Clear Sky Science · fr
Amélioration de la représentation des connaissances médicales dans les grands modèles de langage par optimisation des tokens cliniques
Pourquoi une lecture médicale plus intelligente compte
Derrière chaque assistant médical IA se cache une compétence simple mais cruciale : la façon dont il découpe le texte en unités qu’il peut comprendre. Quand ce « découpage » échoue — en particulier pour des termes médicaux chinois complexes — l’IA peut manquer des idées clés dans les notes des médecins ou les questions des patients. Cet article montre comment un petit changement ciblé à cette première étape peut rendre les grands modèles de langage meilleurs pour lire, raisonner et répondre aux questions portant sur des données médicales chinoises, sans reconstruire un système entièrement nouveau.
Couper le texte en morceaux de la bonne manière
Les modèles de langage modernes ne lisent pas directement les caractères ou les mots ; ils convertissent d’abord le texte en unités courtes appelées tokens. Pour l’anglais, cela fonctionne assez bien, car les espaces marquent déjà les frontières des mots. Le chinois est plus délicat : il n’y a pas d’espaces, et de nombreuses expressions médicales sont longues et spécialisées. Les tokeniseurs standards, conçus principalement pour l’anglais, ont tendance à découper ces expressions en de nombreux fragments arbitraires. Lorsqu’un modèle voit un nom de maladie ou un examen biologique scindé en plusieurs morceaux disjoints, il a plus de peine à apprendre ce que ce terme signifie réellement, et ses réponses aux questions médicales peuvent devenir vagues ou inexactes.
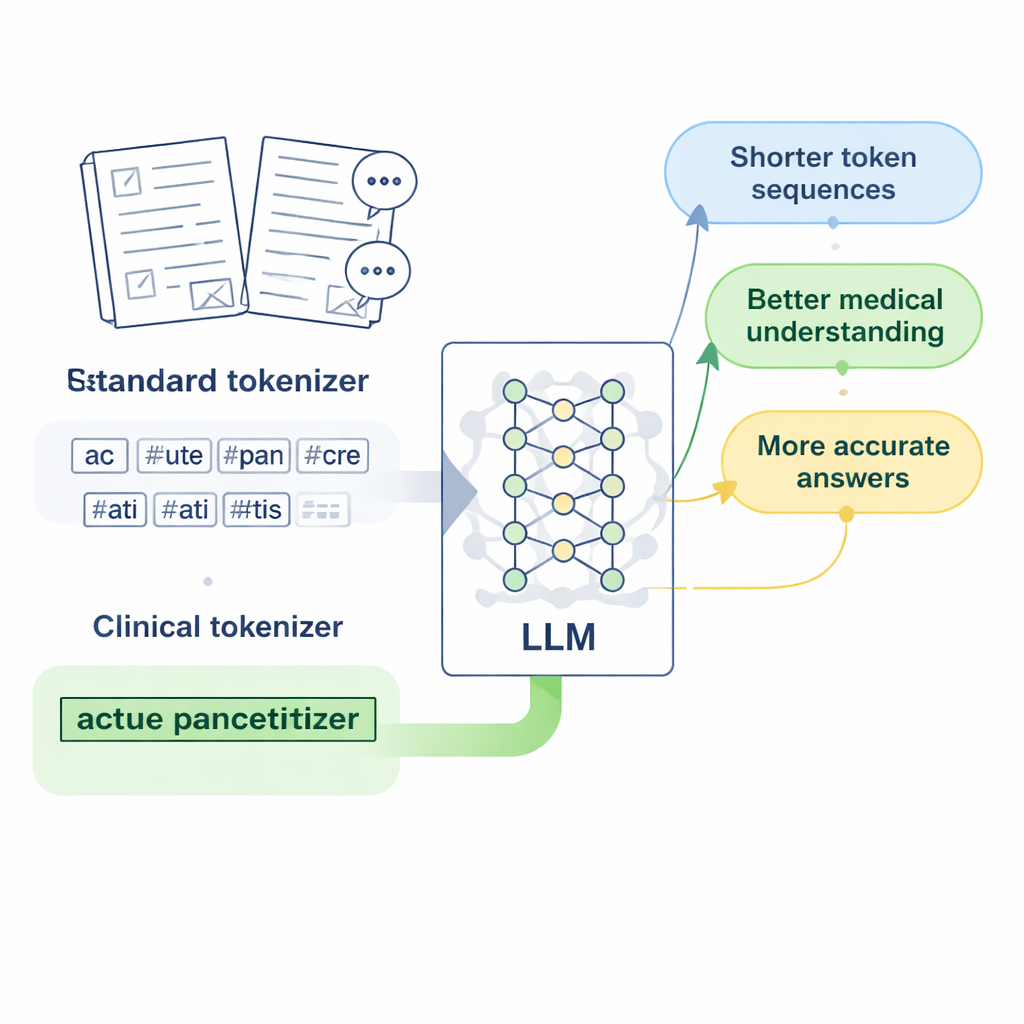
Concevoir des « tokens cliniques » pour la médecine chinoise
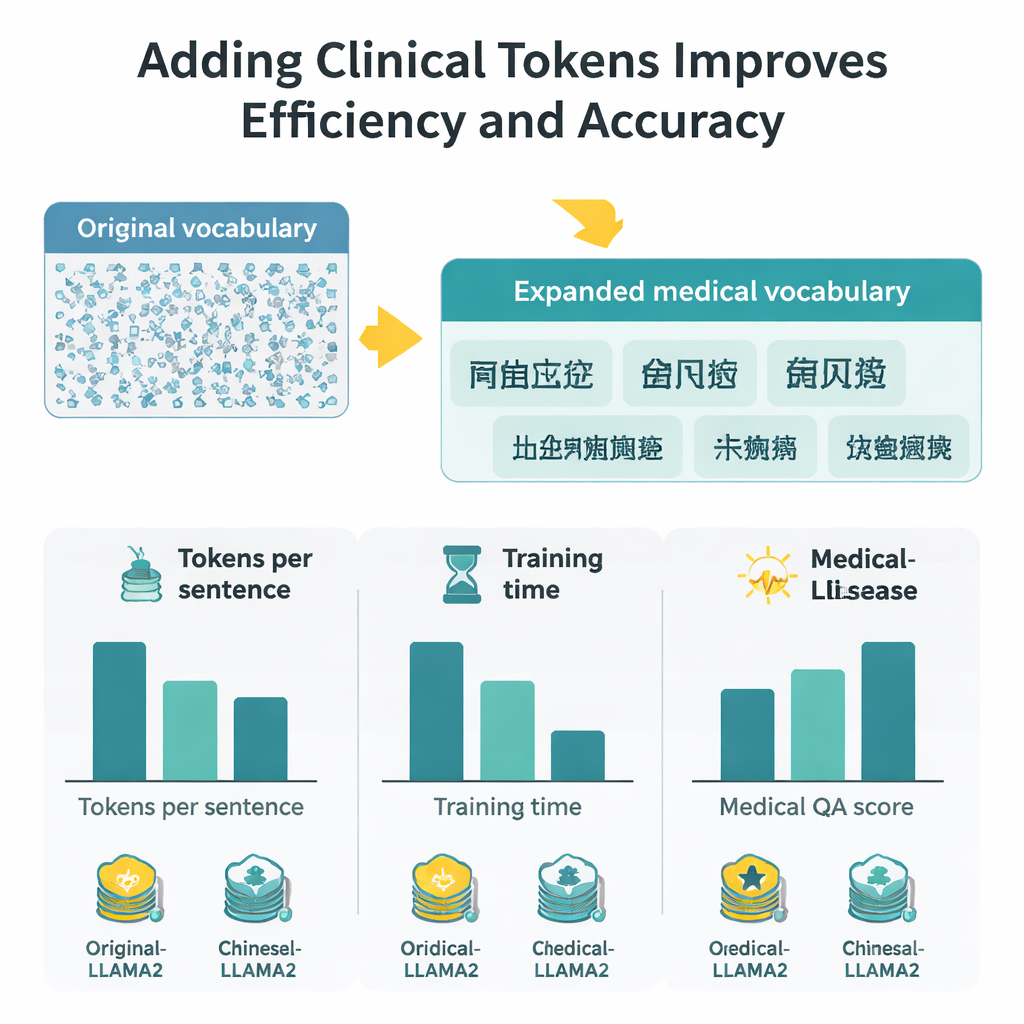
Les chercheurs se concentrent sur LLaMA2, un grand modèle de langage open source populaire, et se demandent : et si l’on enseignait simplement à son tokenizer un vocabulaire médical plus riche ? Ils rassemblent de vastes collections de textes médicaux chinois, incluant des bases de données de médecine traditionnelle chinoise soigneusement éditées, des milliers de dossiers cliniques et des paires question–réponse médecin–patient. En utilisant une version au niveau des octets de l’algorithme Byte Pair Encoding, implémentée avec l’outil SentencePiece, ils entraînent un nouveau tokenizer qui apprend à garder ensemble les expressions médicales courantes comme des unités uniques. Ces nouvelles unités, que les auteurs appellent « tokens cliniques », sont ensuite fusionnées au vocabulaire original de LLaMA2, l’élargissant pour mieux couvrir la langue médicale chinoise sans jeter ce que le modèle connaissait déjà.
