Clear Sky Science · fr
Une nouvelle approche hybride pour la prévision des sécheresses : tirer parti de l’ingénierie des caractéristiques et des méthodes d’ensemble
Pourquoi prévoir les périodes sèches est important
Les sécheresses s’installent progressivement mais peuvent dévaster les récoltes, les réserves d’eau potable et des économies locales entières. À mesure que le changement climatique rend le temps plus erratique, les communautés ont besoin d’alertes précoces qui dépassent de simples estimations des précipitations. Cet article présente une nouvelle façon de prévoir l’intensité des sécheresses en combinant de manière intelligente des méthodes mathématiques et d’apprentissage automatique pour fournir aux agriculteurs et aux planificateurs une vision plus claire de l’avenir.
Des cieux changeants aux signaux exploitables
L’étude part d’une réalité simple : le climat actuel est chaotique. Les variations de température, les vents changeants et les précipitations inégales ne suivent plus des schémas statistiques nets. Les outils de prévision traditionnels peinent face à cette complexité. Les auteurs exploitent donc de larges ensembles de données météorologiques et de paysage, incluant les précipitations, la température, l’humidité, le vent, l’altitude, la pente, la qualité des sols et un indice de santé de la végétation. Leur objectif est de transformer ces chiffres bruts en un ensemble réduit de signaux puissants décrivant la proximité d’une région à différents niveaux de sécheresse, allant de conditions saines à un déficit hydrique extrême.
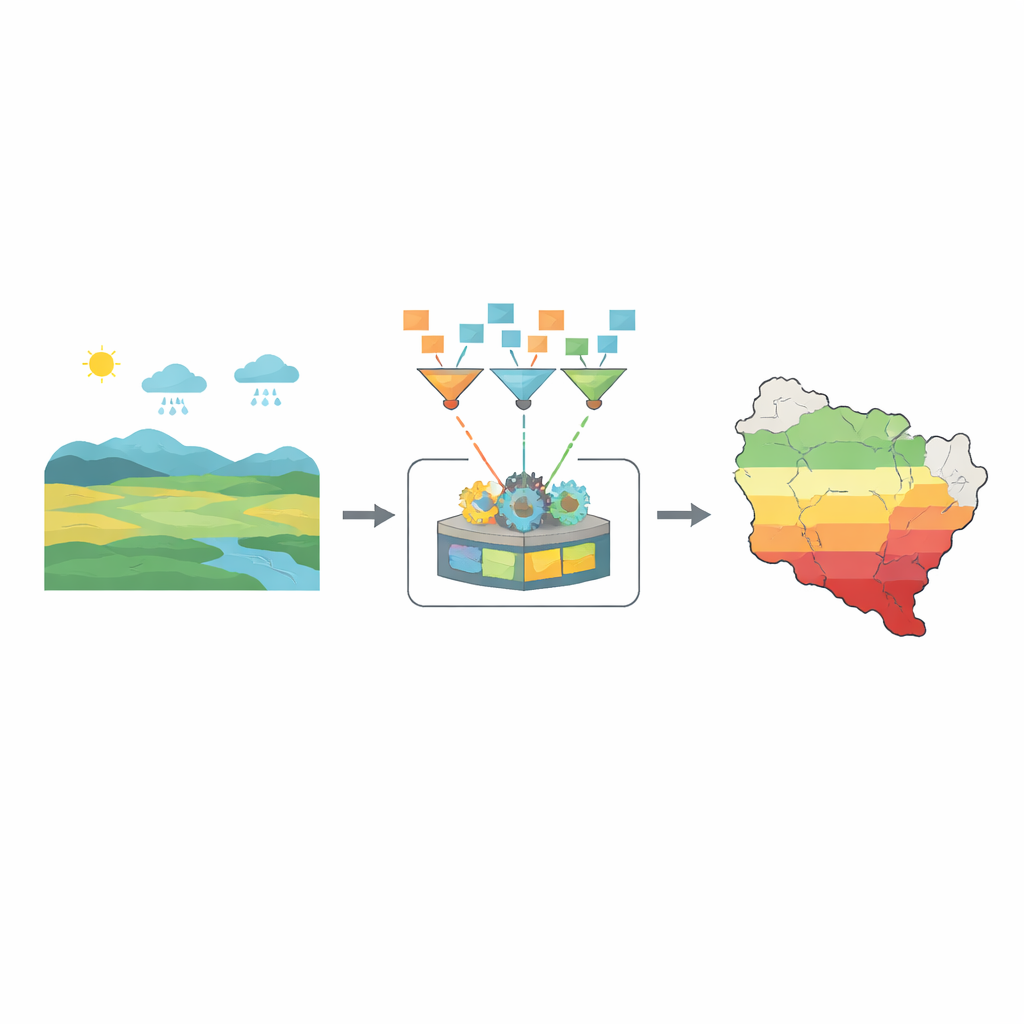
Choisir les quelques chiffres qui comptent vraiment
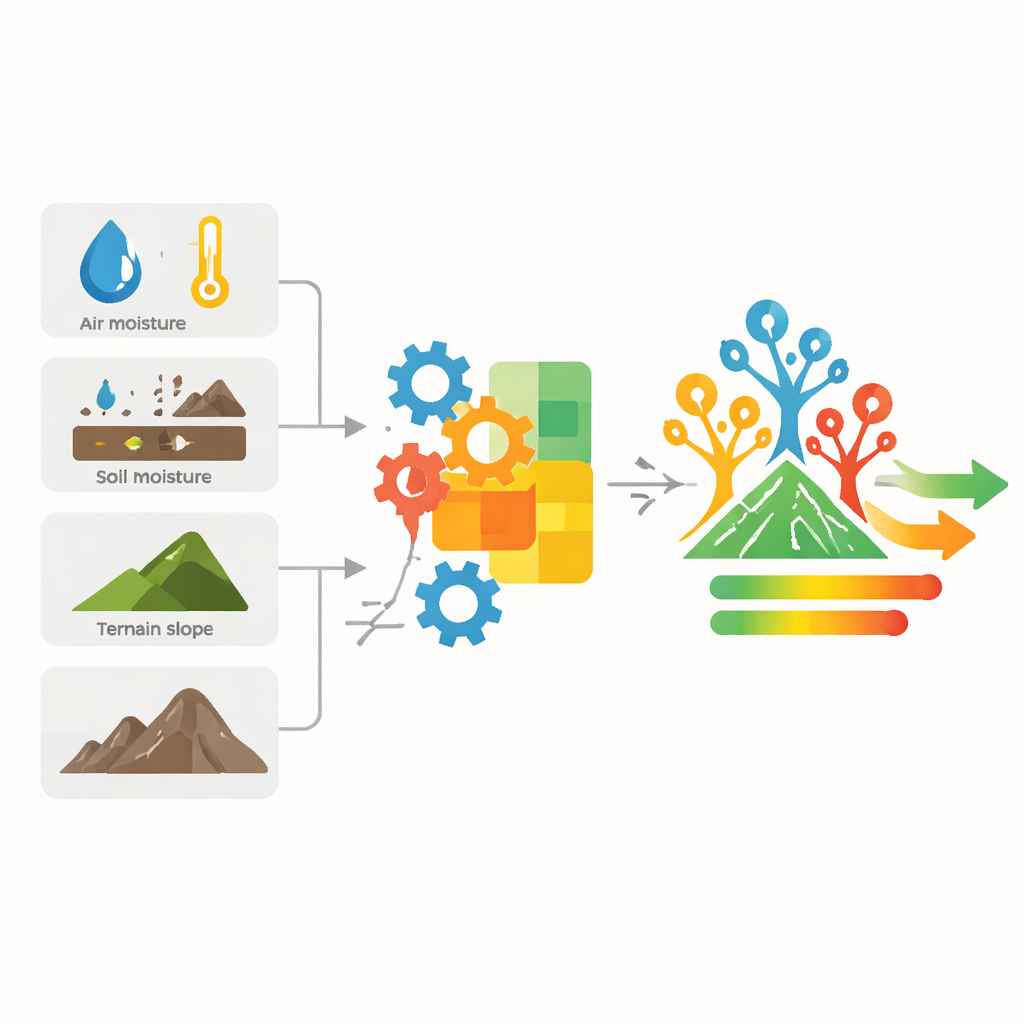
Chaque mesure n’est pas également utile. Les noms de pays ou les codes administratifs, par exemple, expliquent peu pourquoi la végétation se dessèche. L’équipe nettoie d’abord les données, puis utilise une analyse de corrélation pour identifier les facteurs qui évoluent ensemble et ceux qui aident réellement à distinguer périodes humides et périodes sèches. Ils constatent que certaines caractéristiques se détachent : un indice de végétation, l’inclinaison du terrain dans une direction donnée et trois températures d’air liées à l’humidité près du sol. Ces ingrédients soigneusement choisis constituent l’ossature du système de prévision.
