Clear Sky Science · fr
Application de l’apprentissage contrastif auto-supervisé hiérarchique à l’adaptation de domaine pour l’alignement d’images de télédétection multimodales
Voir la Terre avec des yeux différents
Les satellites météorologiques, les missions radar et les caméras spatiales haute résolution observent tous la même planète mais d’une manière très différente. Cette diversité est un atout pour des tâches comme le suivi des inondations, la cartographie urbaine ou la surveillance des forêts — à condition de pouvoir aligner les images de façon fiable. L’article résumé ici présente une nouvelle méthode d’intelligence artificielle qui apprend aux ordinateurs à faire correspondre ces vues très hétérogènes de la Terre plus précisément et avec beaucoup moins d’annotations humaines, ouvrant la voie à une surveillance environnementale plus rapide et plus robuste.
Pourquoi il est si difficile d’aligner des images différentes
Les images de télédétection proviennent de capteurs très variés : des caméras optiques qui voient comme nos yeux, des systèmes radar qui mesurent la rugosité de la surface, et des instruments multispectraux qui saisissent de subtiles différences de couleur. Comme chaque capteur « voit » à sa manière, un même bâtiment, navire ou champ peut apparaître complètement différent d’une image à l’autre — granuleux en radar, net en optique, ou teinté de couleurs inhabituelles en multispectral. Les méthodes classiques d’appariement reposent soit sur des caractéristiques visuelles conçues à la main, soit sur de l’apprentissage profond entièrement supervisé nécessitant d’énormes jeux de données étiquetées. Les deux approches échouent souvent lorsque l’écart d’apparence entre capteurs est important ou lorsque les exemples étiquetés sont rares, comme c’est fréquemment le cas lors de catastrophes ou dans des zones reculées.
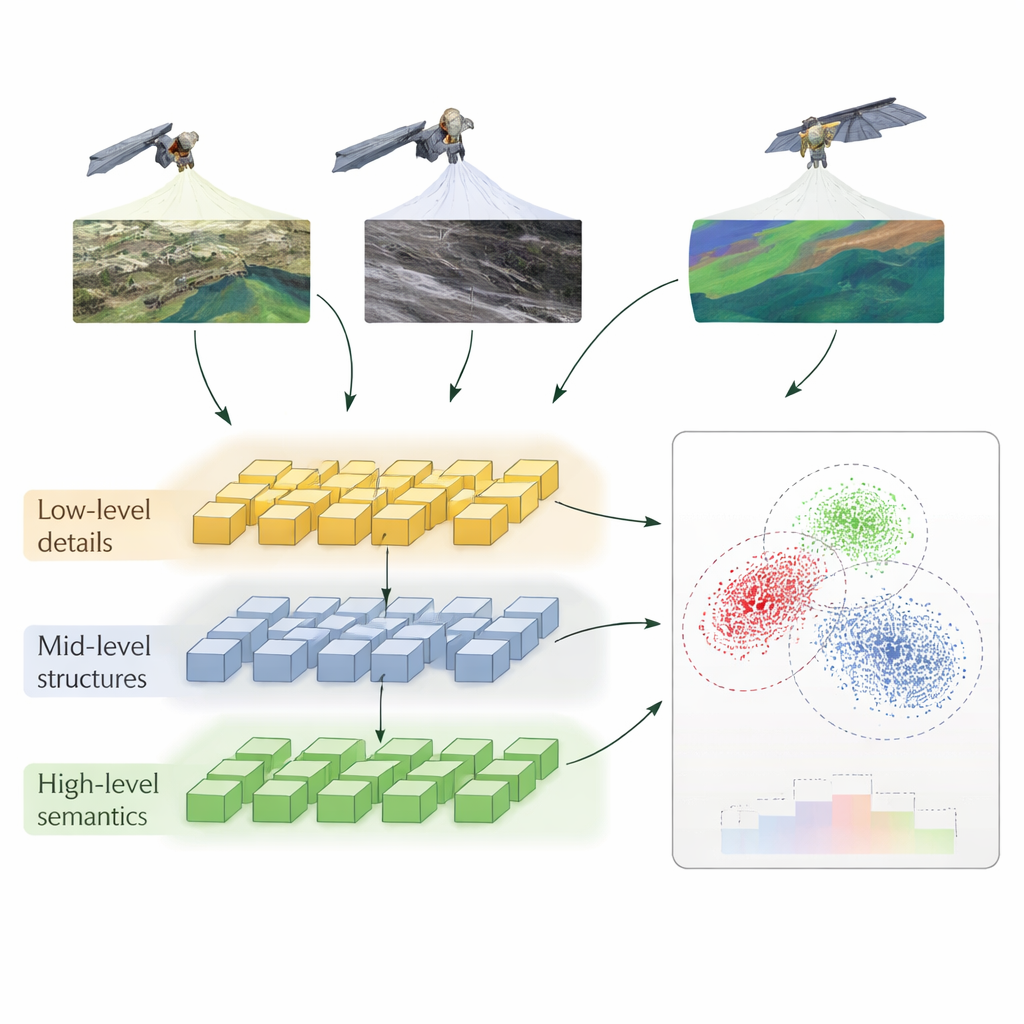
Une manière en couches d’apprendre à comparer
