Clear Sky Science · fr
Évaluation du statut fonctionnel en mobilité dans les dossiers de santé électroniques à l’aide de grands modèles de langage
Pourquoi la capacité de marche est un indicateur de santé puissant
À mesure que la durée de vie augmente, les médecins s’intéressent davantage non seulement à la longévité, mais aussi à la qualité des mouvements, de la marche et de l’autonomie. Des difficultés pour se lever d’une chaise, monter des escaliers ou circuler en ville apparaissent souvent bien avant une crise médicale. Pourtant, les descriptions les plus détaillées des capacités quotidiennes d’une personne se trouvent généralement enfouies dans des notes libres de médecins et de thérapeutes dans les dossiers de santé électroniques, où elles sont difficiles à retrouver par des ordinateurs. Cette étude examine si les grands modèles de langage modernes — le même type d’IA qui alimente de nombreux chatbots — peuvent lire de manière fiable ces notes et transformer les descriptions de mobilité en informations structurées et consultables.
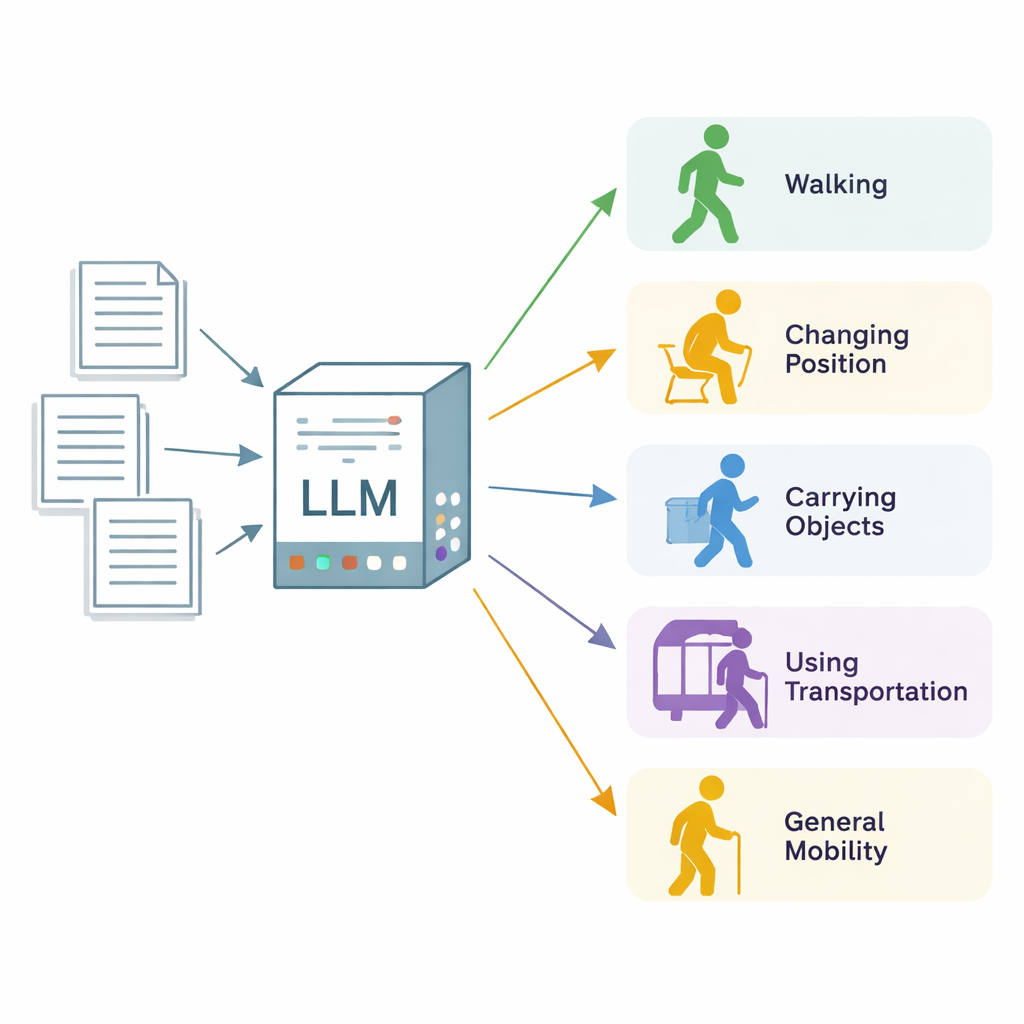
Transformer des notes désordonnées en données de mobilité exploitables
Les chercheurs se sont concentrés sur le « statut fonctionnel en mobilité », un terme générique décrivant la capacité d’une personne à changer de position corporelle, marcher, porter et manipuler des objets, utiliser les transports et se déplacer dans la vie quotidienne. Ils ont utilisé 600 notes cliniques réelles provenant de trois établissements de soins du Minnesota et du Wisconsin, pour la plupart issues de séances de physiothérapie et d’ergothérapie, ainsi qu’un ensemble de notes de consultation plus générales. Des annotateurs experts ont passé chaque note au peigne fin, section par section, et ont étiqueté chaque passage décrivant l’une des cinq catégories de mobilité, en indiquant si le patient était clairement limité (« altéré ») ou fonctionnait normalement (« non altéré »). Ces annotations d’experts ont servi de référence d’or pour évaluer le système d’IA.