De meilleurs tokens à un meilleur modèle médical
Ajouter de nouveaux tokens n’est que la première étape ; le modèle doit apprendre de bonnes représentations pour ceux-ci. L’équipe ajuste la couche d’embedding interne de LLaMA2 afin qu’elle puisse stocker des vecteurs pour le vocabulaire étendu et teste deux façons d’initialiser ces nouveaux vecteurs. Une méthode moyenne les vecteurs des anciens sous-morceaux de chaque mot, tandis que l’autre utilise des valeurs aléatoires soigneusement mises à l’échelle. Contre-intuitivement, la méthode aléatoire donne de meilleurs résultats, probablement parce qu’elle évite d’enfermer le modèle dans une mauvaise estimation initiale du sens de chaque terme. Les auteurs poursuivent ensuite l’entraînement du modèle sur des textes médicaux, puis le fine-tunent sur des Q&R médicales de style instruction à l’aide d’une méthode économe en ressources appelée LoRA, produisant une version spécialisée qu’ils nomment Medical-LLaMA.
Mesurer les gains en vitesse, contexte et précision
Avec le vocabulaire étendu, chaque caractère chinois nécessite désormais environ deux fois moins de tokens qu’avant, ce qui permet au modèle de traiter des passages plus longs dans une même fenêtre de tokens fixe. En pratique, la longueur de contexte effective pour le chinois double à peu près, et le temps de fine-tuning sur un large ensemble de Q&R médicales est réduit de près de moitié. Pour juger de la qualité des réponses, les auteurs combinent deux stratégies d’évaluation : BERTScore, qui mesure la proximité sémantique d’une réponse générée par rapport à une référence, et un modèle d’évaluation sophistiqué (DeepSeek-R1) qui note la pertinence, l’exactitude, l’exhaustivité et la fluidité. Selon ces mesures, Medical-LLaMA surpasse de manière constante à la fois LLaMA2 original et une variante optimisée pour le chinois qui n’incluait pas de tokens spécifiques au domaine médical. Il montre aussi de petites mais régulières améliorations sur des tâches connexes comme la reconnaissance d’entités médicales et la classification de textes cliniques, tout en conservant ses performances sur des questions générales non médicales.
Ce que cela signifie pour l’IA médicale future
Pour les non-spécialistes, le message clé est que de « meilleures lunettes de lecture » pour l’IA — ici, une meilleure façon de découper le langage médical — peuvent améliorer sensiblement sa compréhension et sa capacité à répondre aux questions de santé. En insérant des tokens cliniques bien choisis dans le vocabulaire d’un modèle existant, les auteurs augmentent à la fois l’efficacité et la précision sans nécessiter d’entraînements massifs nouveaux ni d’architectures complètement inédites. Bien que le travail soit limité à un modèle de 7 milliards de paramètres et à des textes médicaux chinois, il indique une recette pragmatique : adapter la couche la plus en amont du traitement du langage au domaine, puis réentraîner légèrement. Cette stratégie pourrait aider les futurs outils d’IA médicale à devenir des partenaires plus fiables pour cliniciens et patients, en particulier dans des langues et des spécialités que les modèles standard ont du mal à lire.
Citation: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Mots-clés: modèles de langage médicaux, texte clinique chinois, tokenisation, vocabulaire clinique, question-réponse médicale