Clear Sky Science · fr
Un cadre transformer multimodal unifié pour la prédiction de la récidive du cancer du sein et l’analyse de survie
Pourquoi il est important de prédire la réapparition du cancer
Pour de nombreuses femmes, la fin du traitement du cancer du sein apporte un soulagement mêlé d’une question persistante : la maladie va‑t‑elle revenir, et si oui, quand et avec quelle gravité ? Les plans de suivi actuels reposent souvent sur des moyennes générales plutôt que sur la combinaison unique de facteurs propres à chaque patiente. Cette étude présente un nouveau système d’intelligence artificielle qui vise à fournir aux médecins une vision plus claire et personnalisée à la fois du risque de récidive du cancer du sein et de la durée probable pendant laquelle les patientes resteront sans cancer.
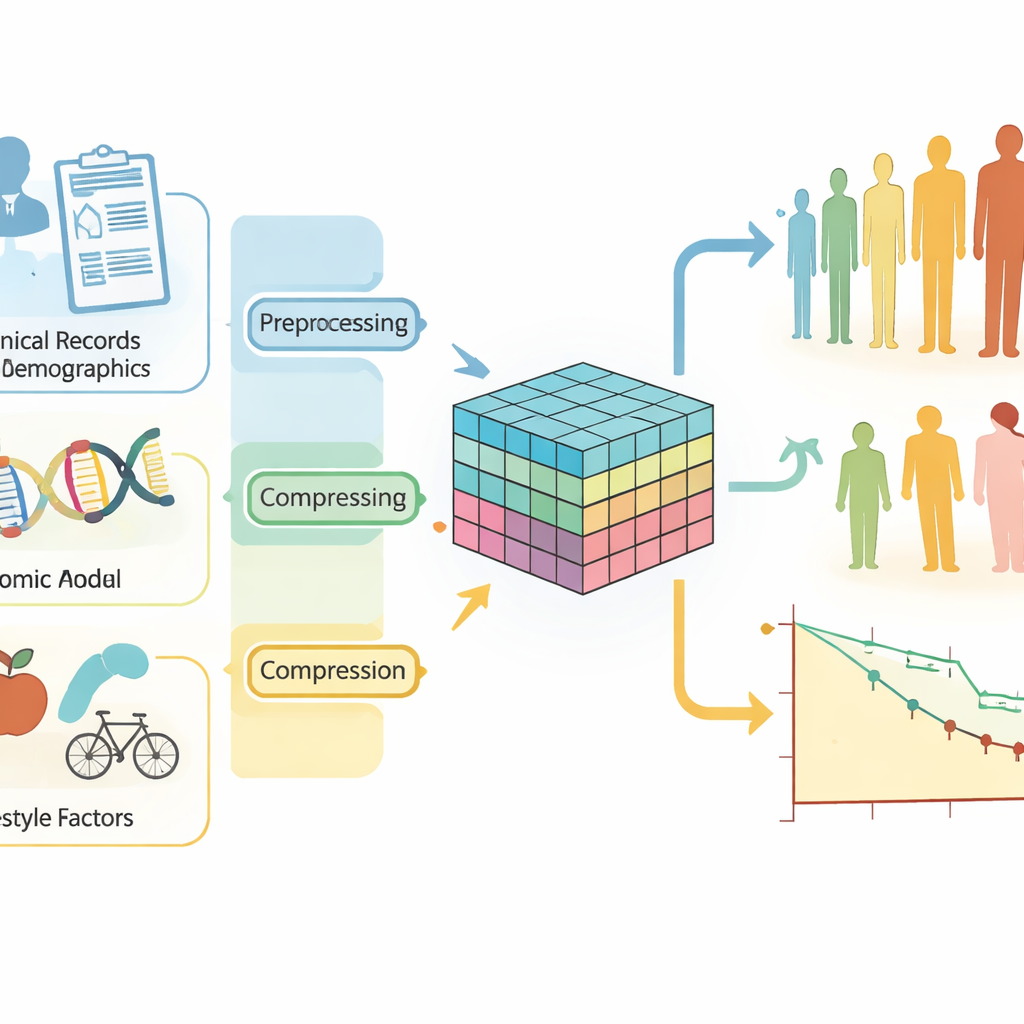
Rassembler plusieurs types de données patient
La récidive du cancer du sein ne se réduit pas à un seul résultat. Elle peut se manifester par une nouvelle tumeur dans le même sein, une propagation aux ganglions lymphatiques voisins ou des métastases à distance dans des organes tels que les poumons ou les os. Chaque scénario a des implications différentes pour le traitement et la survie. Parallèlement, le risque est façonné par de nombreux facteurs imbriqués : caractéristiques tumorales, activité génique, âge, statut ménopausique, poids, tabagisme, et plus encore. Les outils statistiques traditionnels ont du mal face à ce mélange d’informations cliniques, génétiques et liées au mode de vie. Ils supposent typiquement des relations simples et linéaires et reposent souvent sur des scores de risque artisanaux incapables de saisir la véritable complexité des données modernes sur le cancer.