Comment le modèle d’IA a été entraîné à lire comme un clinicien
L’équipe a utilisé Llama 3, un grand modèle de langage open source, et l’a exécuté sur des serveurs locaux sécurisés afin que les données des patients ne quittent jamais le système de santé. Plutôt que de réentraîner le modèle depuis zéro, ils ont conçu des invites (prompts) soignées — des ensembles d’instructions écrites et de définitions — pour apprendre au modèle ce qu’il devait repérer. Ils ont testé des invites « zero‑shot », qui donnent uniquement des instructions, et des invites « few‑shot », qui incluent aussi quelques notes d’exemple. Ils ont ensuite analysé les erreurs du modèle et élaboré une invite « informée par les erreurs » qui précisait ce qu’il fallait inclure, ce qu’il fallait ignorer (comme les plans de traitement futurs) et comment gérer les cas délicats tels que les chutes, les étourdissements ou l’utilisation d’un fauteuil roulant. L’IA devait, pour chaque section de note et pour chaque catégorie de mobilité, indiquer si la mobilité était mentionnée et, le cas échéant, si le patient était altéré.
De bonnes performances, meilleures au niveau du patient
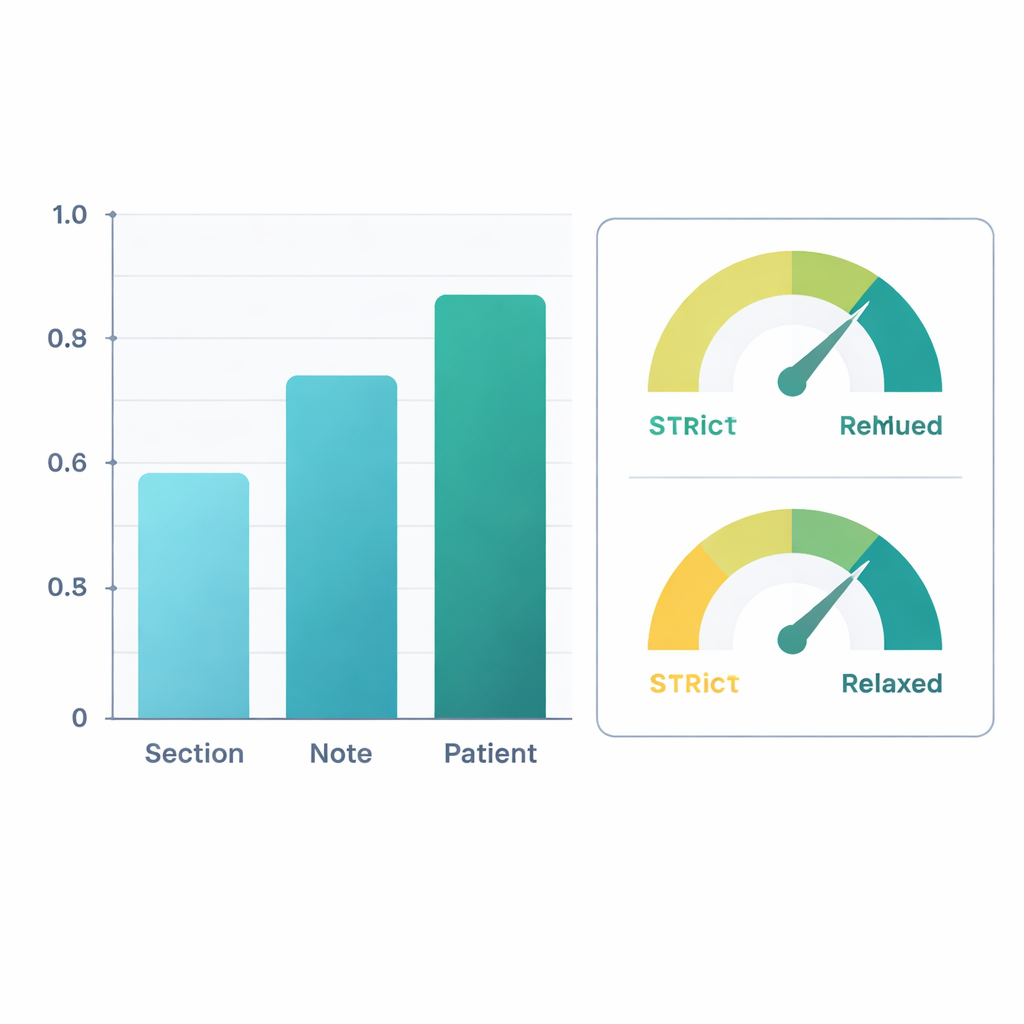
Comparé aux annotations d’experts, le système affiné a bien fonctionné. Au niveau du patient — en combinant les informations de toutes ses notes — l’IA a atteint un score F1 (une mesure courante de précision) d’environ 0,88 pour la détection simple d’informations sur la mobilité et de 0,90 pour la détermination de l’altération. Cela signifie que ses jugements concordaient étroitement avec ceux des évaluateurs humains. Les performances étaient un peu plus faibles au niveau des sections individuelles des notes, où la formulation peut être parcimonieuse ou ambiguë, mais la précision s’est améliorée à mesure que l’information était agrégée sur l’ensemble d’une note, puis sur toutes les notes d’un patient. Dans une seconde analyse, les chercheurs ont considéré comme correctes des « inférences cliniquement raisonnables » — par exemple, supposer qu’une douleur sévère au genou pendant la marche limite probablement la marche, même si cela n’est pas explicitement indiqué. Sous ce prisme plus indulgent, les scores F1 au niveau patient ont dépassé 0,96 pour l’extraction et 0,95 pour la classification de l’altération.
