Clear Sky Science · fr
Un benchmark pour évaluer l’efficacité des questionnements diagnostiques des LLM dans les conversations avec des patients
Pourquoi des questions médicales plus pertinentes comptent
Lorsque vous consultez un médecin, le premier diagnostic que vous entendez provient rarement d’un seul symptôme que vous mentionnez. Les médecins posent plutôt une série de questions de suivi — sur la chronologie, l’intensité, les problèmes associés — pour réduire progressivement ce qui pourrait être en cause. Aussi puissants que soient les systèmes d’IA actuels, la plupart sont encore évalués comme s’ils passaient des examens à choix multiple, et non comme s’ils parlaient à de vraies personnes. Cet article présente Q4Dx, une nouvelle manière d’évaluer la capacité des grands modèles de langage (LLM) à jouer le rôle du « médecin curieux » : choisir les bonnes questions, dans le bon ordre, pour aboutir efficacement au bon diagnostic.
Des questions d’examen aux conversations réelles
La plupart des tests d’IA médicale existants donnent aux modèles des cas bien propres et entièrement spécifiés — comme un problème de manuel — et leur demandent de choisir un diagnostic. Cela montre ce que le système « sait », mais pas comment il se comporterait dans une conversation désordonnée et réelle avec un patient qui oublie des détails ou décrit ses symptômes en langage courant. Les auteurs soutiennent qu’il s’agit d’un angle mort sérieux. En clinique, l’information sort lentement et souvent de façon inexacte ; la compétence d’un bon clinicien tient autant à ce qu’il demande qu’à ce qu’il sait déjà. Q4Dx vise à combler ce fossé en déplaçant l’attention du simple question‑réponse statique vers la stratégie de questionnement au fil du temps.
Construire des récits de patients crédibles
Pour créer ce nouveau banc d’essai, les chercheurs partent d’une ressource médicale soigneusement sélectionnée qui relie des maladies spécifiques à des ensembles caractéristiques de symptômes. Ils choisissent au hasard 100 de ces paires maladie–symptômes, puis utilisent un modèle d’IA pour transformer des listes de symptômes stériles en descriptions naturelles que des patients pourraient effectivement donner en consultation. À partir de chaque cas complet, ils génèrent des versions abrégées où seulement environ 80 % ou 50 % des symptômes clés sont mentionnés. Cette « dissimulation » contrôlée d’information leur permet d’étudier comment différents modèles s’adaptent lorsque des indices importants sont manquants ou seulement suggérés. Des vérifications du recoupement des symptômes confirment que les versions courtes contiennent réellement moins d’informations exploitables, et pas seulement moins de mots.
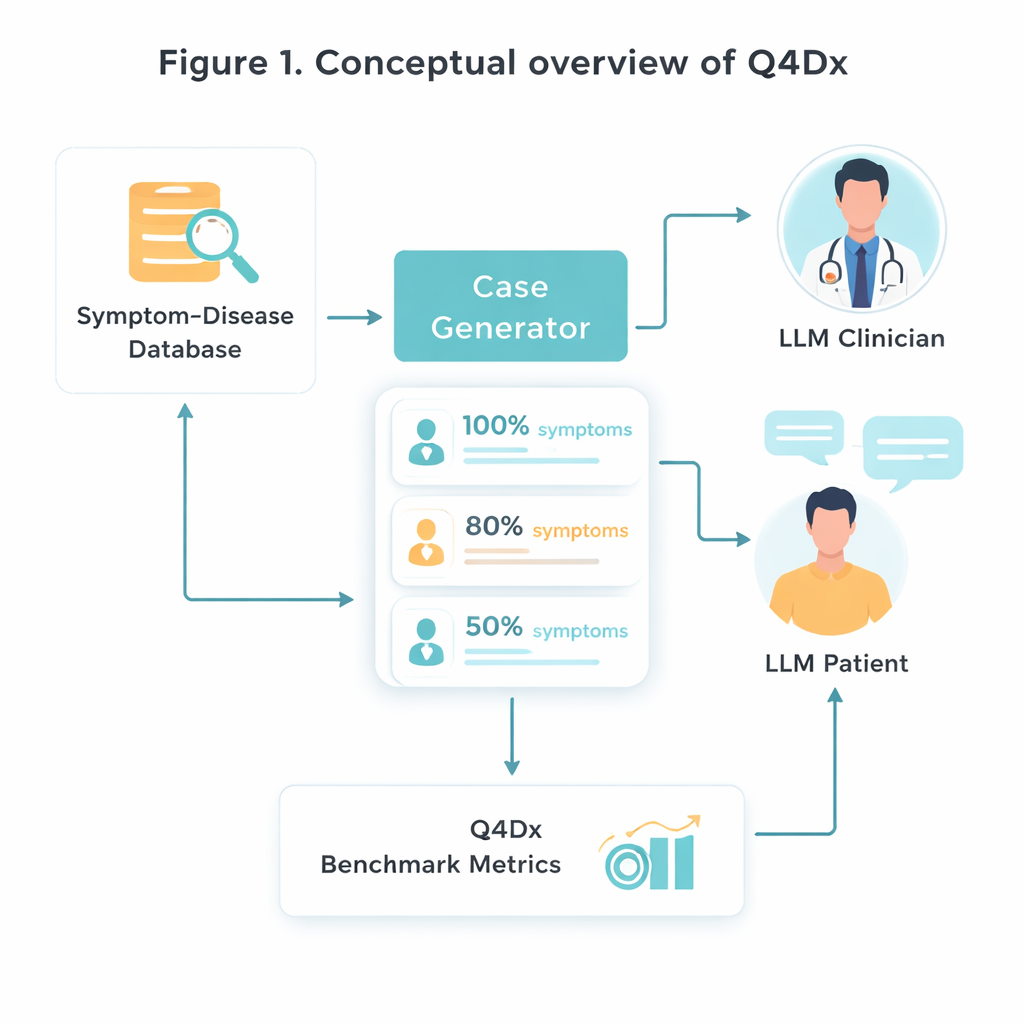
Dialogues simulés médecin–patient
