Clear Sky Science · fr
Résumé temporel innovant pour la classification vidéo complexe
Pourquoi des résumés vidéo plus intelligents comptent
Des caméras de surveillance aux plateformes de streaming, le monde enregistre plus de vidéos que ce que les humains ou les ordinateurs peuvent gérer confortablement. Chaque seconde de séquence contient des dizaines d'images, pourtant bon nombre d'entre elles sont presque identiques. Cet article explore une manière de réduire de longues vidéos aux instants les plus révélateurs, afin que les ordinateurs puissent toujours reconnaître des actions comme cuisiner, pratiquer un sport ou promener un chien—tout en utilisant bien moins de temps, de mémoire et d'énergie. De telles avancées pourraient permettre d'apporter une analyse vidéo puissante à des appareils du quotidien, des robots domestiques aux caméras portables.

Des images sans fin aux moments clés
Les systèmes traditionnels de classification vidéo tentent de reconnaître ce qui se passe dans un clip—par exemple couper des légumes ou tirer au basket—en alimentant de longues séquences d'images dans de lourds modèles d'apprentissage profond. Ces modèles doivent gérer à la fois l'apparence (à quoi les choses ressemblent) et la temporalité (comment elles bougent dans le temps). Traiter toutes les images entraîne des jeux de données volumineux, des besoins de stockage élevés et des calculs lents et gourmands en énergie. Les auteurs soutiennent que beaucoup de ces images sont redondantes : si rien de majeur ne change d'une image à la suivante, le système n'apprend guère en analysant les deux. L'idée centrale de l'article est d'extraire un ensemble beaucoup plus restreint « d'images clés » qui capture néanmoins les changements importants de la scène.
Mesurer le changement entre images
Pour trouver ces moments clés, les chercheurs conçoivent et comparent plusieurs façons de mesurer à quel point une image diffère d'une autre. Plutôt que de se fier uniquement à la distance euclidienne classique, qui compare tous les pixels de manière uniforme, ils testent des alternatives plus sensibles aux changements structurels. Leur proposition principale, appelée distance « Norme des lignes » (Norm of Rows), se concentre sur la plus grande différence le long de chaque ligne de pixels puis retient la ligne la plus prononcée comme mesure du changement entre deux images. Ils explorent aussi des distances basées sur les colonnes et des méthodes reposant sur les valeurs propres de matrices qui résument la dispersion des différences de pixels. Toutes ces approches visent à mieux détecter les mouvements ou changements de scène significatifs, comme une main qui saisit un ustensile ou un joueur qui saute.
Comment fonctionne le pipeline de résumé
Le processus de résumé commence par la toute première image d'une vidéo, traitée comme image clé initiale. Le système compare ensuite cette image clé à chaque image suivante en utilisant l'une des mesures de distance. Chaque fois que la distance dépasse un seuil choisi, l'image correspondante est marquée comme nouvelle image clé, indiquant qu'un changement visuel important s'est produit. La procédure se répète alors en prenant cette nouvelle image clé comme référence, parcourant la vidéo et recueillant une chaîne d'instantanés représentatifs. En ajustant le seuil, la méthode peut conserver aussi peu que 20 % ou jusqu'à 80 % des images d'origine, en jouant sur le compromis entre compacité et détail. Ces séquences résumées sont ensuite transmises à un classificateur d'apprentissage profond standard qui combine un puissant réseau d'images (ResNet-50) avec un module LSTM sensible au temps.