Ce que l’IA s’est trompée — et pourquoi cela reste significatif
La plupart des erreurs provenaient d’inférences du modèle. Il a souvent déduit des problèmes de mobilité à partir de la douleur, des étourdissements ou des plans de traitement futurs, alors que la note n’indiquait pas clairement que le patient était limité. D’autres erreurs reflétaient des zones grises dans les définitions, par exemple pour savoir si des chutes répétées devaient être considérées comme un problème de marche ou un problème d’équilibre lors d’un changement de position. La catégorie « mobilité, non spécifiée », destinée à couvrir les activités quotidiennes et l’exercice, était particulièrement difficile à cerner. Malgré ces limites, les erreurs étaient généralement raisonnables d’un point de vue clinique plutôt que aléatoires ou aberrantes. En exécutant le modèle de manière déterministe (sans génération aléatoire) sur des serveurs locaux verrouillés, l’équipe a aussi garanti la reproductibilité des résultats et la préservation de la confidentialité des patients.
Comment cela pourrait transformer les soins des personnes âgées
Pour un non‑spécialiste, la conclusion est qu’un système d’IA peut désormais lire les notes routinières de médecins et de thérapeutes suffisamment bien pour résumer les capacités de mouvement des patients et leurs difficultés. Cela signifie que les systèmes de santé pourraient suivre, sans ajouter de nouveaux questionnaires ou tests, l’évolution de la marche, de l’équilibre et des activités quotidiennes, repérer les personnes à risque élevé de chutes ou d’hospitalisation, et identifier celles qui pourraient bénéficier de physiothérapie ou d’évaluations de la sécurité à domicile. En convertissant des millions de notes en texte libre en données structurées sur la mobilité, cette approche aide les cliniciens à mieux appréhender l’impact du vieillissement et des maladies sur la vie quotidienne — rapprochant les soins d’une médecine véritablement personnalisée et centrée sur le fonctionnement.
Citation: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Mots-clés: mobilité, dossiers de santé électroniques, grands modèles de langage, statut fonctionnel, IA clinique