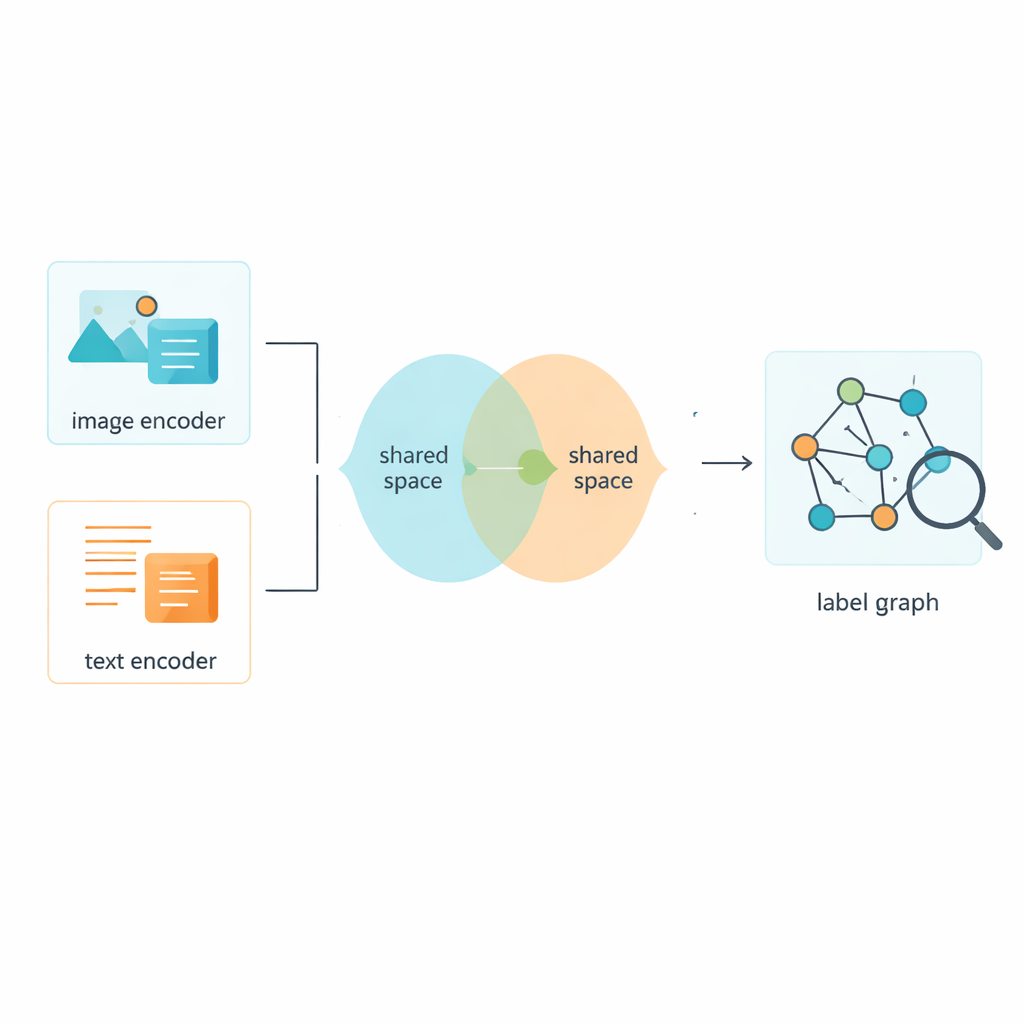
Une stratégie d’entraînement hybride pour des distinctions plus nettes
Former un tel système requiert plus d’une règle d’apprentissage. Les auteurs conçoivent une fonction de perte combinée, baptisée Circle-Soft, qui mêle deux idées complémentaires. Une partie encourage les exemples d’une même catégorie à se regrouper étroitement tout en écartant de manière flexible les catégories différentes. L’autre partie se concentre sur l’alignement entre images et textes décrivant la même scène à travers les formats. Un poids réglable équilibre ces deux objectifs afin que le modèle ne surajuste ni à des frontières de catégories strictes ni uniquement à l’alignement cross-modal. Des pertes supplémentaires de classification et adversariales favorisent aussi la cohérence entre les étiquettes affinées et les caractéristiques image–texte partagées.
Dans quelle mesure cela améliore-t-il la recherche ?
Pour vérifier si ces idées se traduisent par une meilleure recherche, les auteurs ont testé leur méthode sur trois bases populaires de paires image–texte du monde réel : MIRFlickr, NUS-WIDE et MS-COCO. Ces ensembles contiennent de quelques milliers à plusieurs centaines de milliers de photos avec des tags ou des légendes associées, couvrant des scènes quotidiennes allant des rues urbaines à la faune. Sur les trois benchmarks, la nouvelle approche devance systématiquement un large éventail de méthodes concurrentes, y compris d’autres systèmes avancés utilisant déjà la modélisation d’étiquettes par graphe. Les gains — d’environ un demi-point à un point entier de pourcentage sur une métrique stricte de récupération — peuvent sembler modestes, mais sur des benchmarks matures même de petites améliorations signalent une compréhension plus précise du contenu. En pratique, cela signifie que lorsqu’un utilisateur saisit une requête textuelle courte ou soumet une image, le système a plus de chances d’afficher les correspondances cross-modales les plus pertinentes en tête des résultats.
Ce que cela signifie pour les utilisateurs quotidiens
Pour le grand public, le message clé est que la gestion plus intelligente des étiquettes et des règles d’entraînement peut améliorer sensiblement la manière dont les machines relient images et mots. En traitant les étiquettes comme un réseau interconnecté plutôt que comme des balises isolées, et en façonnant soigneusement la rencontre de l’information visuelle et textuelle dans un espace partagé, ce cadre rend la recherche cross-modale plus fiable dans des scènes complexes et multi-thématiques. Avec le temps, des techniques comme celle-ci pourraient alimenter des bibliothèques de photos plus intuitives, des plateformes médias et des assistants intelligents capables de trouver ce que nous voulons dire — même quand nos mots ne correspondent pas parfaitement aux images que nous avons en tête.
Citation: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Mots-clés: récupération image-texte, recherche multimodale, réseaux de neurones graphiques, étiquettes sémantiques, apprentissage automatique