Clear Sky Science · fr
L’impact du choix de K dans la validation croisée K‑fold sur le biais et la variance des modèles d’apprentissage supervisé
Pourquoi vérifier votre modèle deux fois compte vraiment
De la diagnostic médical à l’évaluation de solvabilité, de nombreuses décisions reposent aujourd’hui sur des modèles d’apprentissage automatique entraînés sur des données passées. Mais comment savoir si un modèle qui semble performant sur notre écran se comportera bien face à de nouveaux cas inconnus ? Une méthode courante pour « tester » les modèles s’appelle la validation croisée k‑fold, où les données sont récurrentement réparties en blocs d’entraînement et de test. Cette étude pose une question apparemment simple mais essentielle : combien de blocs — quelle valeur de k — doit‑on choisir, et comment ce choix influence‑t‑il silencieusement la fiabilité des performances rapportées du modèle ?
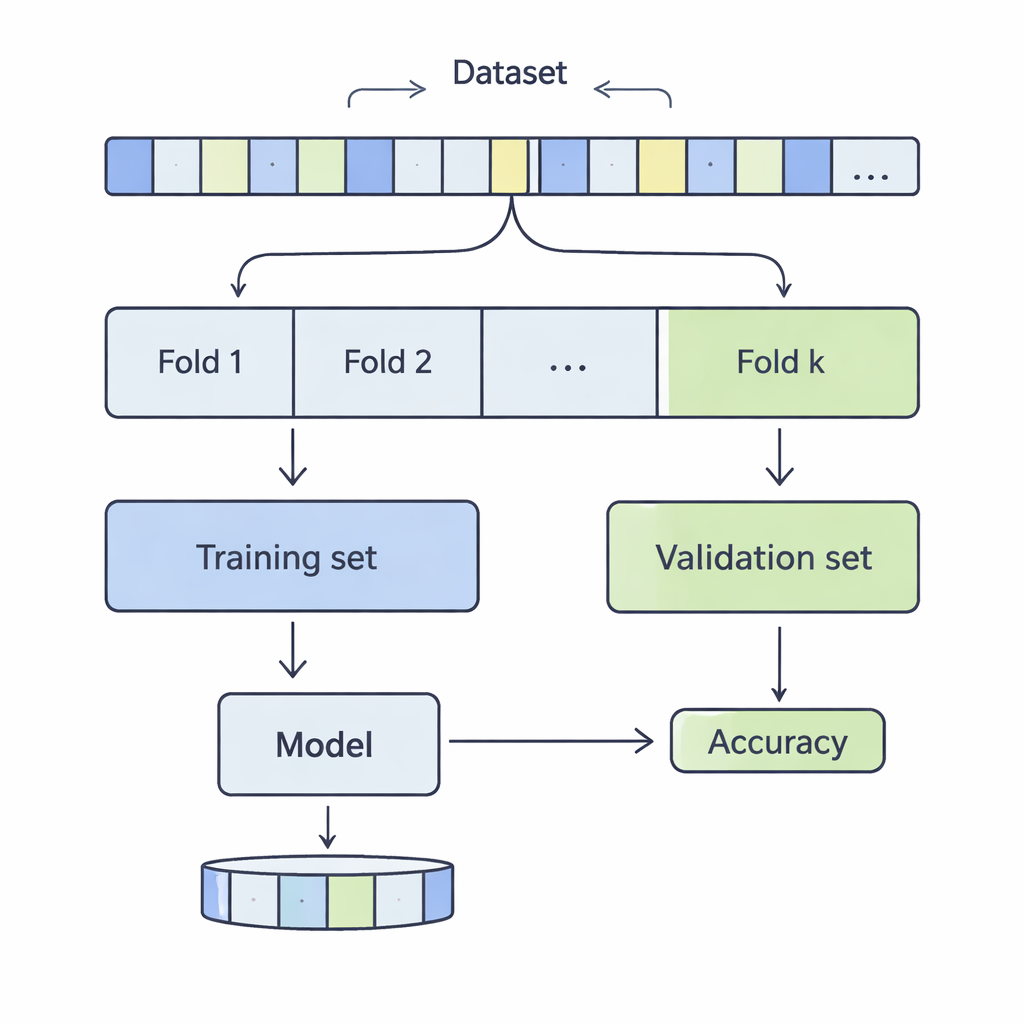
Comment les données sont découpées pour un contrôle de réalité
Dans la validation croisée k‑fold, un jeu de données est mélangé puis divisé en k parties égales, ou folds. Le modèle est entraîné sur k‑1 de ces folds et évalué sur le fold restant ; ce processus est répété jusqu’à ce que chaque fold ait servi de portion de test. Les auteurs ont étudié des valeurs de k comprises entre 3 et 20, sur 12 jeux de données réels allant de quelques milliers à plus d’un demi‑million d’enregistrements, couvrant des domaines tels que la prédiction de revenu, les résultats médicaux, les cyberattaques, les jeux et la qualité du vin. Ils ont appliqué quatre méthodes de classification courantes — machines à vecteurs de support, arbres de décision, régression logistique et k‑plus proches voisins — et ont mesuré avec soin comment le choix de k affectait deux aspects clés de la performance : le biais et la variance.
