Clear Sky Science · fr
Un cadre léger YOLO11n seg pour la détection de fissures de surface en temps réel avec segmentation
Pourquoi les microfissures comptent
Des fissures cachées dans les routes, les ponts et les bâtiments peuvent sembler bénignes, mais elles sont souvent les premiers signes qu’une structure s’use. Repérer ces lignes tôt peut éviter des réparations coûteuses voire des défaillances catastrophiques. Pourtant, la plupart des inspections sont encore effectuées par des personnes marchant ou circulant lentement le long des surfaces, prenant des notes à la main. Cette étude explore comment un système d’intelligence artificielle compact peut détecter et délimiter les fissures en temps réel, assez rapidement pour fonctionner sur des drones, de petits robots et des capteurs à faible consommation plutôt que seulement dans des centres de données puissants.
Des contrôles manuels à la vision machine
Les ingénieurs ont longtemps tenté d’automatiser la détection des fissures en utilisant des astuces classiques de traitement d’image comme la détection de contours et le seuillage. Ces méthodes fonctionnent dans des conditions de laboratoire propres mais s’effondrent rapidement dans le monde réel, où ombres, taches et textures rugueuses trompent les algorithmes simples. Plus récemment, l’apprentissage profond a changé la donne : les réseaux neuronaux peuvent apprendre à quoi ressemblent les fissures directement à partir des images. Les premières versions pouvaient indiquer si une petite région d’image contenait une fissure, mais elles peinaient à localiser précisément la fissure et étaient souvent trop lentes pour des inspections en direct.
Comment un modèle léger apprend à voir les fissures
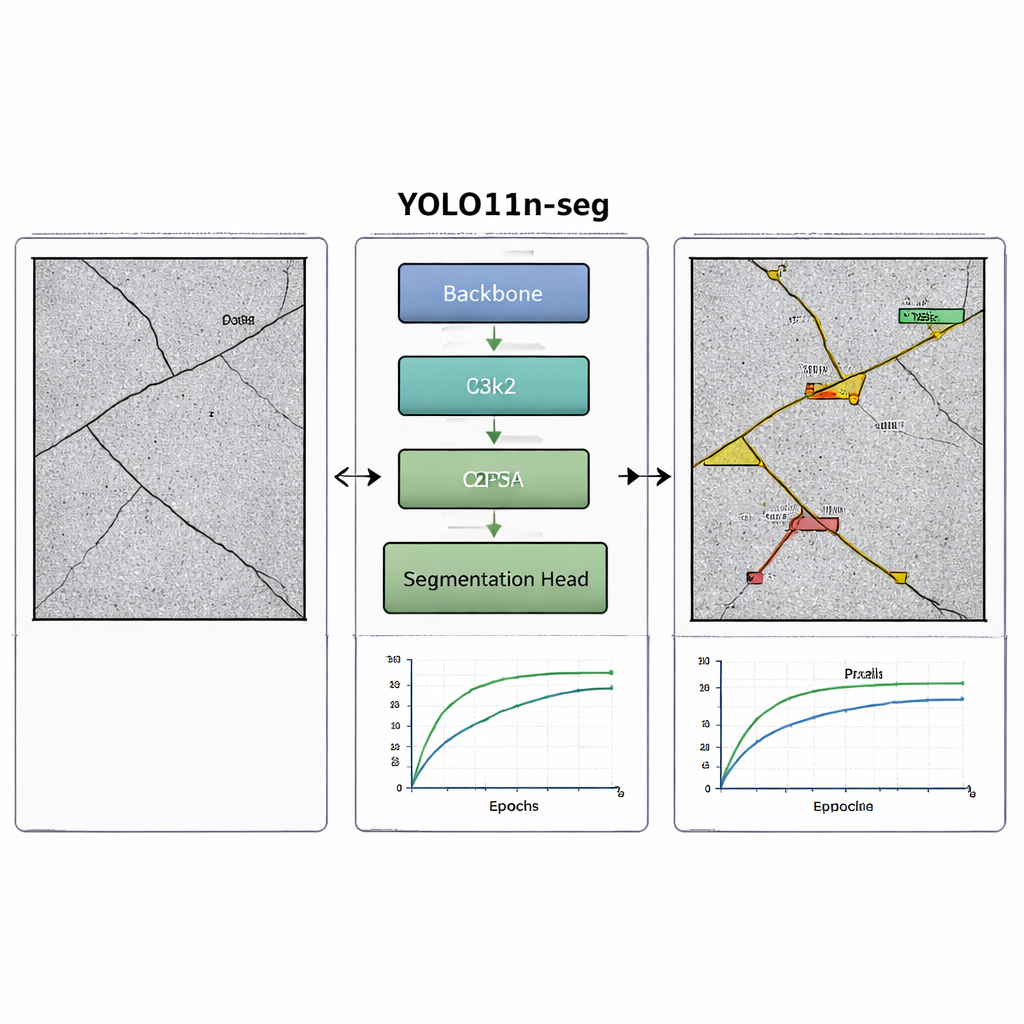
Les auteurs s’appuient sur la famille de modèles YOLO, un ensemble d’outils populaires en vision par ordinateur connu pour repérer les objets en une seule passe rapide dans le réseau. Ils se concentrent sur une très petite version appelée YOLO11n-seg, conçue pour tracer la forme exacte des fissures, et pas seulement encadrer grossièrement leur emplacement. Le modèle est entraîné sur le jeu de données Crack-Seg, qui contient plus de 11 000 images de route minutieusement annotées où chaque pixel de fissure est marqué. Les images sont redimensionnées à un format standard et fournies au réseau, qui apprend progressivement à distinguer les motifs fins et sinueux des dégâts réels des détails de fond inoffensifs comme la texture ou la saleté.
Astuces intelligentes pour les détails minuscules
