Clear Sky Science · fr
L’évolution de la détection d’objets : des CNN aux transformers et à la fusion multimodale
Apprendre aux ordinateurs à voir les objets du quotidien
Chaque fois que votre téléphone identifie des amis sur une photo, qu’une voiture repère un piéton ou qu’un outil médical met en évidence une tumeur sur une image, une technologie discrète mais puissante est à l’œuvre : la détection d’objets. Cet article de synthèse explique comment la détection d’objets a rapidement évolué au cours de la dernière décennie, des astuces de traitement d’image primitives aux systèmes actuels basés sur des transformers et sur la fusion de plusieurs capteurs, et pourquoi ces avancées comptent pour des rues plus sûres, des robots plus intelligents et des diagnostics médicaux plus précis.
Des pixels aux choses reconnaissables
La détection d’objets consiste à localiser et à étiqueter des éléments spécifiques dans des images ou des vidéos — voitures, cyclistes, animaux, structures médicales, et plus encore. L’article commence par dresser la carte des usages de cette capacité : conduite autonome, surveillance, imagerie médicale et robotique. Les premiers systèmes reposaient sur des règles conçues à la main pour repérer formes et textures, mais les approches modernes apprennent directement à partir des données grâce à l’apprentissage profond. Deux grandes familles dominent aujourd’hui : les réseaux neuronaux convolutionnels (CNN), excellents pour repérer des motifs locaux comme les contours et les coins, et les transformers, qui excellent à comprendre la scène dans son ensemble et les relations entre objets éloignés. Ensemble, ils définissent la façon dont les machines « voient » le monde.
Comment fonctionnent les moteurs de vision classiques
Les méthodes basées sur les CNN alimentent encore de nombreuses applications en temps réel. Elles balayent les images avec de petits filtres pour construire des cartes de caractéristiques de plus en plus riches, puis les transmettent à des têtes de détection qui dessinent des boîtes englobantes et attribuent des étiquettes. La synthèse expose deux stratégies principales. Les systèmes en deux étapes comme Faster R-CNN proposent d’abord des régions d’objet probables, puis les affinent, obtenant souvent une grande précision au prix d’un coût de calcul. Les systèmes en une seule étape comme la famille YOLO sautent l’étape de