Clear Sky Science · fr
Évaluation des performances d’un transformeur génératif pré-entraîné lors de l’examen national d’obtention du diplôme vétérinaire au Japon
Pourquoi des examens vétérinaires plus exigeants nous concernent tous
Derrière chaque visite à l’hôpital pour animaux se cachent des années de formation rigoureuse et un examen national à fort enjeu. Au Japon, les futurs vétérinaires doivent réussir l’Examen National d’Habilitation Vétérinaire (NVLE), qui couvre tout, de la biologie de base au jugement clinique complexe. Cette étude pose une question d’actualité : les modèles de langage artificiels avancés d’aujourd’hui, du même type que ceux qui alimentent les chatbots populaires, peuvent‑ils résoudre cet examen exigeant en japonais — et quelles pourraient être les conséquences pour l’enseignement vétérinaire et les soins aux animaux ?
Évaluer l’IA sur un véritable examen vétérinaire
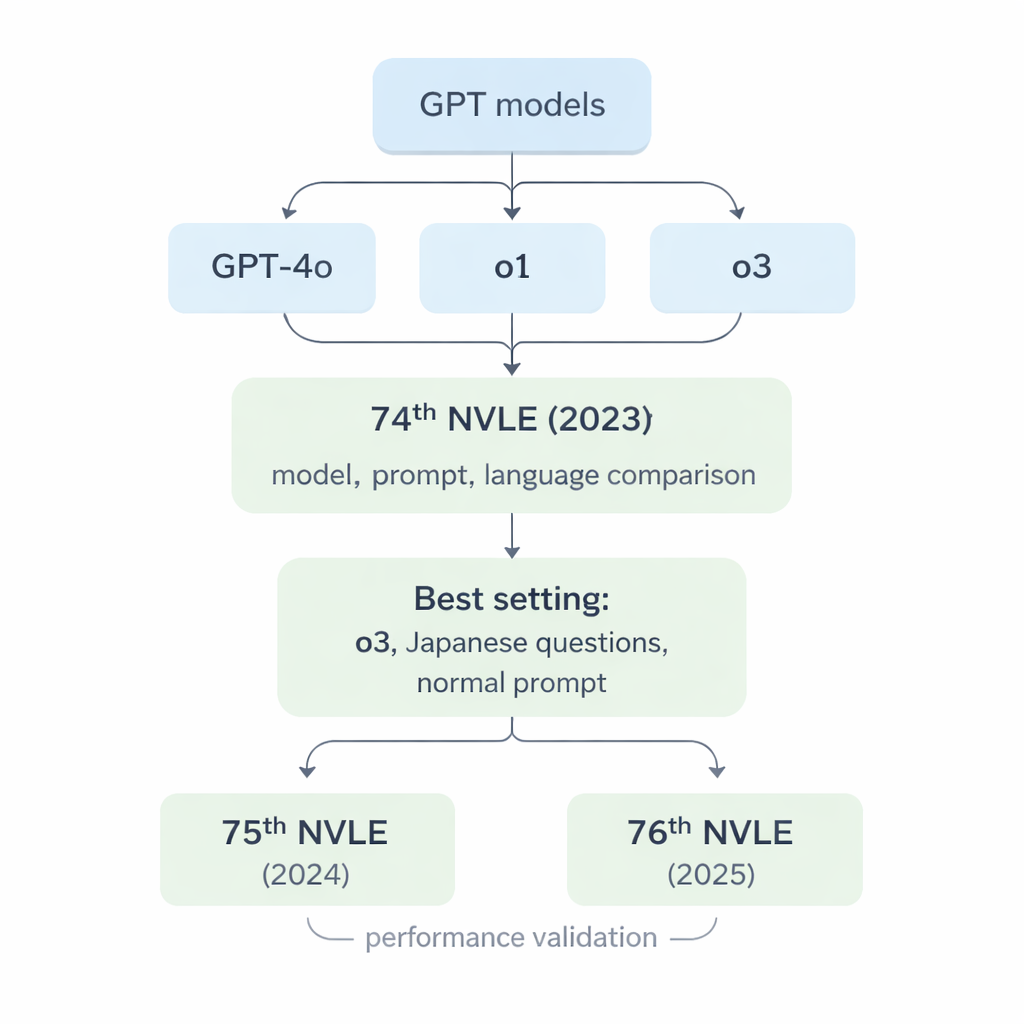
Les chercheurs se sont focalisés sur trois générations de grands modèles de langage d’OpenAI : GPT‑4o, o1 et o3. Ces systèmes sont conçus pour lire et générer un texte de type humain, mais ils n’ont jamais été entraînés spécifiquement pour la médecine vétérinaire. Pour les mettre à l’épreuve, l’équipe a utilisé la 74e session du NVLE au Japon (2023) comme référence. L’examen est divisé en cinq sections, comprenant des questions uniquement textuelles et des questions comportant des images montrant des radiographies, des photos ou des schémas. Toutes les questions sont à choix multiple avec cinq options, exactement comme l’examen réel passé par les étudiants. Les modèles ont reçu chaque question via un script informatique standardisé et devaient répondre uniquement en indiquant le numéro de l’option choisie, sans possibilité « d’expliquer » ni de négocier pour obtenir les points.
