Clear Sky Science · fr
Analyse comparative des modèles supervisés et d’ensembles avec exploration non supervisée pour la prédiction de la maladie d’Alzheimer
Pourquoi l’alerte précoce est importante
La maladie d’Alzheimer dépouille lentement les personnes de leur mémoire et de leur autonomie, souvent bien avant qu’un diagnostic ferme ne soit posé. Les familles, les médecins et les systèmes de santé bénéficient tous d’une détection précoce des signes d’alerte, car c’est à ce moment-là que les traitements, la planification et le soutien peuvent avoir le plus d’impact. Cette étude pose une question pragmatique : des programmes informatiques soigneusement conçus, entraînés sur des données cliniques routinières et des images cérébrales, peuvent-ils repérer la démence de façon plus fiable que les outils standards actuels — et, en même temps, révéler des motifs cachés dans le développement de la maladie ?
Transformer les dossiers patients en signaux exploitables
Les chercheurs se sont appuyés sur une collection de données bien connue, OASIS-2, qui suit 150 personnes âgées de 60 à 96 ans sur plusieurs années. Pour chaque visite, l’ensemble contient des informations de base comme l’âge, les années d’études et le statut socioéconomique, ainsi que des scores de tests cognitifs et des mesures dérivées d’IRM cérébrales, comme le volume cérébral global. Avant toute prédiction, l’équipe a nettoyé les données, supprimé les identifiants et les cas ambigus, comblé un petit nombre de valeurs manquantes et mis toutes les mesures numériques sur une même échelle. Ils ont aussi traité un problème clé du monde réel : beaucoup plus de personnes de l’échantillon étaient saines que démentes. Pour empêcher les modèles de répondre systématiquement « pas de démence », les chercheurs ont utilisé des schémas de pondération qui font peser davantage, pendant l’entraînement, les erreurs sur le petit groupe de personnes démentes.
Comparer les outils classiques et les équipes de modèles