proposition et prédisent boîtes et étiquettes en une seule passe, échangeant un peu de précision contre la vitesse. Les versions récentes de YOLOv5 et YOLOv8 ont été fortement optimisées — ajoutant des pyramides de caractéristiques plus intelligentes pour les petits objets, des blocs légers pour les appareils embarqués, et des fonctions de perte améliorées — pour atteindre des centaines d’images par seconde tout en restant compétitives sur des benchmarks exigeants.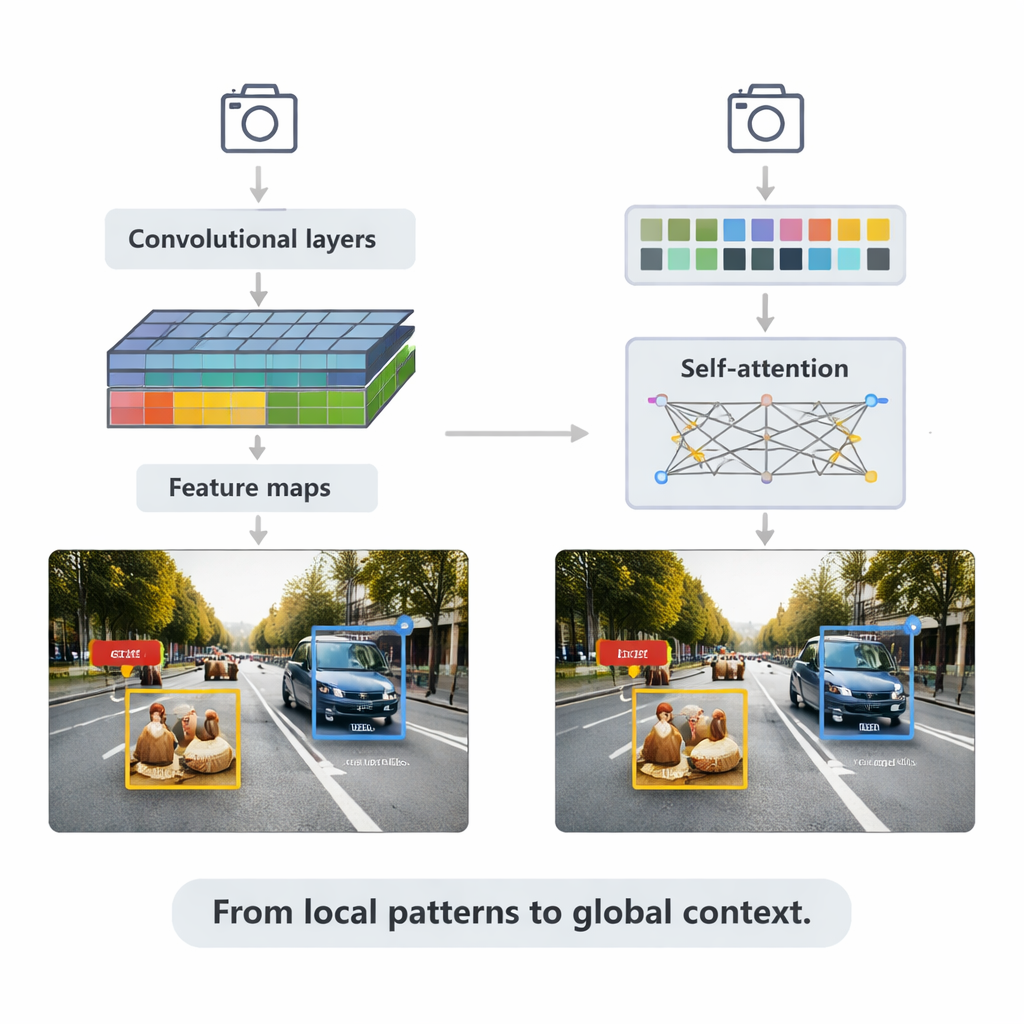
Les transformers et la puissance du contexte
L’article aborde ensuite les transformers, une architecture plus récente empruntée aux modèles de langage. Plutôt que de ne se concentrer que sur les voisinages locaux, les transformers utilisent l’« auto-attention » pour comparer chaque patch d’une image à tous les autres, apprenant quelles régions sont les plus pertinentes pour chaque décision. Detection Transformer (DETR) et ses successeurs suppriment de nombreuses astuces conçues à la main, visant des pipelines plus propres, de bout en bout. Des variantes telles que Deformable DETR et RT-DETR réduisent le calcul et accélèrent l’entraînement, permettant aux transformers de fonctionner en temps réel tout en obtenant certains des meilleurs scores de précision sur le benchmark largement utilisé COCO. Ces modèles excellent particulièrement dans des scènes complexes avec objets qui se chevauchent et arrière-plans confus, où le contexte global aide à distinguer, par exemple, un piéton partiellement masqué derrière une voiture.
Mêler caméras, lasers et langage
Les conditions du monde réel — brouillard, obscurité, éblouissement, encombrement — mettent souvent à mal les systèmes mono-capteur. Un axe majeur de l’article est la fusion multimodale : combiner les données de caméras classiques (RGB), de capteurs de profondeur comme le LiDAR, de caméras thermiques, et même de descriptions textuelles. Les auteurs proposent une taxonomie claire pour décrire ces mélanges : la fusion précoce mélange les données brutes en entrée, la fusion intermédiaire combine des caractéristiques apprises à l’intérieur du réseau, et la fusion tardive agrège les sorties de détecteurs séparés en fin de pipeline. Les « fusion transformers » modernes utilisent des mécanismes d’attention pour aligner ces flux, de sorte que les mesures de distance précises du LiDAR, l’apparence riche des images RGB et les indices sémantiques du langage se renforcent mutuellement. Cette approche améliore la détection pour la conduite autonome, l’imagerie médicale, la compréhension vidéo et les scènes riches en texte.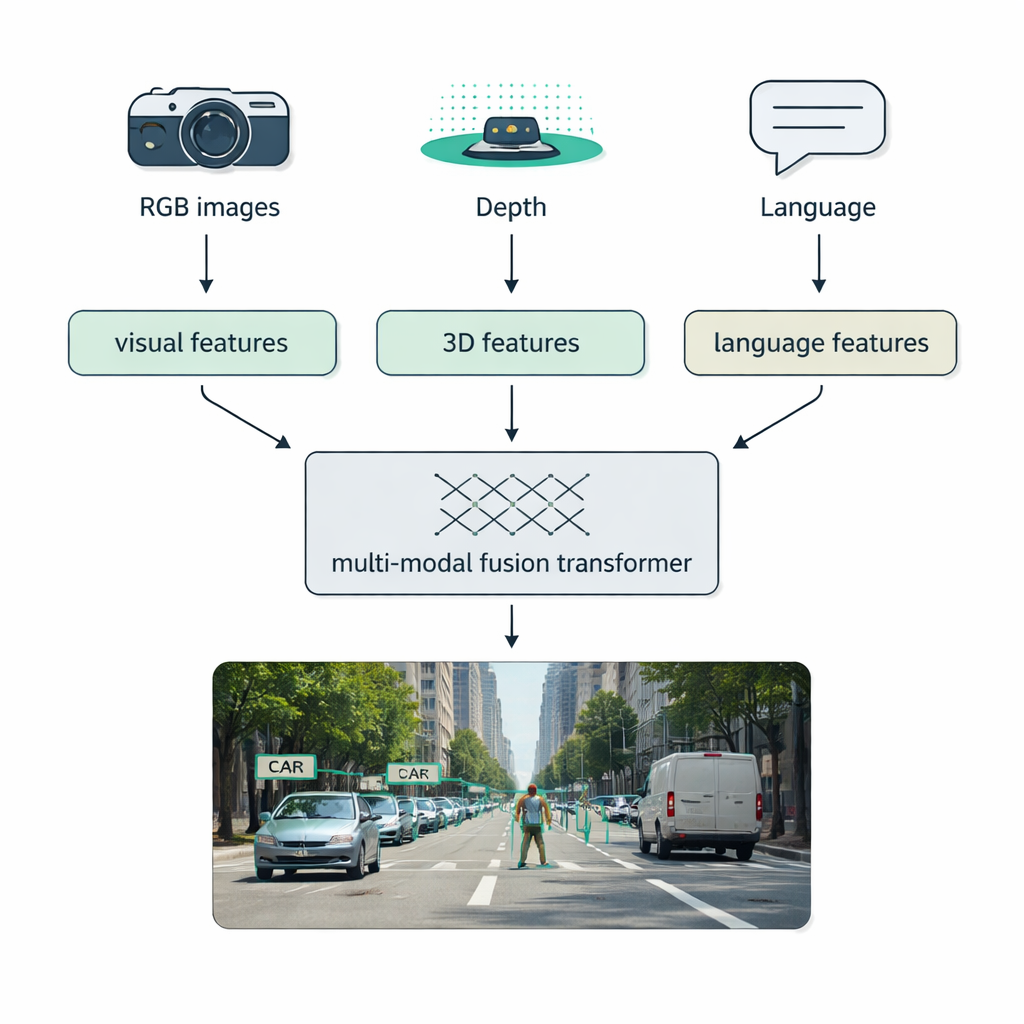
