Clear Sky Science · fr
Système d’attribution d’experts basé sur le traitement du langage naturel pour les actions Marie Skłodowska-Curie
Pourquoi choisir le bon expert est vraiment crucial
Lorsque des milliers de propositions de recherche se disputent des financements limités, tout dépend de qui les évalue. Si les experts assignés ne comprennent pas vraiment le sujet d’une proposition, des idées prometteuses peuvent être mal interprétées ou négligées. Cet article examine comment l’intelligence artificielle, et en particulier les systèmes modernes de traitement du langage, peut aider à associer les propositions aux meilleurs experts de manière plus précise et plus équitable que les outils actuels basés sur des mots-clés.
Le problème des listes de mots-clés
Jusqu’à présent, l’attribution des experts dans les principaux dispositifs de financement européens, comme les bourses postdoctorales Marie Skłodowska-Curie, s’est fortement appuyée sur des mots-clés. La plateforme actuelle analyse les descriptions des propositions et les profils des évaluateurs pour trouver des termes correspondants, puis suggère trois experts plus des alternatives. Mais les vice-présidents de panels — des scientifiques seniors qui supervisent le processus — finissent par modifier environ 40 % de ces attributions. Ce niveau de correction humaine rend le système exigeant en travail, lent et quelque peu opaque, d’autant plus que jusqu’à 10 000 propositions arrivent chaque année, souvent dans des domaines émergents où les listes de mots-clés fixes fonctionnent mal.
Lire la recherche comme un humain, à grande échelle
Les auteurs ont développé un nouveau système d’attribution qui cherche à « lire » la recherche plus comme le ferait un expert humain. Plutôt que de s’appuyer sur des étiquettes, il collecte les publications de chaque expert via ORCID, un identifiant mondial pour les chercheurs, et construit une base de données de plus de 2 800 résumés d’articles. Les résumés des propositions et des publications sont ensuite traités par GALACTICA, un grand modèle de langage entraîné spécifiquement sur des textes scientifiques. GALACTICA transforme chaque résumé en une empreinte numérique qui capture son sens, pas seulement sa formulation. En comparant ces empreintes, le système peut estimer à quel point le contenu d’une proposition correspond au travail antérieur de chaque expert.
Trois façons d’agréger l’expertise
Un défi est que les experts peuvent avoir des dizaines de publications. Le système a besoin d’un score unique par expert et par proposition ; les auteurs ont donc testé trois méthodes simples pour combiner les similarités. La stratégie Somme additionne tous les scores de similarité, récompensant une pertinence large et répétée. La stratégie Produit les multiplie, mettant l’accent sur une similarité cohérente à travers de nombreuses publications mais pénalisant fortement toute correspondance faible. La stratégie Maximum ne conserve que la correspondance la plus forte, partant du principe qu’un seul article très lié peut suffire à justifier une attribution. Ces scores sont ensuite utilisés pour classer 48 experts candidats pour chacun des 181 projets, et les classements sont comparés aux choix finaux d’experts effectués par les vice-présidents de panels.