Quel modèle d’IA est arrivé en tête ?
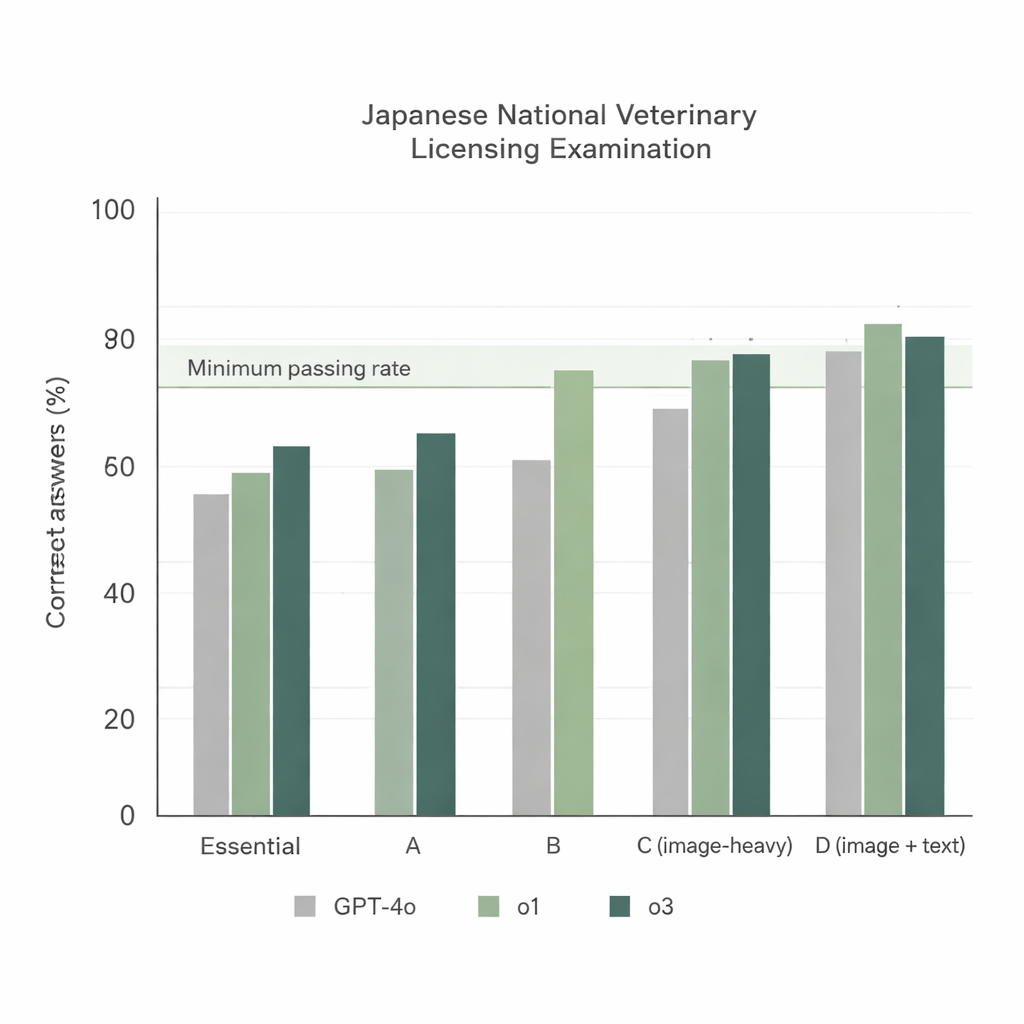
Lorsque les trois modèles ont affronté la 74e session du NVLE avec la configuration la plus simple — questions en japonais et consigne d’instruction directe — deux tendances nettes sont apparues. Premièrement, tous les modèles ont bien performé sur les sections textuelles, mais o1 et o3 ont systématiquement surpassé GPT‑4o. Deuxièmement, les performances ont diminué pour les sections riches en images, toutefois o1 et o3 sont restés au‑dessus du taux de réussite minimal officiel, alors que GPT‑4o a échoué dans l’une de ces sections. Globalement, GPT‑4o a répondu correctement à environ 78 % des questions, tandis que o1 a atteint environ 92 % et o3 environ 93 %. Comme o3 devance légèrement o1 au score total, les chercheurs ont choisi o3 pour le reste des expériences.
