Clear Sky Science · fr
Un CNN 1D résiduel profond avec auto-attention pour la détection de transactions frauduleuses dans les économies virtuelles
Pourquoi les mondes virtuels ont besoin de protections du monde réel
Des concerts virtuels aux centres commerciaux numériques, une part croissante de notre argent circule désormais dans des mondes en ligne souvent qualifiés de métavers. Là où l’argent circule, les fraudeurs ne tardent pas à suivre. Cet article examine comment un nouveau type de modèle d’intelligence artificielle peut surveiller ces transactions rapides et difficiles à tracer et signaler en temps réel les comportements à risque, contribuant ainsi à protéger les portefeuilles virtuels des utilisateurs.
L’argent bouge dans le métavers
Dans le métavers, les utilisateurs achètent et vendent des biens numériques, échangent des terrains virtuels et transfèrent des crypto-monnaies entre des portefeuilles répartis dans le monde entier. Ces transactions laissent des traces complexes : horodatages, montants, lieux, détails des appareils, motifs de comportement, et plus encore. Contrairement aux systèmes bancaires traditionnels, ces données sont volumineuses, partiellement anonymes et en flux continu. Les systèmes de détection de fraude classiques, qui prennent généralement une décision binaire sur la fraude, peinent dans ce nouvel environnement. Ils ne sont pas conçus pour gérer des comportements changeants, des identités dissimulées, ni la nécessité d’évaluer chaque transaction en quelques millisecondes.
Transformer des données brutes en signaux utilisables