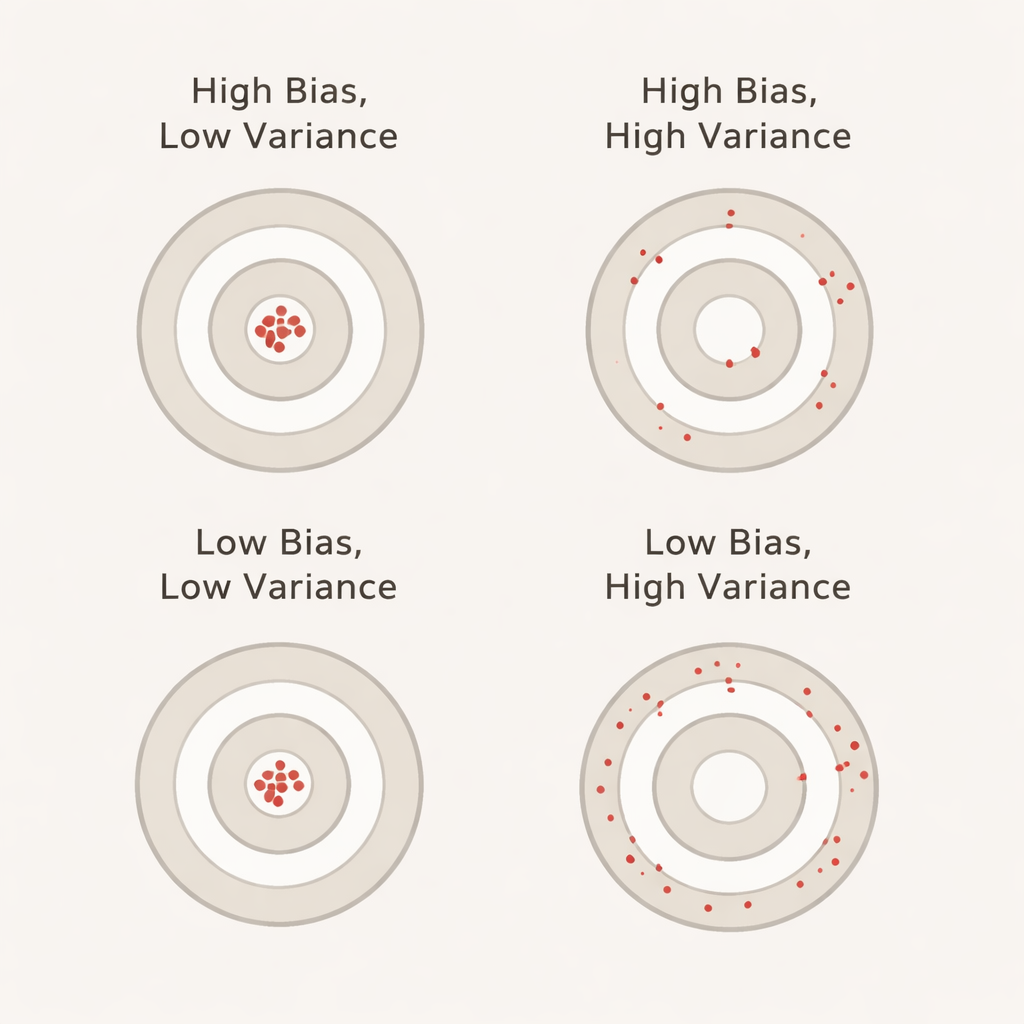
Ce que biais et variance signifient en termes quotidiens
Le biais, dans ce contexte, mesure à quel point le modèle semble mieux fonctionner pendant la validation croisée qu’il ne le fait réellement sur un ensemble de test distinct et non utilisé. Un biais positif important signifie que le modèle paraît excessivement optimiste lors de la validation — similaire à un étudiant qui réussit les tests d’entraînement mais échoue à l’examen réel. La variance reflète la fluctuation des performances du modèle d’un fold à l’autre : une faible variance signifie que ses scores sont stables à travers différentes découpes des données, tandis qu’une forte variance signifie qu’ils varient beaucoup. Idéalement, on recherche à la fois un faible biais et une faible variance pour que la précision rapportée soit à la fois réaliste et stable.