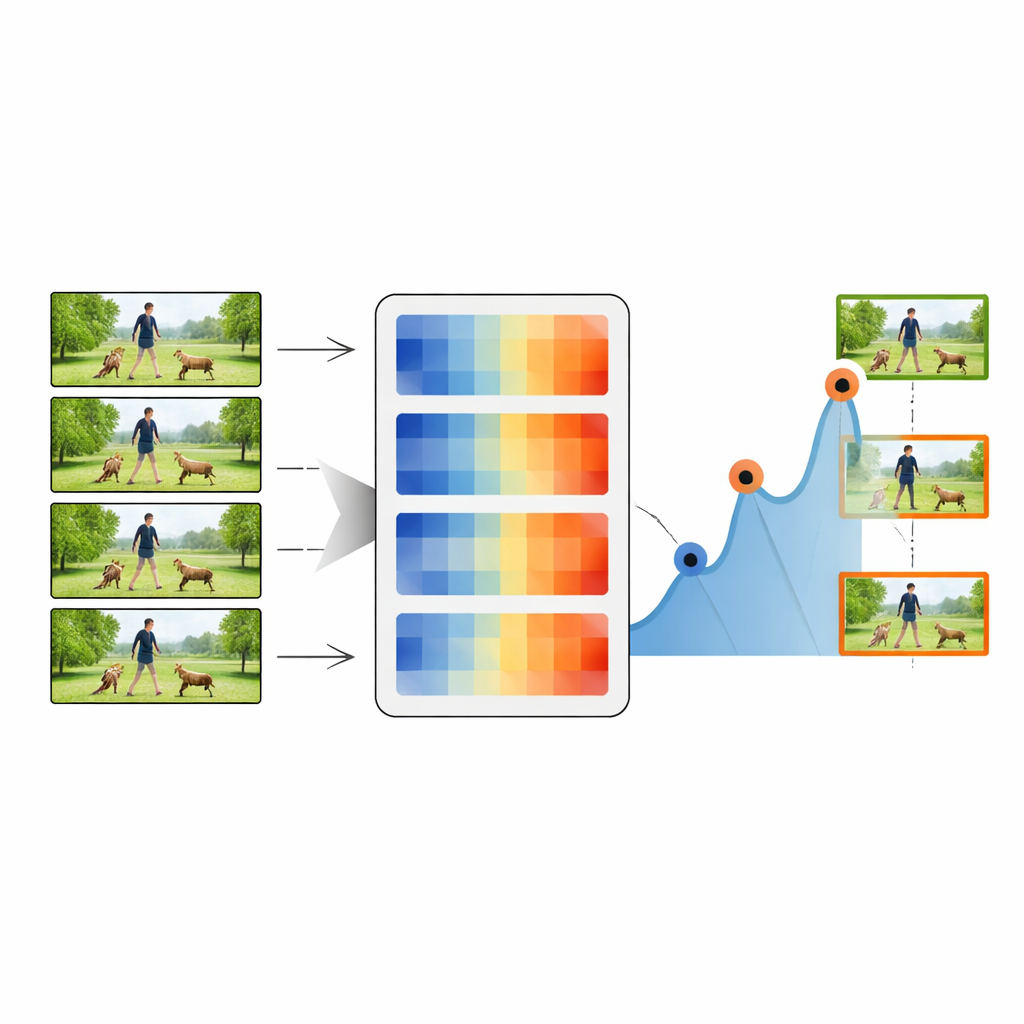
Évaluer la méthode
Les auteurs évaluent rigoureusement leur approche sur quatre collections vidéo bien connues : activités quotidiennes en cuisine (MMAC), sports et actions générales (UCF101 et UCF11), et des clips plus variés et difficiles (HMDB51). Sur ces benchmarks, la distance Norme des lignes offre systématiquement le meilleur compromis entre rapidité et précision. Avec seulement environ la moitié des images conservées, leur système atteint des précisions de classification supérieures à 90 % sur plusieurs jeux de données—souvent en égalant ou en surpassant des méthodes plus complexes qui utilisent les vidéos complètes non résumées. Ils mesurent également la couverture du contenu original par les résumés, la redondance des images sélectionnées et la diversité des moments capturés. La métrique proposée obtient une forte couverture avec une faible redondance, ce qui signifie qu'elle préserve le récit de la vidéo sans répéter des images similaires.
Des décisions plus rapides pour la vidéo dans le monde réel
En réduisant le nombre d'images d'environ moitié, la méthode divise presque par deux le temps de traitement sur du matériel informatique standard et procure toujours des accélérations notables même sur des cartes graphiques modernes. Pour des systèmes réels qui doivent réagir en temps réel—comme la surveillance, les robots autonomes ou les applications mobiles—cette réduction de la charge de travail est cruciale. L'étude montre qu'une mesure de distance soigneusement conçue peut agir comme un filtre intelligent, choisissant quelles images méritent attention et lesquelles peuvent être ignorées sans risque.
Conclusion pour l'usage courant
En termes simples, ce travail montre que les ordinateurs n'ont pas besoin de visionner chaque image pour comprendre ce qui se passe dans une vidéo. En se concentrant sur les moments où l'image change vraiment et en ignorant les presque-duplicates, la technique proposée conserve l'essence d'une action tout en réduisant considérablement la quantité de données. Cela rend la compréhension vidéo de haute qualité plus praticable sur du matériel limité et ouvre la voie à des outils plus rapides et plus efficaces pour analyser le flot croissant d'informations visuelles dans notre quotidien.
Citation: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Mots-clés: classification vidéo, résumés vidéo, sélection d'images clés, reconnaissance d'actions, efficacité en vision par ordinateur