Les auteurs s’appuient sur un jeu de données public de transactions du métavers contenant près de 80 000 enregistrements, chacun étiqueté comme risque faible, modéré ou élevé. Chaque transaction comprend 14 informations différentes, telles que l’heure de la journée, le type de transaction (par exemple achat, transfert ou escroquerie), la région de l’utilisateur, la fréquence de connexion et un score de risque calculé. Beaucoup de ces éléments sont des mots, pas des nombres, de sorte que l’équipe les convertit d’abord en valeurs numériques à l’aide de schémas de codage simples. Ils corrigent également un problème majeur du monde réel : la plupart des transactions sont sûres, tandis que les transactions à haut risque sont rares. Pour empêcher le modèle « d’apprendre » que tout est sûr, ils dupliquent les cas minoritaires à risque élevé et modéré jusqu’à ce que les trois niveaux de risque soient également représentés.
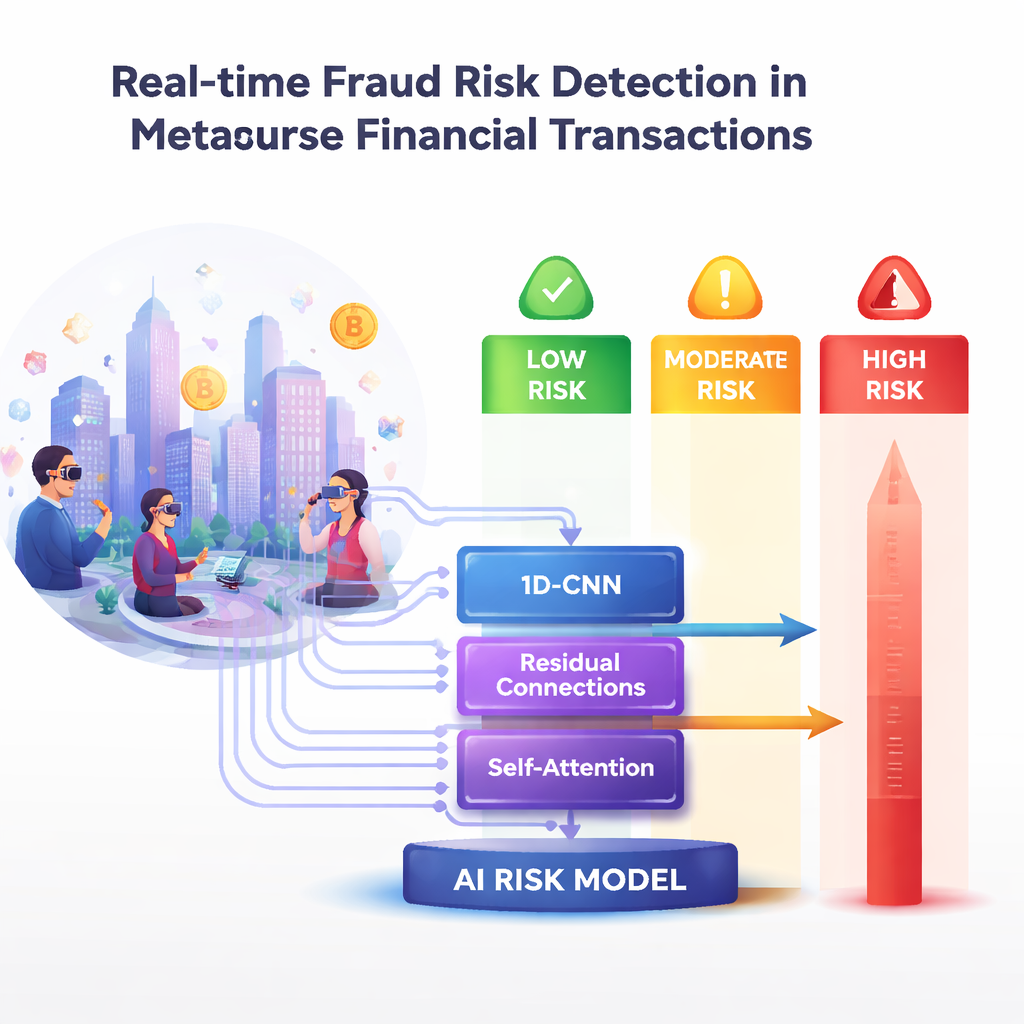
Un modèle d’IA en couches qui accorde de l’attention
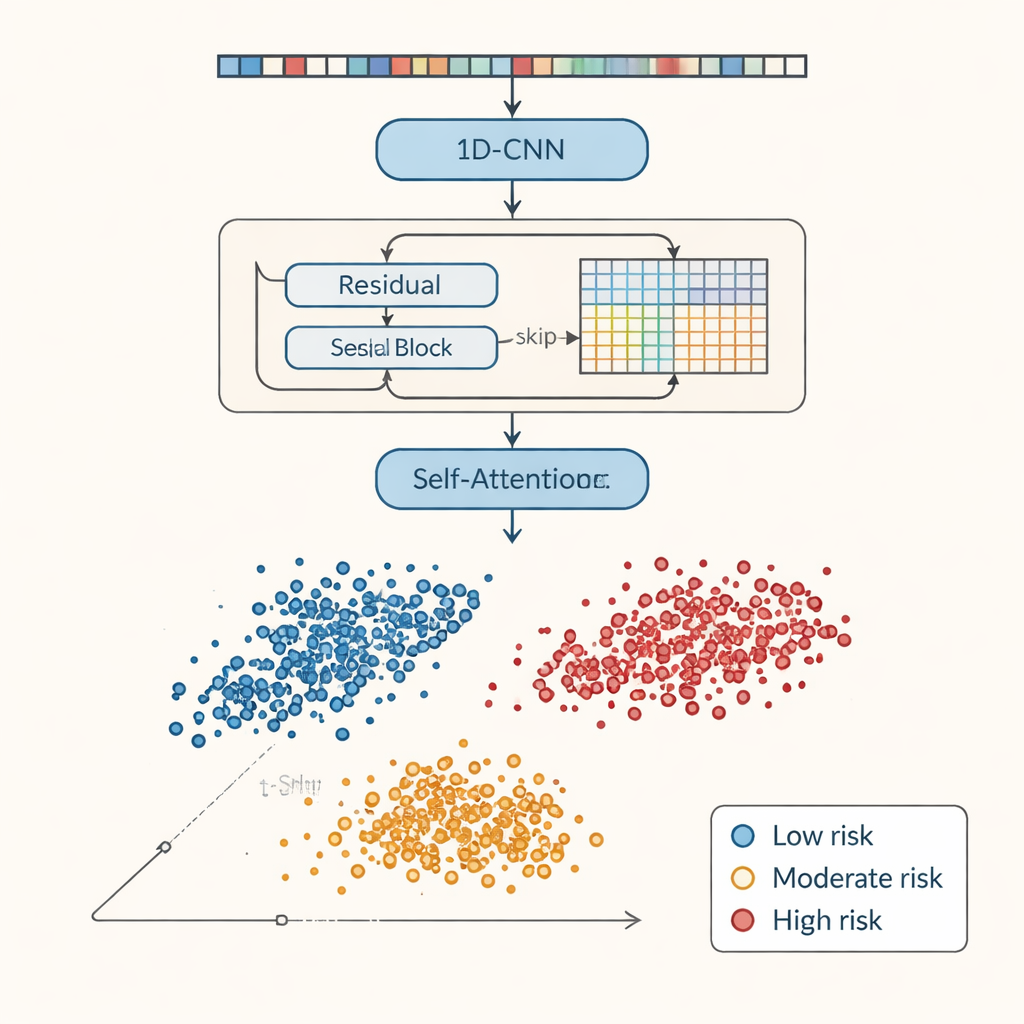
Au cœur du travail se trouve un modèle d’apprentissage profond basé sur un réseau de neurones convolutionnel unidimensionnel, ou 1D-CNN. Ce type de réseau est conçu pour des séquences, et peut donc traiter les caractéristiques d’une transaction comme une courte série temporelle plutôt que comme un instantané statique, captant des motifs locaux subtils dans l’alignement des attributs. Au-dessus de cela, les auteurs ajoutent deux évolutions modernes. Les connexions résiduelles agissent comme des raccourcis qui facilitent le flux d’information à travers les couches, rendant l’entraînement de réseaux plus profonds plus aisé sans blocage. Un mécanisme d’auto-attention apprend ensuite quelles parties de chaque transaction importent le plus pour déterminer son niveau de risque, en attribuant un poids plus élevé à des indices tels que des scores de risque anormalement élevés ou des schémas d’achat suspects.