Ce qui se passe quand on augmente le nombre de folds
Sur les douze jeux de données et avec les quatre algorithmes, un motif s’est nettement dégagé : à mesure que k augmentait, la variance augmentait presque toujours. Autrement dit, utiliser plus de folds rendait la précision rapportée moins stable d’un fold à l’autre. Cela contredit une croyance répandue selon laquelle davantage de folds offrirait automatiquement des estimations meilleures et plus fiables. La raison est que, lorsque k est grand, chaque portion de validation devient très petite et moins représentative, rendant les résultats plus sensibles aux particularités des données. En parallèle, le comportement du biais était moins uniforme. Pour k‑plus proches voisins et les machines à vecteurs de support, le biais avait tendance à augmenter avec k, ce qui signifie que ces modèles semblaient souvent plus précis en validation croisée qu’ils ne l’étaient sur l’ensemble de test retenu. Les arbres de décision montraient des tendances globalement équilibrées, et la régression logistique se situait entre les deux, avec des variations de biais plus mixtes mais modérées.
Pourquoi les « paramètres standards » peuvent induire en erreur
La plupart des guides pratiques recommandent simplement d’utiliser cinq ou dix folds, indépendamment du jeu de données ou de l’algorithme d’apprentissage. L’analyse des auteurs montre que ce conseil universel peut être trompeur. Sur certains jeux de données et pour certains modèles, des valeurs élevées de k amplifiaient des impressions trop optimistes des performances ; sur tous les jeux, davantage de folds entraînait une plus grande variabilité des estimations. Cela est particulièrement préoccupant dans des domaines à enjeux élevés comme la santé, la finance ou les infrastructures, où une confiance excessive dans la précision d’un modèle peut avoir des conséquences réelles. L’étude soutient que les effets de k dépendent à la fois de la nature des données (petites vs. grandes, bruitées vs. plus propres) et de la manière dont l’algorithme apprend à partir d’ensembles d’entraînement répétés et presque identiques.
Message clé pour quiconque utilise l’apprentissage automatique
La leçon centrale est que le nombre de folds dans la validation croisée n’est pas un détail technique sans conséquence — il façonne directement la confiance que l’on peut accorder à vos chiffres de précision. Dans ces expériences, davantage de folds rendaient systématiquement les résultats plus instables et faisaient souvent paraître certains modèles meilleurs qu’ils ne l’étaient en réalité. Plutôt que de choisir aveuglément k=5 ou k=10, les auteurs recommandent de traiter k comme un paramètre à ajuster : vérifiez comment les résultats évoluent sur une petite plage de valeurs de k et, dans la mesure du possible, examinez plus d’une métrique de performance. Pour les praticiens comme pour les lecteurs intéressés, le message est clair : en matière d’évaluation des modèles d’apprentissage automatique, la façon dont vous découpez les données peut importer presque autant que le modèle lui‑même.
Citation: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Mots-clés: validation croisée k‑fold, compromis biais‑variance, évaluation de modèle, validation en apprentissage automatique, classification supervisée