Avec ce jeu de données préparé, les auteurs ont comparé des outils d’apprentissage automatique familiers à des « ensembles » plus avancés, qui combinent plusieurs modèles pour obtenir un prédicteur plus puissant. Le groupe classique comprenait la régression logistique, les arbres de décision, les machines à vecteurs de support et les forêts aléatoires. Le groupe d’ensemble comportait AdaBoost, XGBoost et un modèle à vote majoritaire mélangeant trois classificateurs ajustés. Tous les modèles ont été entraînés sur une portion des données et testés sur des cas conservés à part, la performance étant évaluée par la précision, la capacité à détecter correctement les sujets déments (rappel) et la surface sous la courbe ROC, un résumé de la capacité du modèle à séparer les cas sains des cas malades. 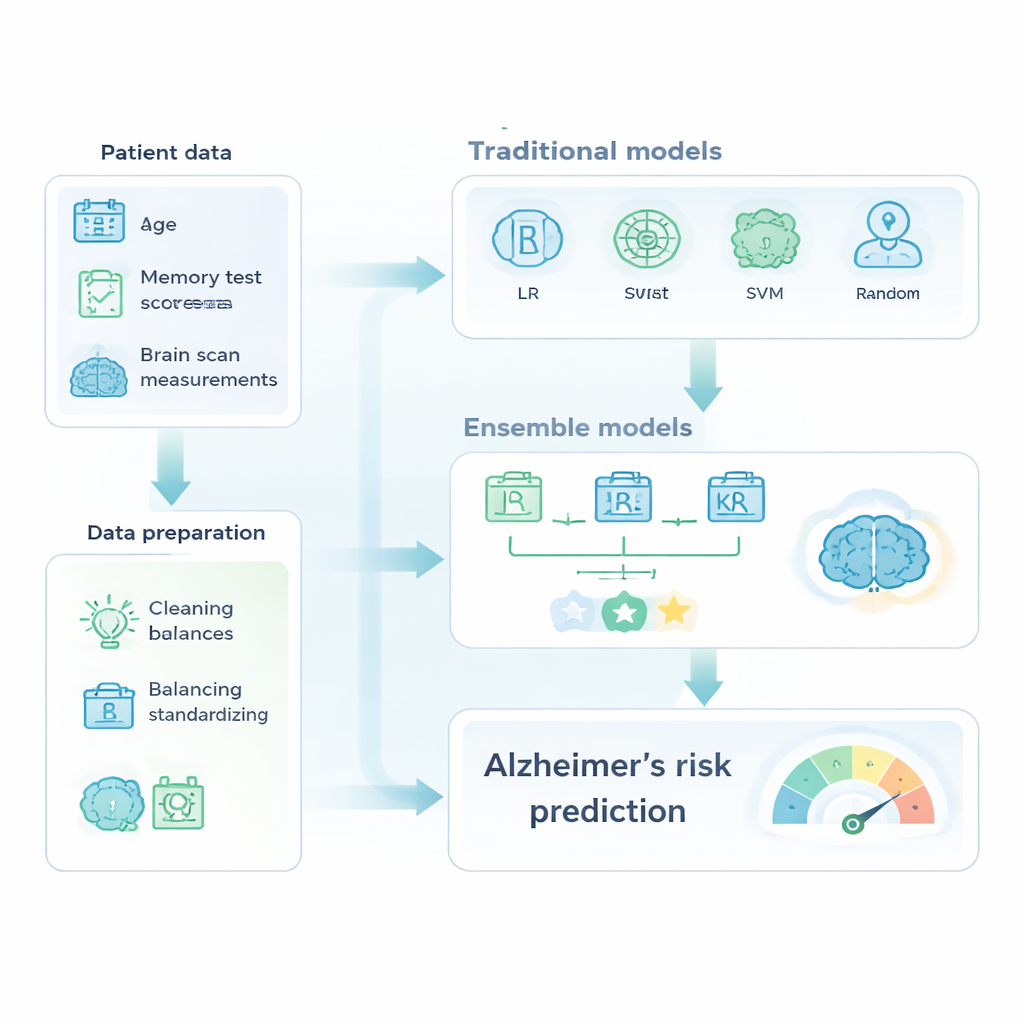
Quand plusieurs esprits valent mieux qu’un
Les résultats en confrontation directe étaient nets. Si les meilleures méthodes traditionnelles ont donné des performances raisonnables, elles se sont stabilisées autour des niveaux rapportés dans des études antérieures, avec des précisions de test dans la fourchette basse à moyenne des 80 %. En revanche, l’ensemble à vote majoritaire a atteint environ 95 % de précision et un score ROC tout aussi élevé, dépassant le repère souvent cité de 92 %. AdaBoost et d’autres modèles d’ensemble ont également surpassé tout modèle traditionnel individuel. Cet avantage découle du fait que différents algorithmes captent différents aspects des données ; en leur permettant de « voter », l’ensemble lisse les particularités et le surapprentissage de chaque modèle, conduisant à des prédictions plus stables. Le prix de ce gain est une transparence réduite : il est plus difficile de comprendre, d’un coup d’œil, pourquoi un ensemble a pris une décision donnée comparé à une régression simple ou à un arbre unique. 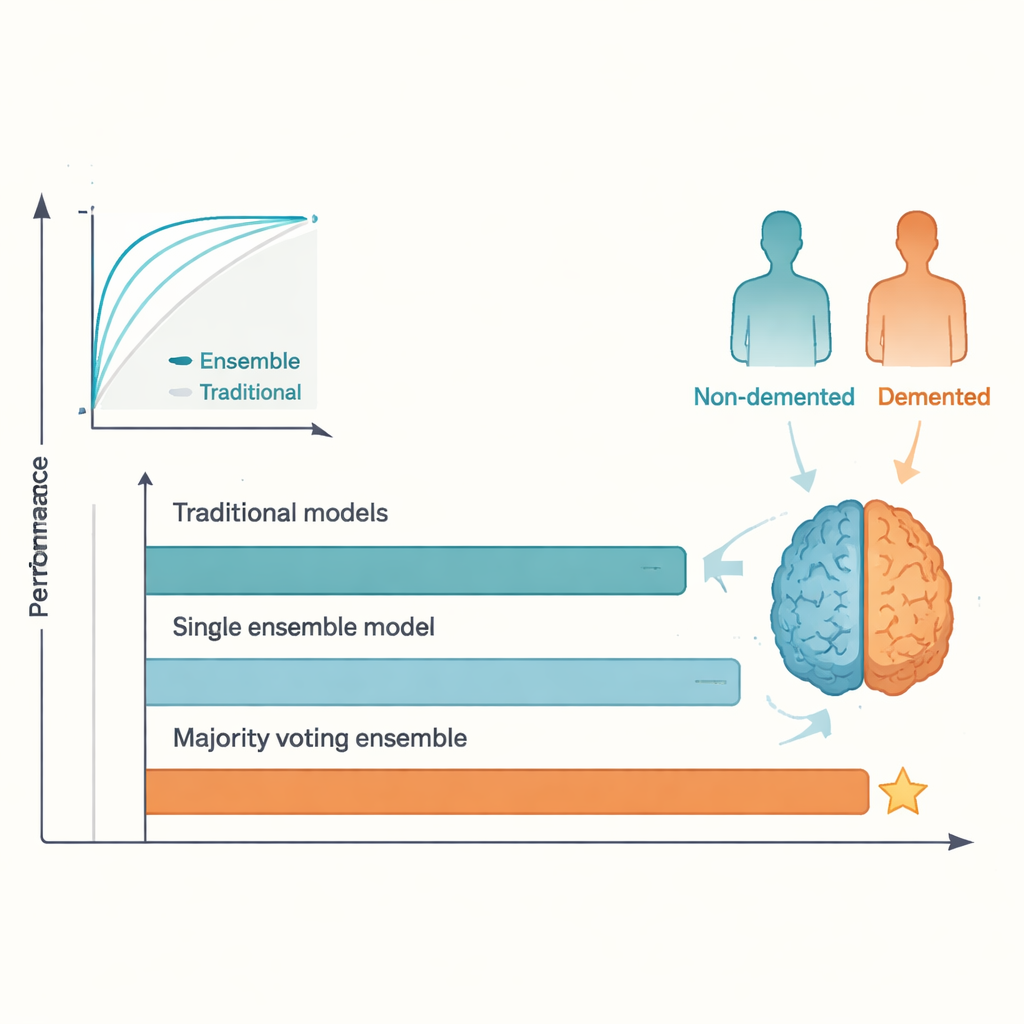
Rechercher des regroupements naturels dans les données