Mettre le système à l’épreuve
Une fois entraîné, le modèle est évalué de plusieurs manières. Sur le jeu de données équilibré du métavers, il classe les transactions à risque faible, modéré et élevé avec des scores parfaits selon les mesures standard : chaque cas à risque dans l’ensemble de test est détecté et correctement étiqueté. La validation croisée, qui mélange et segmente les données à plusieurs reprises, confirme que cette performance est stable et non le fruit du hasard sur une seule partition. Les auteurs comparent également des variantes de leur architecture — n’utilisant que le 1D-CNN, n’ajoutant que les connexions résiduelles, n’ajoutant que l’attention, ou combinant les deux — et constatent que toutes atteignent une précision globale similaire sur cet ensemble propre, bien que la version complète soit plus lente à entraîner. Pour tester la robustesse, ils ajoutent délibérément différentes formes de bruit et de distorsions : la performance décline en cas de corruption importante mais reste solide lorsque des caractéristiques sont simplement manquantes de manière aléatoire. Des outils visuels tels que des graphiques t-SNE montrent qu’après traitement, les transactions se regroupent clairement en trois groupes correspondant aux niveaux de risque, ce qui suggère que le modèle a réellement séparé les comportements sous-jacents.
Au-delà du métavers : la fraude traditionnelle aussi
Pour vérifier la généralisation de leur approche, l’équipe applique le même 1D-CNN amélioré à un jeu de données largement utilisé de fraude par carte de crédit en Europe, qui souffre également d’un fort déséquilibre de classes. Après avoir équilibré uniquement la portion d’entraînement et laissé l’ensemble de test intact, le modèle atteint environ 94 % de précision et des mesures similaires de précision et de rappel sur les cas de fraude. Cela indique que l’architecture n’est pas uniquement adaptée aux données du métavers, mais peut aussi traiter des transactions par carte plus familières, offrant une façon unifiée d’évaluer le risque tant pour les systèmes financiers virtuels que traditionnels.
Ce que cela signifie pour les utilisateurs quotidiens
Pour le grand public, le message clé est simple : à mesure que nous passons plus de temps et dépensons davantage dans les mondes numériques, nous avons besoin de gardiens plus intelligents aux portes. Cette étude montre qu’un modèle d’IA soigneusement conçu peut trier les flux bruyants et changeants des transactions du métavers et séparer l’activité routinière des comportements véritablement suspects, tout en fonctionnant bien sur des données de carte de crédit ordinaires. Bien que les auteurs reconnaissent qu’une performance parfaite sur des jeux de données propres et proches du synthétique est peu susceptible de se maintenir dans tous les contextes réels, leurs tests de bruit et de contrainte suggèrent une base solide. En pratique, de tels systèmes pourraient aider les plateformes et les banques à repérer tôt les schémas dangereux, à réduire les pertes liées à la fraude et à donner aux utilisateurs une plus grande confiance que leurs actifs virtuels sont surveillés en temps réel.
Citation: Mohammed, K.K., Abdo, A.S., Darwish, A. et al. A deep residual 1D-CNN with self-attention for fraud transaction detection in virtual economies. Sci Rep 16, 6150 (2026). https://doi.org/10.1038/s41598-026-37032-w
Mots-clés: finance du métavers, détection de fraude, apprentissage profond, classification du risque, transactions virtuelles