Les auteurs proposent une méthode nommée apprentissage contrastif auto-supervisé hiérarchique (HSSCL), qui change la façon dont un réseau neuronal apprend à comparer des images. Plutôt que de ne considérer qu’un résumé unique de chaque image, le réseau extrait des informations à trois niveaux : les détails fins comme les contours et les textures, les motifs d’échelle moyenne comme les routes et les contours de bâtiments, et les structures larges comme l’organisation urbaine ou les types d’occupation du sol. À chaque niveau, le système incite les descripteurs issus de capteurs différents mais représentant la même zone à se rapprocher, tout en éloignant les descripteurs provenant de zones non liées. Cet entraînement « contrastif » se fait sans étiquettes humaines : le modèle utilise l’appariement connu d’images issues de capteurs différents sur un même emplacement, ainsi que des exemples similaires trouvés automatiquement, pour construire une notion riche de ce que « le même lieu » signifie across les modalités.
Éliminer le bruit et préserver la géométrie
Les données de télédétection réelles sont désordonnées — les images radar contiennent un bruit de speckle, les images optiques peuvent être brumeuses, et toutes peuvent être mal alignées de quelques pixels. HSSCL traite cela en divisant d’abord les images en petits blocs et en appliquant un débruitage adapté, ce qui aide le réseau à se concentrer sur la structure significative plutôt que sur des fluctuations aléatoires. Il alimente ensuite les caractéristiques extraites des différents blocs dans un module basé sur un graphe qui considère chaque région comme un nœud et relie les régions qui sont proches et visuellement similaires. En opérant sur ce graphe, un réseau de neurones graphes spécialisé renforce la cohérence géométrique des appariements, augmentant la probabilité que les routes s’alignent avec des routes et les bâtiments avec des bâtiments, même dans des conditions difficiles.
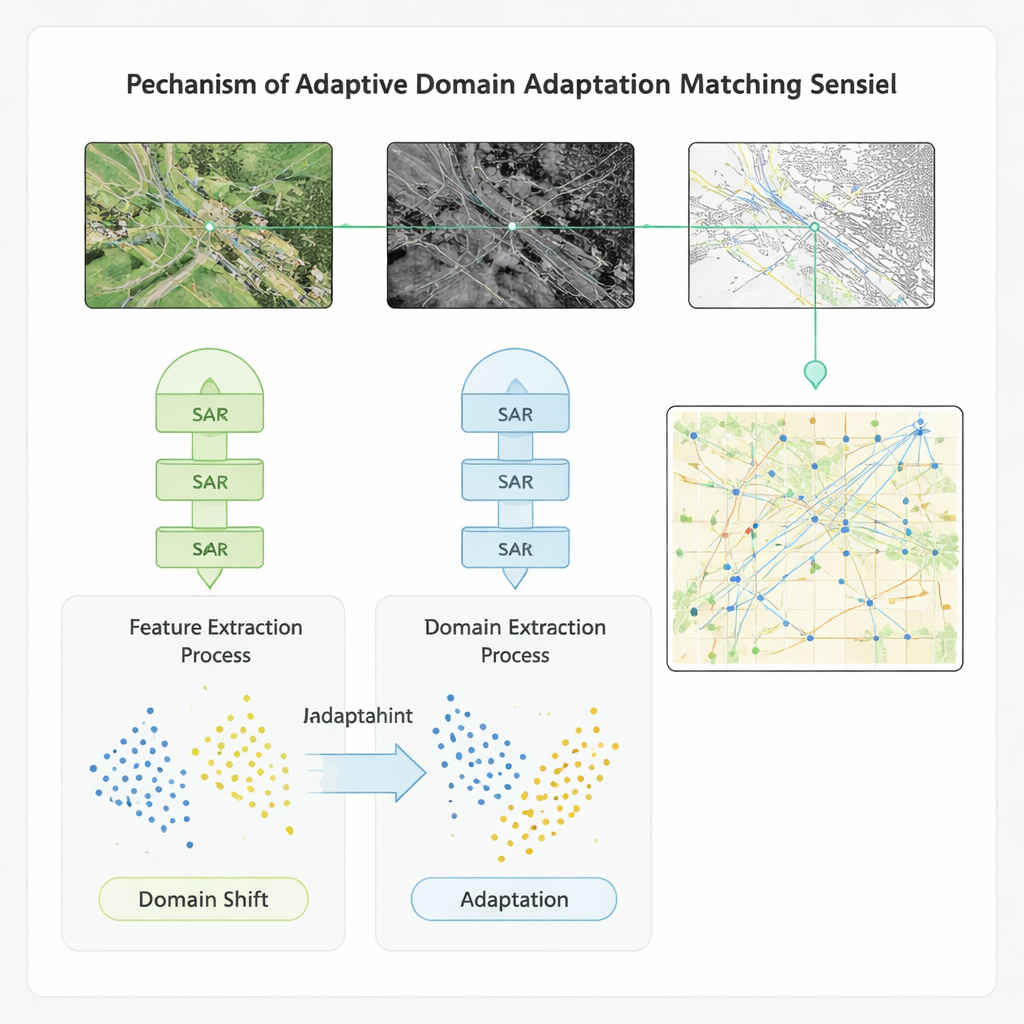
S’adapter entre jeux de données et conditions