Un modèle intelligent unifié au lieu d’outils séparés
Les chercheurs ont conçu un seul cadre d’apprentissage profond qui traite simultanément deux tâches : il prédit lequel des quatre types de récidive une patiente est la plus susceptible d’expérimenter, et il estime le moment de cet événement via l’analyse de survie. Plutôt que de construire des modèles séparés pour « est‑ce que cela va revenir ? » et « quand cela va‑t‑il revenir ? », le système apprend les deux réponses de concert. Dans les coulisses, il utilise une architecture transformer — la même famille de modèles qui alimente de nombreux outils linguistiques de pointe — pour découvrir des motifs subtils et des interactions à longue portée dans les données. Cette approche unifiée vise à refléter la manière dont les oncologues raisonnent, en pesant simultanément de nombreux indices plutôt qu’en effectuant des calculs isolés.
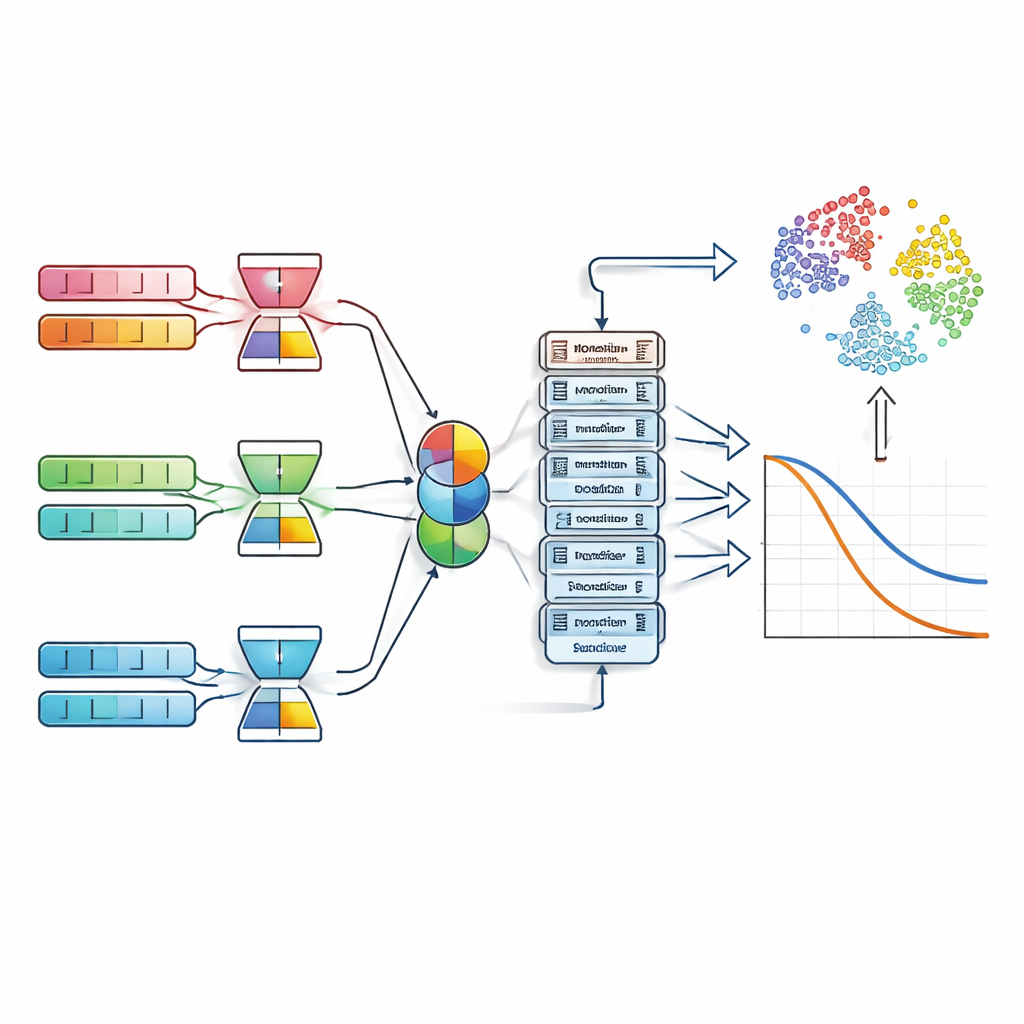
Comment le système détecte les motifs dans les données de santé
Pour alimenter le modèle, l’équipe a rassemblé une large collection multicentrique de dossiers de cancer du sein provenant de cinq sources reconnues. Ces jeux de données comprennent des milliers de patientes avec des mesures cliniques détaillées, des profils d’expression génique, des informations démographiques et des indicateurs de mode de vie. Comme ces données peuvent être bruitées et de très grande dimension — en particulier les dizaines de milliers de mesures d’activité génique — le système fait d’abord passer chaque type de donnée par un « auto‑encodeur débruitant ». Cette étape compresse chaque modalité en une représentation plus propre et compacte qui conserve les signaux biologiques importants tout en filtrant l’aléa.
