Clear Sky Science · fr
Modèle de langage massif ancré sur des connaissances pour la génération de plans d'entraînement sportifs personnalisés
Des programmes d'entraînement plus intelligents pour tout le monde
La plupart des applications de fitness promettent un entraînement personnalisé, mais beaucoup s'appuient encore sur des modèles génériques qui ne tiennent pas compte de l'état réel de votre corps. Cet article présente LLM-SPTRec, un nouveau système qui utilise le même type de grands modèles de langage derrière les chatbots modernes, combiné à des connaissances validées en science du sport et aux données de wearables, pour élaborer des plans d'entraînement plus sûrs et plus efficaces. Pour quiconque s'est demandé pourquoi son application suggère toujours les mauvais exercices — ou s'est inquiété de la sécurité des conseils de santé générés par l'IA — ce travail montre comment rendre le coaching numérique à la fois plus personnel et plus scientifique.
Pourquoi les applications de fitness traditionnelles montrent leurs limites
Les moteurs de recommandation classiques, comme ceux qui proposent des films ou des produits, peinent lorsqu'on les applique à l'exercice physique. Ils reproduisent souvent des modèles standard, ont du mal avec les données limitées des nouveaux utilisateurs et regardent rarement comment votre corps évolue au jour le jour. Pire, ils ne sont pas conçus pour des décisions à forts enjeux où la sécurité compte. Les modèles de langage généraux savent parler d'entraînement, mais parce qu'ils sont entraînés sur des textes larges d'internet, ils peuvent « halluciner » des conseils risqués ou omettre des jours de repos importants. Les auteurs soutiennent que pour la planification d'exercice — où de mauvais conseils peuvent causer des blessures ou un surentraînement — l'IA doit être ancrée dans une science du sport vérifiée et suivre l'évolution de l'état d'une personne dans le temps.
Construire un portrait riche de l'individu
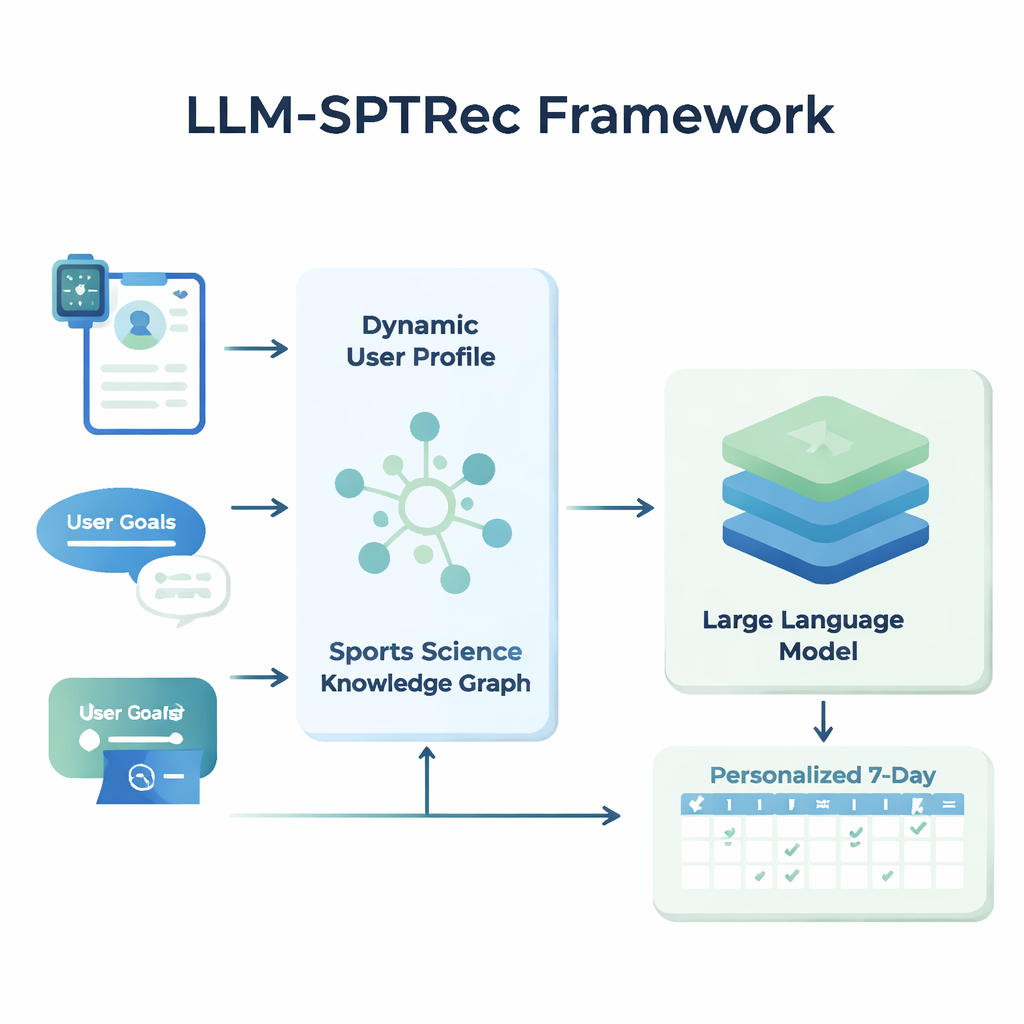
Au cœur de LLM-SPTRec se trouve un module qui crée une capture d'état détaillée de chaque utilisateur. Plutôt que de ne stocker que l'âge, le sexe ou le niveau d'expérience, le système fusionne trois types d'informations : des traits statiques (comme l'historique d'entraînement), des signaux dynamiques (tels que la fréquence cardiaque, la variabilité de la fréquence cardiaque, le score de sommeil et les entraînements précédents issus