Clear Sky Science · fr
AE-LFOG-YOLO : détection robuste du casque de sécurité via ancres adaptatives et apprentissage invariant à l'éclairement
Pourquoi les contrôles intelligents de casque sont importants
Sur les grands chantiers et dans les tunnels souterrains, un simple casque de sécurité peut faire la différence entre une frayeur et une blessure qui change une vie. Pourtant, dans le tumulte des chantiers réels, des personnes oublient ou évitent de porter leur casque, et les superviseurs humains ne peuvent pas surveiller chaque recoin en permanence. Cette étude explore comment construire un système caméra automatisé capable de repérer de manière fiable qui porte ou non un casque, même lorsque le tunnel est sombre, inondé d'éblouissement causé par des lampes, ou encombré de travailleurs à des distances variées par rapport à la caméra.
Les défis de la vision dans l'éclairage difficile des tunnels
Les chantiers de tunnels sont des environnements visuellement extrêmes. Des projecteurs puissants créent de l'éblouissement, tandis que des zones d'ombre profondes masquent des détails. Les personnes se rapprochent ou s'éloignent de la caméra, si bien que leurs casques apparaissent à des tailles très différentes. Les détecteurs d'intelligence artificielle standard échouent souvent dans ces conditions : ils manquent des casques dans les zones sombres, confondent d'autres objets arrondis avec des casques, ou peinent avec des travailleurs très petits ou éloignés. De nombreux systèmes existants tentent de corriger cela en éclaircissant ou en nettoyant les images avant la détection, ou en ajustant quelques composants des modèles YOLO populaires. Mais comme ces étapes sont généralement des solutions ajoutées plutôt que partie intégrante d'un même processus d'apprentissage, elles laissent des performances potentielles inexploitées et manquent de robustesse quand l'éclairage ou la configuration de la scène change.
Une nouvelle façon d'apprendre aux caméras à ignorer le mauvais éclairage
Les auteurs proposent un système amélioré appelé AE-LFOG-YOLO, construit sur le détecteur YOLOv8 largement utilisé. La première idée clé est un Module Invariant à l'Éclairement, une petite unité ajoutée à l'intérieur du réseau qui apprend à séparer « ce que fait la lumière » de « l'apparence réelle des objets ». Il scinde les cartes de caractéristiques entrantes en une partie qui reflète principalement les motifs d'éclairage et une partie qui capte des formes et textures plus stables, comme le bord courbé d'un casque. En utilisant des opérations de « gating » spéciales et une branche focalisée sur les arêtes et les angles, le module atténue les variations de luminosité et met en avant la géométrie stable. Parce que cela se produit à l'intérieur du détecteur plutôt que dans une étape de prétraitement séparée, l'ensemble du système peut être entraîné de bout en bout pour rester concentré sur les casques eux-mêmes au lieu d'être trompé par des zones d'éblouissement ou d'obscurité.
Laisser le modèle faire évoluer ses propres habitudes de vision
La deuxième idée principale porte sur la façon dont le détecteur devine où les objets peuvent apparaître. De nombreux détecteurs partent d'un ensemble fixe de « boîtes d'ancrage » qui suggèrent les tailles et formes d'objets probables ; celles-ci sont habituellement choisies une fois à partir des données d'entraînement et jamais mises à jour. Dans les tunnels, cependant, la taille apparente d'un casque peut varier considérablement selon la distance à la caméra et l'angle de vue. AE-LFOG-YOLO remplace les ancres statiques par un processus dynamique appelé Adaptive Evolutionary – Light Field Optimized Generation. À la fin de chaque cycle d'entraînement, le système perturbe légèrement ses boîtes d'ancrage, évalue à quel point elles correspondent aux casques réels de toutes tailles, et vérifie aussi si leurs dimensions ont du sens au regard des principes optiques de la caméra — combien un casque réel devrait mesurer sur le capteur à des distances de travail typiques. Les ensembles d'ancres mieux notés survivent à la ronde suivante. Au fil du temps, le détecteur « fait évoluer » des ancres qui s'ajustent aux données tout en respectant la façon dont les caméras forment réellement l'image du monde.