Les consignes ou les traductions aident‑elles vraiment ?
On a beaucoup écrit sur le « prompt engineering » — l’art de formuler des instructions élaborées pour obtenir de meilleures réponses de l’IA — et sur la pratique de traduire des questions locales en anglais pour les rapprocher des données d’entraînement des modèles. L’étude a testé directement ces idées avec le modèle o3, en comparant une consigne de résolution basique à une consigne plus détaillée et optimisée, et les questions japonaises originales à des versions d’abord traduites en anglais par le même modèle. De manière surprenante, aucune de ces modifications n’a apporté de différence significative : o3 a réussi confortablement dans les six combinaisons, et l’approche la plus simple (texte japonais original avec la consigne basique) a fonctionné aussi bien que les configurations plus compliquées. Cela suggère que, au moins pour ces questions vétérinaires, les modèles récents comprennent déjà le japonais de façon fiable et n’ont pas besoin de prompts sophistiqués pour atteindre un niveau élevé de performance.
Quelle stabilité des performances sur des examens plus récents ?
Pour vérifier si ces bons résultats étaient fortuits, l’équipe a ensuite soumis o3 aux 75e (2024) et 76e (2025) sessions du NVLE, en utilisant encore une fois seulement les questions japonaises originales et la consigne normale. Le modèle a obtenu des scores globaux supérieurs à 92 % sur les deux examens et a dépassé le seuil de réussite dans chaque section, y compris les domaines riches en images. La plupart des questions ont reçu la même réponse sur trois exécutions indépendantes, montrant que les réponses d’o3 étaient généralement stables même lorsque l’on laissait une part d’aléa. En examinant de près les erreurs du modèle, les chercheurs ont constaté que les fautes se regroupaient dans deux domaines : les connaissances vétérinaires pratiques (comme la législation vétérinaire japonaise) et la médecine clinique, qui exigent des règles spécifiques au pays et un raisonnement en plusieurs étapes plutôt qu’un simple rappel de faits.
Ce que cela signifie — et ce que cela ne signifie pas
L’étude conclut que les modèles de type GPT de pointe peuvent désormais réussir l’examen d’aptitude vétérinaire japonais en japonais, sans astuces de traduction ni consignes complexes. Pour les écoles vétérinaires et les étudiants, cela ouvre la porte à l’utilisation de l’IA comme partenaire d’étude, générateur de questions ou explicateur de sujets d’examen. Pour le grand public, cela indique que l’IA devient un outil puissant pour organiser et diffuser les connaissances vétérinaires. Cependant, les auteurs insistent sur le fait que ces systèmes ne sont pas prêts à remplacer les vétérinaires ni à prendre des décisions médicales de manière autonome. Les modèles peuvent encore mal interpréter des images, éprouver des difficultés avec des jugements cliniques nuancés et parfois inventer des faits. Utilisés avec précaution, ils peuvent devenir des assistants précieux pour l’enseignement vétérinaire et le soutien informationnel — mais la responsabilité de la santé animale restera fermement entre les mains des humains.
Citation: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Mots-clés: examens de licence vétérinaire, grands modèles de langage, intelligence artificielle en médecine, performance de GPT, formation vétérinaire au Japon