Clear Sky Science · fr
Construction et application d’un graphe de connaissances pour les documents de normes de qualité des semences
Pourquoi les règles sur les semences comptent pour l’alimentation de tous
Derrière chaque sac de riz ou paquet de graines potagères se cache un dédale de normes techniques qui protègent discrètement les rendements et la sécurité alimentaire. Pourtant, ces règles de qualité des semences sont souvent enfouies dans des documents PDF denses, difficiles à rechercher ou à interpréter pour les agriculteurs, les autorités et les entreprises. Cette étude montre comment transformer ces documents statiques en une « carte » vivante de faits connectés — un graphe de connaissances — peut rendre les normes agricoles plus transparentes, interrogeables et adaptées à l’ère de l’agriculture numérique. 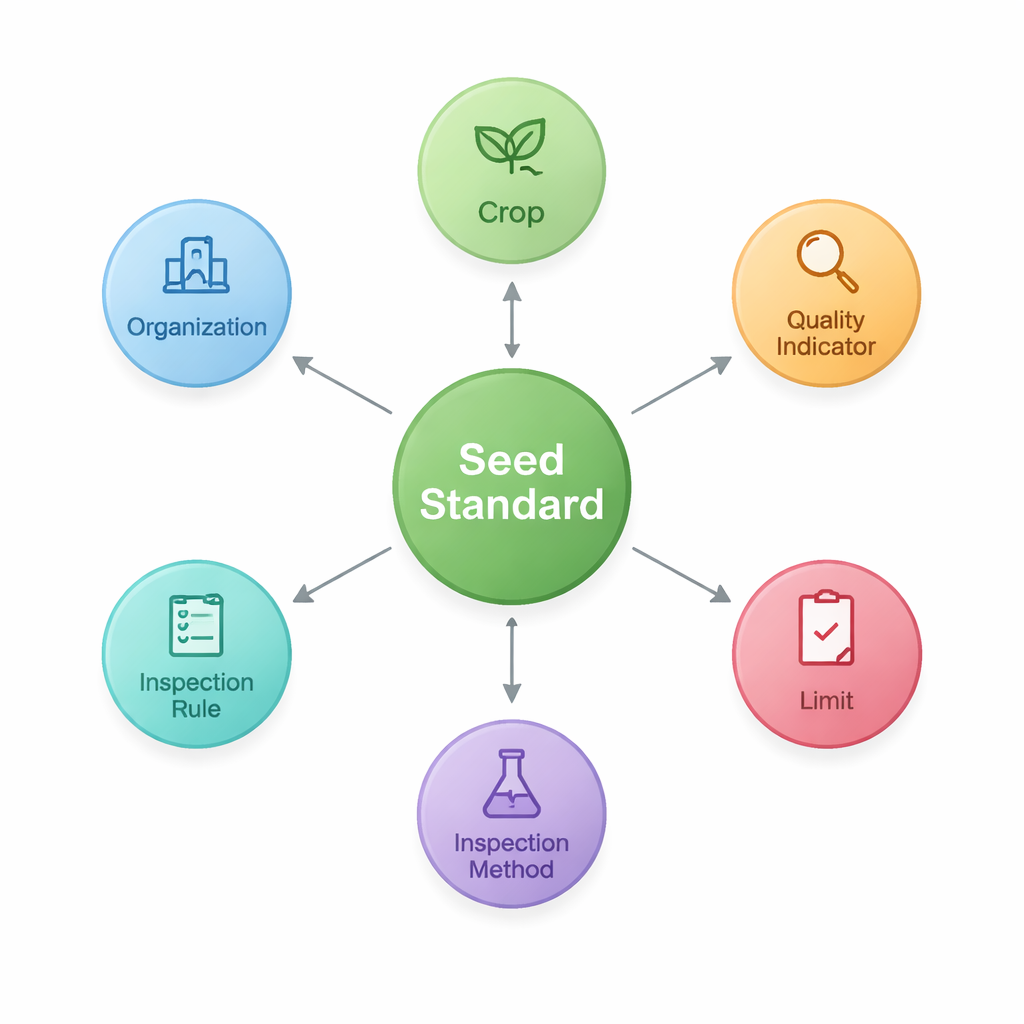
Des normes papier à l’information intelligente
Les normes de qualité des semences définissent ce qui est acceptable : la pureté requise d’un lot, le taux de germination attendu, l’humidité maximale autorisée et les méthodes utilisées pour tester ces caractéristiques. En Chine, le nombre de ces documents a explosé, et beaucoup existent encore uniquement sous forme de pages scannées ou de texte non structuré. La recherche par mot‑clé peine à répondre à des questions pratiques comme « Quelles sont les limites de pureté pour cette culture ? » ou « Quelle règle a remplacé une version antérieure ? ». Les auteurs soutiennent que, pour suivre le rythme des changements rapides en agriculture, ces normes doivent passer de pages lisibles par des humains à des connaissances compréhensibles par les machines, aptes à supporter des requêtes, des comparaisons et des contrôles automatisés rapides.