des wearables et des journaux) et des objectifs en texte libre rédigés par l'utilisateur. Un modèle basé sur des transformers — apparenté à la technologie des modèles de langage modernes — apprend des motifs dans ces séries temporelles, par exemple comment un entraînement intense la veille peut affecter la disponibilité du jour. Un mécanisme d'attention pèse ensuite quels signaux importent le plus à un instant donné, en les combinant en une représentation numérique unique de l'état actuel de l'utilisateur.
Apprendre à l'IA la vraie science du sport
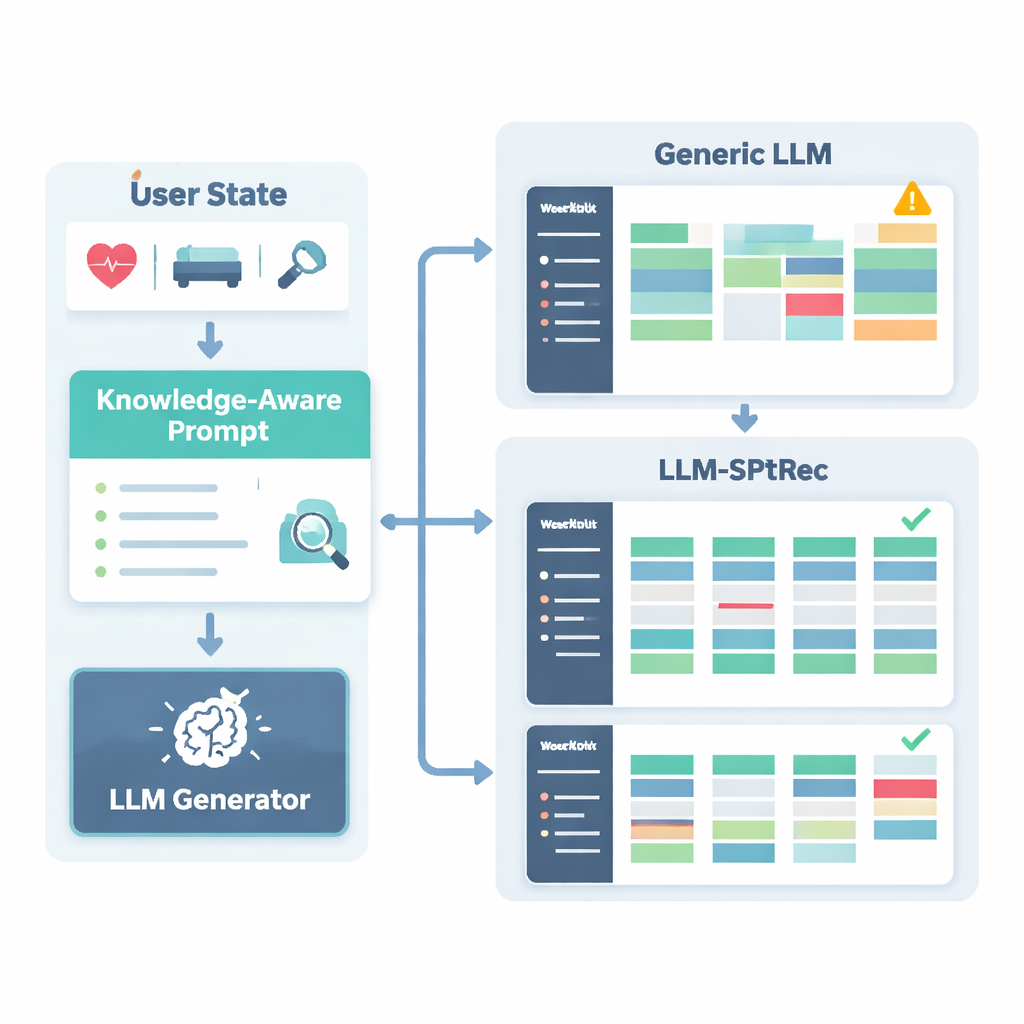
Pour éviter des recommandations dangereuses ou non scientifiques, les chercheurs ont construit un Graphe de Connaissances en Science du Sport, essentiellement une carte structurée de faits validés par des experts. Il comprend des milliers d'entrées qui relient exercices, muscles, types de mouvements, équipements, blessures courantes et principes d'entraînement comme la surcharge progressive et la spécificité. Pour chaque utilisateur, le système extrait les parties les plus pertinentes de ce graphe — par exemple quels muscles sollicite le développé couché et quels mouvements sont déconseillés en cas de problèmes d'épaule — et les transforme en texte lisible qui est fourni au modèle de langage en complément du profil utilisateur. Le modèle est ensuite invité, via une formulation de prompt soigneusement conçue, à générer un plan d'entraînement sur plusieurs jours au format structuré, en respectant des règles comme la rotation des groupes musculaires entre les jours et l'évitement des contre-indications connues.
Maintenir les plans structurés, sûrs et en amélioration continue
LLM-SPTRec ne se contente pas de générer du texte. Un module de validation vérifie chaque plan selon des règles strictes, comme ne pas surcharger les mêmes groupes musculaires primaires sur des jours consécutifs, et signale les conflits avec les risques de blessure stockés dans le graphe de connaissances. Si un plan échoue à ces contrôles, le système relance le modèle en lui indiquant explicitement ce qui ne va pas, jusqu'à obtenir un plan sûr. L'entraînement du système se fait aussi en deux étapes. D'abord, il apprend à partir d'une large collection de plans conçus par des experts. Ensuite, il est affiné par des retours, où des évaluations simulées ou réelles des utilisateurs récompensent les plans qui sont cohérents, alignés sur les objectifs et agréables à suivre, tout en pénalisant fortement les suggestions dangereuses. Cette boucle de rétroaction oriente le modèle vers des recommandations qui fonctionnent mieux en pratique.