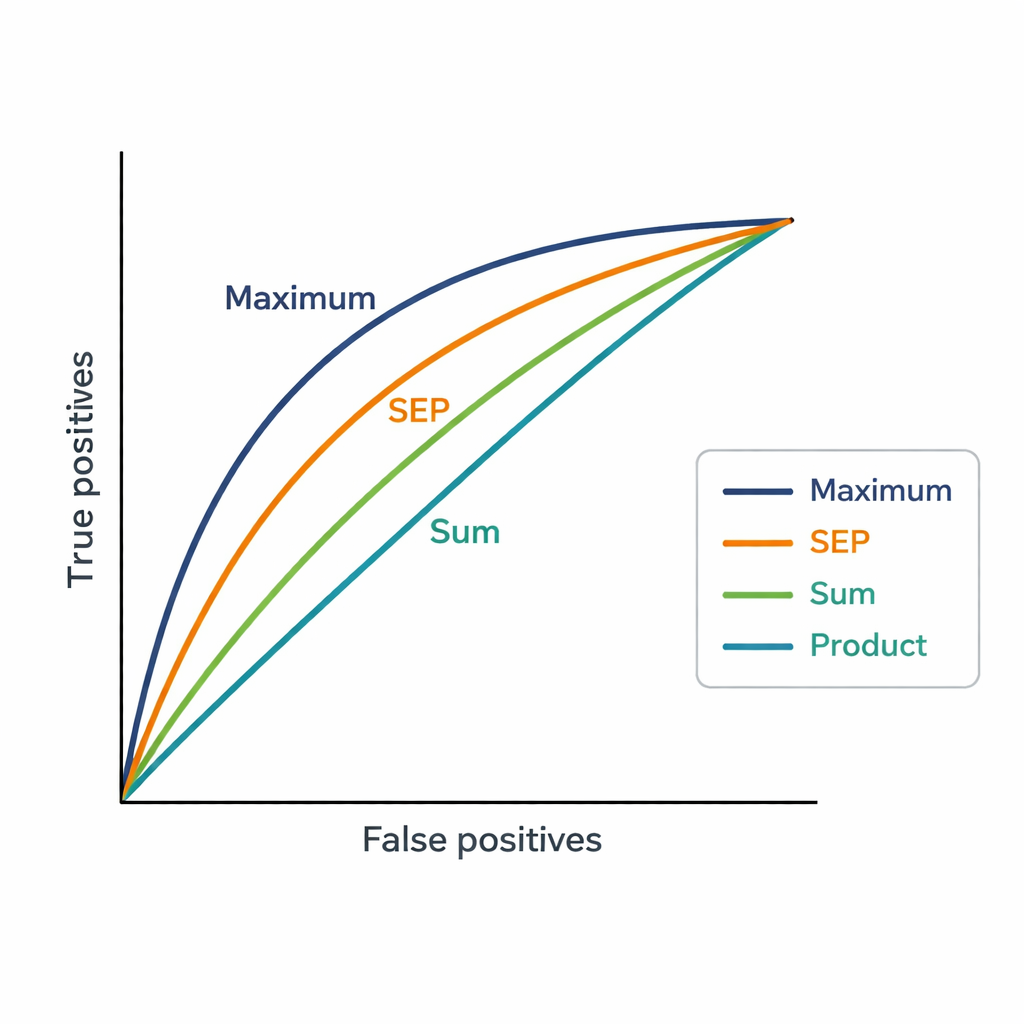
Ce que les chiffres révèlent sur les choix humains
La stratégie Maximum a le mieux correspondu aux décisions des vice-présidents, atteignant une AUC de 0,82, supérieure à la fois au système actuel basé sur les mots-clés (AUC 0,75) et aux autres méthodes d’agrégation. En pratique, l’expert choisi par les vice-présidents apparaissait généralement parmi les quatre premières suggestions produites par Maximum. Cela suggère que, lors de l’attribution des évaluateurs, les humains ont tendance à se concentrer sur l’existence d’au moins une connexion très forte entre les travaux antérieurs d’un expert et une proposition, plutôt que d’exiger que toutes les publications de l’expert soient alignées. La nouvelle méthode génère également des scores beaucoup plus fins que les niveaux d’« affinité » grossiers de la plateforme, permettant de mieux distinguer des experts classés de façon proche.
Ce que cela signifie pour les futures évaluations de subventions
Pour un lecteur non spécialiste, la conclusion est simple : en utilisant une IA qui comprend le langage scientifique, les agences de financement peuvent mieux associer les propositions aux bons experts, réduire les corrections manuelles et rendre le processus plus cohérent et transparent. Si différentes façons de combiner les preuves issues des publications mettent en lumière divers aspects de l’expertise, la règle simple du « meilleur seul correspondant » semble refléter la manière dont les humains décident réellement. À mesure que ces systèmes seront testés plus largement et avec des modèles de langage plus récents, ils pourraient devenir un élément clé d’une évaluation de la recherche plus juste et plus efficace à l’échelle mondiale.
Citation: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Mots-clés: évaluation par les pairs, appariement d’experts, financement de la recherche, traitement du langage naturel, grands modèles de langage