Benchmarks, limites et perspectives
Sur des tests standard comme MS COCO, la synthèse compare détecteurs CNN et transformers en termes de précision et de vitesse. Les CNN classiques en deux étapes demeurent performants mais plus lents, les modèles de type YOLO dominent sur le matériel léger, et les systèmes basés sur les transformers prennent désormais la tête en précision tout en réduisant l’écart de vitesse. Des méthodes spécialisées en infrarouge obtiennent des scores très élevés en conditions de faible visibilité. Pourtant, des défis subsistent : objets très petits ou extrêmement grands, occlusions importantes, variations météo et d’éclairage, et la nécessité de fonctionner de manière fiable sur des appareils très contraints. En regardant vers l’avenir, les auteurs soulignent les tendances vers des modèles de perception unifiés qui gèrent détection, segmentation et légendage ensemble, et des « modèles fondation » qui fusionnent vision et langage pour reconnaître des objets décrits en texte libre, même s’ils n’ont jamais été étiquetés dans les données d’entraînement.
Pourquoi cela importe dans la vie quotidienne
Pour les non-spécialistes, le message clé est que la détection d’objets passe de systèmes étroits et réglés à la main à des moteurs de vision flexibles et polyvalents capables de s’adapter à de nouvelles tâches, de nouveaux environnements et de nouveaux capteurs. Les CNN offrent une reconnaissance de motifs rapide et efficace ; les transformers apportent une compréhension plus globale et contextuelle ; et la fusion multimodale intègre des indices supplémentaires de profondeur, de température et de langage. Ensemble, ces avancées promettent des voitures qui anticipent mieux les dangers, des outils qui aident les médecins avec plus de confiance, et des appareils domestiques qui interagissent de façon plus sûre et plus intelligente avec leur environnement — rapprochant la perception machine de la richesse de la vision humaine.
Citation: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Mots-clés: détection d’objets, vision par ordinateur, apprentissage profond, modèles transformer, fusion multimodale