Au-delà de la question de savoir qui a une démence, les chercheurs se sont aussi demandé comment les patients se groupent naturellement, indépendamment des étiquettes diagnostiques. Pour cela, ils ont transformé toutes les variables continues en catégories ordonnées — par exemple des tranches d’âge ou de volume cérébral — et appliqué une technique appelée analyse des correspondances multiples pour compresser cette information riche en quelques dimensions sous-jacentes. Ils ont ensuite utilisé le clustering k-means pour partitionner ces points en un petit nombre de groupes cohérents. Certains clusters étaient dominés par des personnes présentant un volume cérébral préservé et des scores cognitifs normaux, tandis que d’autres comprenaient des individus au faible volume cérébral, aux mauvais résultats aux tests et à des évaluations de démence plus sévères. Le fait que ces clusters non supervisés coïncident bien avec le statut clinique suggère que les données portent un signal fort et cohérent concernant le risque et la progression de la maladie.
Ce que cela signifie pour les patients et les cliniciens
Pour un non-spécialiste, la conclusion est simple : lorsqu’elles sont bien conçues, des équipes de modèles d’apprentissage automatique peuvent détecter la démence liée à Alzheimer dans des données cliniques structurées plus précisément que les méthodes plus anciennes, et ce en utilisant des informations que de nombreuses cliniques collectent déjà. Parallèlement, des techniques exploratoires montrent que les personnes se répartissent en profils distincts de santé cérébrale et de fonction cognitive, suggérant différentes trajectoires possibles de la maladie. Bien que l’étude soit limitée par la taille d’échantillon modeste et par la complexité d’interprétation des modèles d’ensemble, elle montre que combiner une prédiction puissante avec une analyse exploratoire soignée peut à la fois améliorer la détection précoce et approfondir notre compréhension de l’installation de la maladie d’Alzheimer.
Citation: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Mots-clés: Maladie d’Alzheimer, prévision de démence, apprentissage automatique, modèles d’ensemble, imagerie cérébrale