Le cœur de Q4Dx est une vaste collection de conversations simulées entre deux agents d’IA. L’un joue le rôle du patient, ayant un accès complet à la maladie sous‑jacente et à l’ensemble complet des symptômes. L’autre joue le rôle du médecin : il ne voit au départ qu’une description partielle, éventuellement vague, et doit décider quoi demander ensuite. Après chaque réponse du patient, l’agent médecin émet un diagnostic provisoire, créant une trace pas à pas de l’évolution de sa réflexion. En enregistrant toutes les questions, réponses et suppositions intermédiaires, le benchmark capture non seulement si le modèle a raison, mais comment il y parvient. Ces séquences de questions générées par l’IA servent de stratégies de référence — pas comme une vérité médicale parfaite, mais comme une jauge cohérente contre laquelle confronter de futurs modèles et même des stagiaires humains.
Mesurer de bonnes questions, pas seulement des bonnes réponses
Pour évaluer la performance, les auteurs conçoivent trois mesures simples mais complémentaires. L’exactitude diagnostique en Zero‑Shot (ZDA) demande : si l’on fournit au modèle le cas complet d’emblée, peut‑il immédiatement nommer la maladie correcte ? Le nombre moyen de questions jusqu’au diagnostic correct (MQD) reflète l’efficacité : en moyenne, combien de questions au patient le modèle doit‑il poser avant d’aboutir pour la première fois au bon diagnostic, avec un plafond fixé à cinq ? Enfin, l’efficacité de la séquence d’interrogation (ISE) examine la qualité du cheminement de questionnement lui‑même — à quel point les questions choisies par le modèle sont‑elles, en signification, similaires à la séquence de référence. À l’aide de ces métriques, l’équipe montre qu’un modèle généraliste performant (GPT‑4.1) diagnostique correctement environ la moitié du temps avec l’information complète, mais que sa précision chute lorsque des symptômes sont cachés. En revanche, ses sessions interactives réussissent généralement après seulement quelques questions bien choisies, et ses questions s’alignent de plus en plus sur des stratégies proches de l’expertise au fil des tours.

Ce que cela implique pour l’IA médicale future
Pour les non‑spécialistes, le propos de ce travail est simple : en médecine, poser des questions pertinentes est aussi important que d’avoir les bonnes réponses, et l’IA doit être évaluée sur les deux aspects. Q4Dx offre un cadre réutilisable et public pour faire exactement cela. En fournissant des récits de patients réalistes avec des quantités variables d’informations manquantes, des traces de conversation détaillées et des mesures claires de précision et d’efficacité, le benchmark permet aux chercheurs de comparer différents systèmes d’IA et même de les confronter à des cliniciens humains dans des conditions contrôlées. Avec le temps, des outils comme Q4Dx pourraient aider à former des assistants cliniques plus sûrs et plus fiables et améliorer la manière dont médecins et étudiants apprennent l’entretien diagnostique — soutenant en fin de compte de meilleurs soins pour de vrais patients.
Citation: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Mots-clés: IA médicale, raisonnement diagnostique, dialogue clinique, grands modèles de langage, stratégie de questionnement