Performances du système en conditions réelles
Les auteurs ont testé LLM-SPTRec sur un grand jeu de données réel appelé SportFit-1M, qui combine des données anonymisées d'applications de fitness et de dispositifs portables, couvrant des dizaines de milliers d'utilisateurs et des millions de journaux d'entraînement et d'enregistrements physiologiques. Ils ont comparé leur système à des bases solides : filtrage collaboratif classique, un modèle de séquence qui ne regarde que les choix passés, un recommandateur basé sur un graphe de connaissances à la pointe, et un cadre reposant sur un modèle de langage généraliste. LLM-SPTRec a surpassé tous ces systèmes, non seulement pour le choix des exercices appropriés, mais — plus important encore — pour la production de plans complets que des experts ont jugés plus cohérents et mieux alignés sur les objectifs des utilisateurs. Les scores de satisfaction utilisateur prédits étaient également plus élevés, et une petite étude humaine menée avec des coachs certifiés a jugé sa sécurité bien meilleure que celle d'un modèle de langage général sans ancrage spécifique au sport.
Ce que cela signifie pour le coaching numérique à venir
Pour un non-spécialiste, la conclusion est que le coaching IA plus intelligent et plus sûr est possible quand trois ingrédients se combinent : des données riches issues de vos appareils, une science du sport d'experts encodée en connaissances structurées, et des modèles de langage puissants dont la créativité est soigneusement guidée et contrôlée. LLM-SPTRec montre qu'une telle combinaison peut générer des plans d'entraînement adaptatifs, jour après jour, qui respectent l'état changeant de votre corps et vos objectifs personnels, tout en réduisant le risque de conseils nuisibles ou absurdes. À l'avenir, la même recette pourrait s'étendre au-delà des entraînements vers la nutrition, la rééducation des blessures ou même le bien-être mental, ouvrant la voie à des assistants IA qui ressemblent moins à des chatbots génériques et plus à des coachs numériques compétents et soucieux de la sécurité.
Citation: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Mots-clés: entraînement personnalisé, IA en science du sport, recommandation fitness, données de wearables, graphe de connaissances