Construire une carte des connaissances sur les semences
Pour y parvenir, les chercheurs conçoivent d’abord une « ontologie » — un schéma commun qui définit les principaux éléments des normes de semences et leurs liens. Ils identifient sept types d’entités essentiels, comprenant la norme elle‑même, la culture concernée, les indicateurs de qualité tels que la pureté ou le taux de germination, les limites numériques pour ces indicateurs, les méthodes et règles d’inspection, et les organisations qui rédigent ou publient les documents. Cette structure capture des motifs comme « Culture–Indicateur de qualité–Limite », particulièrement importants en agriculture. À partir de ce schéma, ils stockent ensuite les faits extraits sous forme de nœuds et de liens dans une base de graphes (Neo4j), créant un réseau de 2 436 entités reliées par 3 011 relations.
Combiner règles et apprentissage automatique
Le vrai défi est d’extraire des faits propres et fiables à partir de documents sources désordonnés. Les normes de semences mêlent tableaux bien formatés, métadonnées frontales rigides et longues clauses narratives. Aucune technique ne couvre parfaitement tous ces cas. L’équipe construit donc un système d’extraction hybride. Elle utilise des motifs précis (expressions régulières) pour lire les tableaux structurés et les informations documentaires de base, qui suivent généralement des formats stricts. Pour les textes narratifs plus complexes — comme les règles détaillées d’inspection — ils entraînent un pipeline de modèles de langage moderne appelé BERT–BiLSTM–CRF pour reconnaître les noms clés, codes et termes techniques. Ce modèle apprend à partir d’exemples soigneusement étiquetés et peut repérer des entités même lorsqu’elles apparaissent dans des formulations variées et de longues phrases. 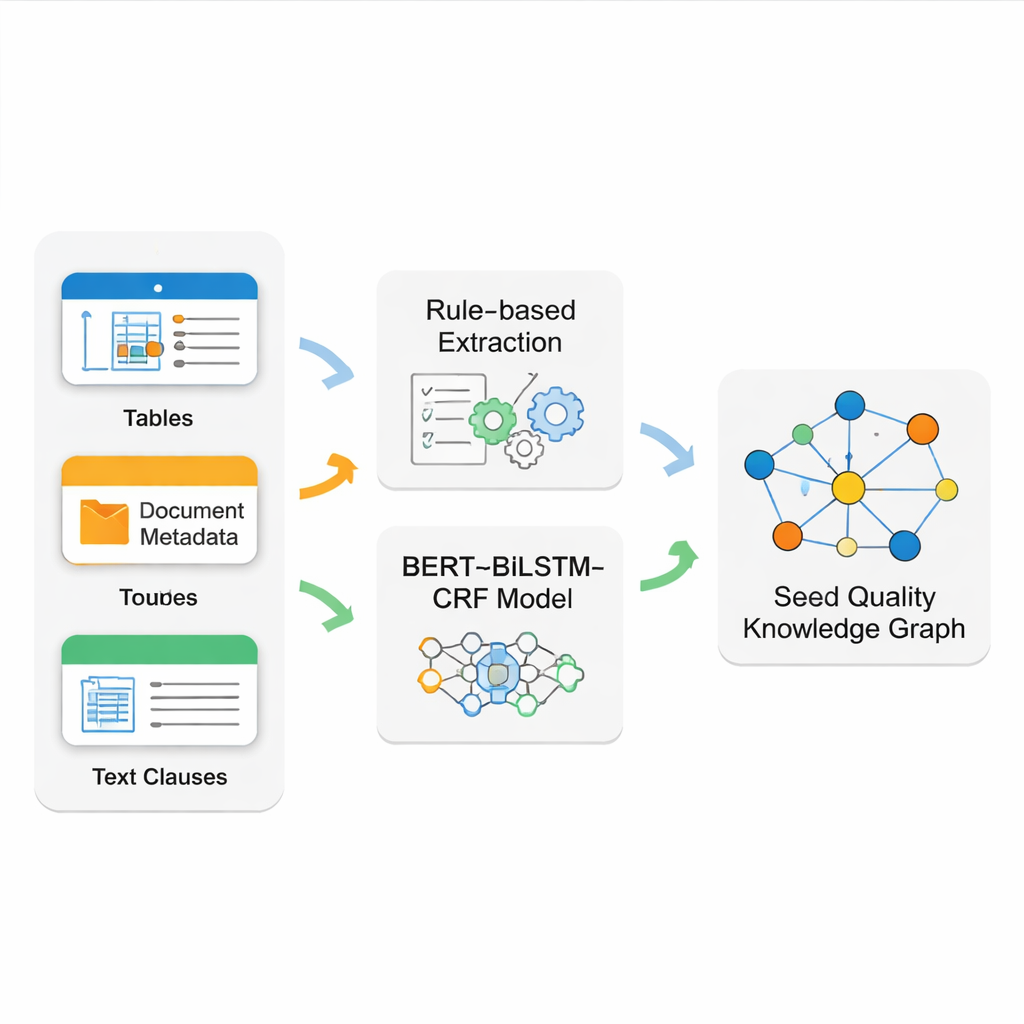
Performance du système en pratique