Pour garantir que la méthode fonctionne au-delà d’un seul jeu de référence, les auteurs intègrent leur schéma d’apprentissage dans un modèle d’adaptation de domaine. Ce composant réduit explicitement l’écart entre les propriétés statistiques des caractéristiques issues de capteurs et de jeux de données différents, afin qu’un modèle entraîné sur une région ou un instrument puisse être appliqué à une autre avec une perte minimale de précision. Testée sur quatre jeux de données publics comprenant de l’imagerie multispectrale globale, des paires radar-optique haute résolution, des scènes d’occupation du sol et des images de navires, la nouvelle approche surpasse plusieurs références avancées. Elle améliore la précision, le rappel et le score F1 d’environ 20 points de pourcentage, accélère l’appariement de plus de 20 % et accroît la précision de détection de défauts de type vidéo — important pour surveiller les changements au fil du temps — de plus de 40 %. La méthode montre aussi une plus grande résilience au bruit et aux décalages entre les conditions d’entraînement et de déploiement.
Ce que cela signifie pour la surveillance opérationnelle
Pour un public non spécialiste, l’étude montre comment on peut entraîner des ordinateurs à reconnaître « c’est le même endroit » à travers des images qui ne se ressemblent pas du tout pour l’œil humain. En apprenant à plusieurs niveaux de détail, en supprimant le bruit et en s’adaptant explicitement à de nouveaux capteurs et territoires, la méthode HSSCL facilite la fusion de nombreux flux de données satellitaires en une image cohérente. Cela peut aider les secours à aligner plus rapidement images radar et optiques après une tempête, aider les urbanistes à suivre l’évolution des villes ou des forêts sur plusieurs années, et soutenir le suivi continu des navires en mer. Bien que les auteurs soulignent que le bruit extrême et les distorsions très importantes restent des défis, leur travail offre une voie prometteuse et pratique vers un appariement plus rapide et plus fiable des multiples « yeux » que nous avons en orbite.
Citation: Li, Y., Luo, Z., Zhu, G. et al. Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image. Sci Rep 16, 6445 (2026). https://doi.org/10.1038/s41598-026-37312-5
Mots-clés: télédétection, imagerie multimodale, apprentissage auto-supervisé, apprentissage contrastif, adaptation de domaine