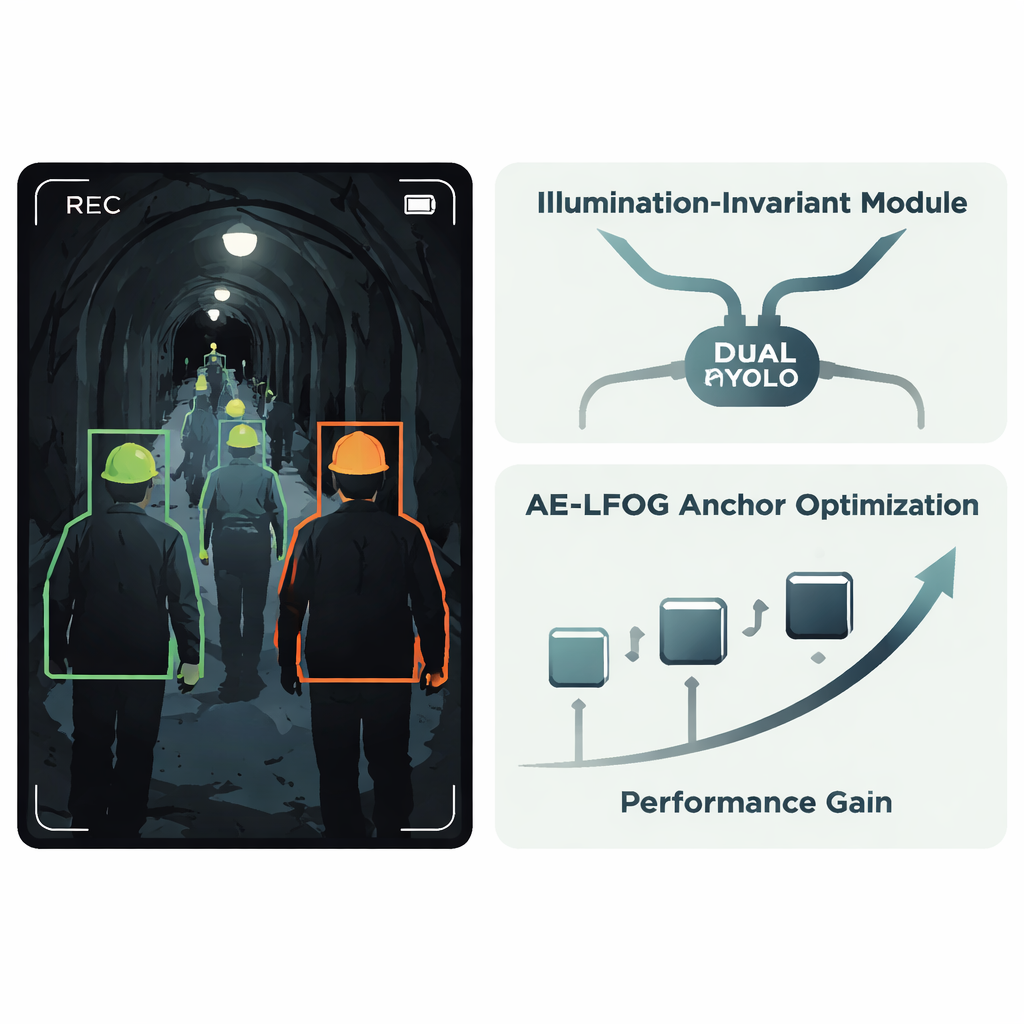
Adapter l'entraînement à la qualité réelle des images
Au-delà de modifier ce que le modèle recherche, les auteurs changent aussi la façon dont il apprend. Ils introduisent une stratégie d'entraînement qui accorde plus d'attention à la localisation précise des casques lorsque la qualité d'image est mauvaise, et plus d'attention à l'étiquetage correct casque / sans casque lorsque les conditions sont bonnes. Un score fondé sur la physique, lui aussi dérivé des principes d'imagerie des caméras, indique au système à quel point les images sont fiables à chaque étape. Si l'éclairage ou la mise au point est médiocre, le processus d'entraînement augmente automatiquement l'importance d'obtenir des boîtes englobantes correctes ; si les conditions s'améliorent, il privilégie la classification. Cela crée une boucle de rétroaction dans laquelle le modèle ajuste continuellement ses priorités pour correspondre à l'environnement physique qu'il rencontrera dans de vrais tunnels.
Ce que montrent les tests en pratique
Les chercheurs testent leur approche sur un jeu de données réel de casques de sécurité en tunnel et la comparent à plusieurs méthodes avancées basées sur YOLO. AE-LFOG-YOLO détecte les casques avec une très grande précision, identifiant correctement environ 95 % des casques à un seuil d'intersection standard et surpassant la base YOLOv8 de référence tant en précision qu'en rappel. Il fonctionne à une vitesse suffisante pour un usage en temps réel et se révèle particulièrement performant lorsque l'éclairage est fortement manipulé pour simuler une obscurité extrême ou une surexposition. Dans ces conditions difficiles, le nouveau modèle maintient une confiance plus élevée, détecte davantage de travailleurs petits et éloignés, et opère sur une plage de luminosité supérieure d'un tiers environ par rapport à la référence, ce qui signifie qu'il reste fiable dans un ensemble beaucoup plus large de scènes réelles.
Comment cela contribue à la sécurité des travailleurs
Pour les non‑spécialistes, la conclusion est simple : en apprenant à un système d'IA à comprendre non seulement les pixels mais aussi la physique de la façon dont les caméras voient dans des environnements difficiles, ce travail fournit un observateur plus intelligent et plus fiable sur la paroi du tunnel. AE-LFOG-YOLO peut mieux ignorer les éclairages trompeurs et s'adapter aux changements de point de vue, réduisant les détections manquées et les fausses alertes. Déployé pendant des mois sur une ligne de transport ferroviaire en exploitation, il a déjà montré qu'il peut aider les équipes de sécurité à s'assurer que les travailleurs gardent leurs casques, offrant une étape pratique vers des chantiers de construction plus sûrs et mieux surveillés.
Citation: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Mots-clés: détection de casque de sécurité, construction de tunnel, vision par ordinateur, imagerie en faible luminosité, YOLOv8