Pour repérer des fissures capillaires sur du béton rugueux, le modèle utilise deux astuces de conception. D’abord, un bloc particulier appelé C3k2 bascule automatiquement entre des fenêtres d’observation petites et légèrement plus grandes, ce qui lui permet de suivre à la fois des fissures très fines et des fissures plus longues. Ensuite, un module d’attention spatiale nommé C2PSA apprend au modèle à se concentrer sur les régions probables de fissures tout en ignorant les distractions telles que les taches d’huile, les ombres ou les surfaces à motifs. Ensemble, ces ajouts aident le système à délimiter les fissures de manière plus propre et réduisent le risque de confondre des imperfections de fond avec des dommages structurels, tout en maintenant le modèle suffisamment compact pour fonctionner sur du matériel modeste.
Des résultats rapides sans matériel lourd
Dans les tests, le réseau léger contient seulement environ 2,8 millions de paramètres—mince en comparaison de nombreux systèmes d’apprentissage profond modernes—pourtant il atteint des performances proches de celles de modèles plus grands et plus lents. Sur le benchmark Crack-Seg, il identifie correctement les régions de fissure avec une précision d’environ 79 % et obtient de bons scores sur la correspondance des formes de fissure prédites avec la vérité terrain. Surtout, il traite chaque image en environ 3,6 millisecondes sur un GPU standard, soit des centaines d’images par seconde. Comparé à des modèles largement utilisés comme U-Net, Mask R-CNN et une variante YOLO antérieure, il offre une précision de segmentation compétitive voire supérieure tout en étant beaucoup plus rapide, ce qui le rend pratique pour des flux vidéo continus depuis des drones ou des véhicules d’inspection.
Vers des contrôles structurels automatiques
Pour les non‑spécialistes, l’essentiel est que ce travail montre qu’il est désormais possible de construire des outils d’IA petits et efficaces qui non seulement détectent les fissures mais tracent aussi leur forme et taille exactes assez rapidement pour la surveillance en temps réel. Bien que des fissures extrêmement fines dans des conditions de faible éclairage ou de mauvais temps restent difficiles, le système YOLO11n-seg proposé offre un compromis prometteur entre rapidité et fiabilité. Avec des améliorations supplémentaires et une intégration dans l’équipement de terrain, de tels modèles pourraient aider les villes et les agences à détecter les dommages plus tôt, prioriser les réparations et maintenir les infrastructures vitales en sécurité avec moins d’efforts manuels.
Citation: Tiwari, S., Gola, K.K., Kanauzia, R. et al. A lightweight YOLO11n seg framework for real time surface crack detection with segmentation. Sci Rep 16, 6566 (2026). https://doi.org/10.1038/s41598-026-37073-1
Mots-clés: fissures d’infrastructure, vision par ordinateur, apprentissage profond, inspection en temps réel, segmentation YOLO