Transformer les données brutes en empreintes de sécheresse
Plutôt que d’alimenter directement ces cinq variables dans un algorithme, les auteurs conçoivent de nouvelles mesures combinées qui reflètent le comportement réel de la sécheresse dans la nature. Ils construisent des formules simples mais significatives — n’utilisant que des opérations familières comme l’addition, la multiplication, les racines carrées et les logarithmes — pour capter des notions telles que la sécheresse globale, l’effet bénéfique des pluies récentes, la vitesse à laquelle la chaleur pousse vers des conditions de sécheresse, la quantité d’eau restante dans le sol et l’équilibre entre l’eau gagnée et perdue par évaporation. Chaque formule produit un nouvel indice agissant comme une empreinte de la pression de sécheresse actuelle pour chaque lieu et chaque semaine du jeu de données.
Laisser une forêt de décisions voter sur le résultat
Ces indices ingénierés sont ensuite fournis à une méthode d’apprentissage automatique appelée forêt aléatoire (random forest). Plutôt qu’une seule règle de décision, cette approche fait croître de nombreux arbres de décision simples, chacun voyant une tranche légèrement différente des données. Chaque arbre donne son avis sur le niveau de sécheresse auquel appartient une situation, et la réponse finale de la forêt repose sur le vote majoritaire. En réglant le nombre d’arbres et la profondeur des scissions, les auteurs identifient un compromis où le modèle est à la fois précis et résistant au surapprentissage. Sur des données de test non utilisées lors de l’entraînement, leur système hybride classe correctement le niveau de sécheresse dans presque tous les cas et fait beaucoup moins d’erreurs que des outils plus classiques comme k-plus proches voisins, les machines à vecteurs de support ou une régression logistique basique.
Ce que cela change sur le terrain
Pour un public non spécialiste, le message clé est qu’un petit ensemble d’indicateurs bien conçus, ancrés dans le comportement réel de la chaleur et de l’humidité, peut alimenter un système d’alerte précoce très fiable. En combinant des équations simples avec une méthode d’apprentissage basée sur le vote, le modèle atteint une très grande précision tout en restant relativement léger à exécuter et plus facile à interpréter que de nombreux « boîtes noires » de l’apprentissage profond. S’il est adopté et adapté aux données locales, cette approche hybride pourrait aider les agriculteurs à ajuster les calendriers de semis, les gestionnaires de l’eau à planifier stockage et lâchers, et les agences de secours à se préparer à l’aggravation des périodes sèches avant qu’elles ne dégénèrent en crises majeures.
Citation: Charjan, O., Gajbhiye, K., Warhade, J. et al. A Novel Hybrid Approach To Drought Forecasting: Leveraging Feature Engineering And Ensemble Methods. Sci Rep 16, 7972 (2026). https://doi.org/10.1038/s41598-026-37206-6
Mots-clés: prévision des sécheresses, risque climatique, apprentissage automatique, agriculture, systèmes d’alerte précoce