Testée en conditions réelles, l’approche hybride donne de bons résultats. Le modèle de langage atteint un score F1 global (équilibre entre précision et rappel) d’environ 91,6 %, surpassant deux modèles de référence couramment utilisés. Il est particulièrement performant pour repérer des éléments structurés comme les codes de norme et reste robuste sur des tâches plus difficiles telles que l’extraction de longues règles d’inspection. Une fois ces informations chargées dans le graphe de connaissances, les utilisateurs peuvent explorer visuellement comment une norme donnée se rapporte à des versions antérieures, quelles organisations l’ont rédigée, quelles cultures et indicateurs elle couvre, et quelles méthodes d’essai elle prescrit. Plutôt que de feuilleter de longs PDF, les régulateurs et les entreprises semencières peuvent lancer des recherches ciblées et voir des résultats reliés en quelques secondes.
Ce que cela signifie pour les agriculteurs et les systèmes alimentaires
Pour les non‑spécialistes, le résultat est une façon plus intelligente de gérer les règles qui assurent la fiabilité des semences et la productivité des cultures. L’étude montre qu’en combinant une conception conceptuelle claire avec des extractions basées à la fois sur des règles et sur l’apprentissage, il est possible de transformer des normes de semences éparses en une base de connaissances cohérente et interrogeable. Cela jette les bases techniques de normes « SMART » que les ordinateurs peuvent lire, recouper et mettre à jour au fil des évolutions réglementaires. À long terme, de tels outils pourraient aider les agriculteurs et les entreprises agricoles à vérifier rapidement si des semences répondent aux exigences de qualité en vigueur, soutenir les autorités dans le suivi des révisions et des lacunes, et contribuer à des récoltes et une sécurité alimentaire plus stables.
Citation: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Mots-clés: normes de qualité des semences, graphe de connaissances, numérisation agricole, reconnaissance d’entités nommées, normes intelligentes