Apprendre ce qui compte le plus pour chaque patiente
Après la compression, le modèle ne se contente pas d’assembler toutes les caractéristiques. Il applique plutôt un mécanisme d’attention par modalité qui apprend combien de poids accorder aux informations cliniques, génétiques ou liées au mode de vie pour chaque individu. Pour certaines patientes, la taille de la tumeur et le statut des récepteurs hormonaux peuvent dominer ; pour d’autres, un profil génique particulier ou des antécédents de tabagisme peuvent être plus révélateurs. Ces signaux pondérés sont fusionnés en un profil unique de patiente et traités par des couches transformer empilées, qui utilisent l’auto‑attention pour modéliser comment différents facteurs de risque interagissent. À partir de cette représentation commune, une branche prédit le type de récidive, tandis qu’une autre estime un score de risque continu pouvant être traduit en courbes de survie sur cinq et dix ans.
Performance, validation et interprétabilité
Dans des tests portant sur les cinq jeux de données, le système unifié a systématiquement dépassé les méthodes classiques telles que la régression logistique, les machines à vecteurs de support, les forêts aléatoires, les modèles de Cox classiques et les réseaux de neurones plus simples. Il a atteint environ 98–99 % de précision pour la classification du type de récidive et un indice de concordance élevé — une mesure établie de l’adéquation entre l’ordre de survie prédit et la réalité. Des expériences cross‑dataset, où le modèle a été entraîné sur une cohorte et testé sur une autre, ont montré qu’il se généralise mieux que les approches concurrentes. Pour éviter qu’il ne devienne une « boîte noire » mystérieuse, les auteurs ont également utilisé des outils d’explicabilité qui mettent en évidence les caractéristiques ayant le plus influencé chaque prédiction. La taille de la tumeur, le statut HER2, le tabagisme, le statut ménopausique, l’âge au diagnostic et les mutations BRCA1 sont apparus comme particulièrement importants, en cohérence avec les connaissances médicales actuelles.
Ce que cela signifie pour les patientes et les médecins
Le message principal de l’étude est qu’un système d’IA unique, soigneusement conçu, peut intégrer de nombreux fils d’information pour offrir une image plus riche et plus fiable du risque de récidive du cancer du sein et de la survie. Bien qu’il nécessite encore des tests prospectifs en milieu clinique réel, ce cadre pourrait un jour aider les médecins à personnaliser les calendriers de surveillance, choisir les traitements et conseiller les patientes avec une plus grande confiance. Pour les patientes, cela pourrait se traduire par des plans de suivi mieux adaptés à leur niveau réel de risque — réduisant l’anxiété et les examens inutiles pour certaines, tout en signalant d’autres qui pourraient bénéficier d’une surveillance plus rapprochée ou d’une thérapie plus agressive.
Citation: Malik, S., Patro, S.G.K., Al-Nussairi, A.K.J. et al. A unified multi modal transformer framework for breast cancer recurrence prediction and survival analysis. Sci Rep 16, 8334 (2026). https://doi.org/10.1038/s41598-026-37046-4
Mots-clés: récidive du cancer du sein, prédiction de survie, apprentissage profond multimodal, modèle transformer, oncologie personnalisée