Clear Sky Science · fr
MQADet : un paradigme plug-and-play pour améliorer la détection d’objets à vocabulaire ouvert via le question‑answering multimodal
Pourquoi des détecteurs d’objets plus intelligents comptent
Téléphones, voitures, robots domestiques et moteurs de recherche dépendent de plus en plus de logiciels capables de repérer des objets dans des images : un enfant traversant la rue, vos clés perdues sur une table, ou un produit précis sur une étagère. Mais la plupart des systèmes actuels ne comprennent que des étiquettes courtes et simples comme « chien » ou « voiture ». Lorsque vous décrivez « le petit chien avec un collier rouge allongé derrière le coussin du sofa », ils s’embrouillent souvent. Cet article présente MQADet, une méthode pour améliorer des systèmes existants de localisation d’objets afin qu’ils comprennent des descriptions riches et détaillées sans réentraîner les modèles sous-jacents.
Passer de listes fixes à une compréhension ouverte
Les détecteurs d’objets traditionnels sont entraînés sur des listes de catégories fixes, comme les 80 objets du quotidien du jeu de données COCO. Ils fonctionnent bien tant que l’objet appartient à l’une de ces catégories et que la requête est courte et claire. Cependant, le monde réel est désordonné. Les gens désignent les choses avec de longues phrases, des attributs subtils et des relations comme « l’homme en gilet jaune se tenant derrière le camion ». Les détecteurs « à vocabulaire ouvert » plus récents cherchent à s’affranchir des listes figées en reliant images et texte, mais ils peinent encore avec les formulations complexes et les catégories rares, dites « long‑tail », qui apparaissent peu dans les données d’entraînement. Ils exigent aussi beaucoup de calcul et de données pour s’améliorer.
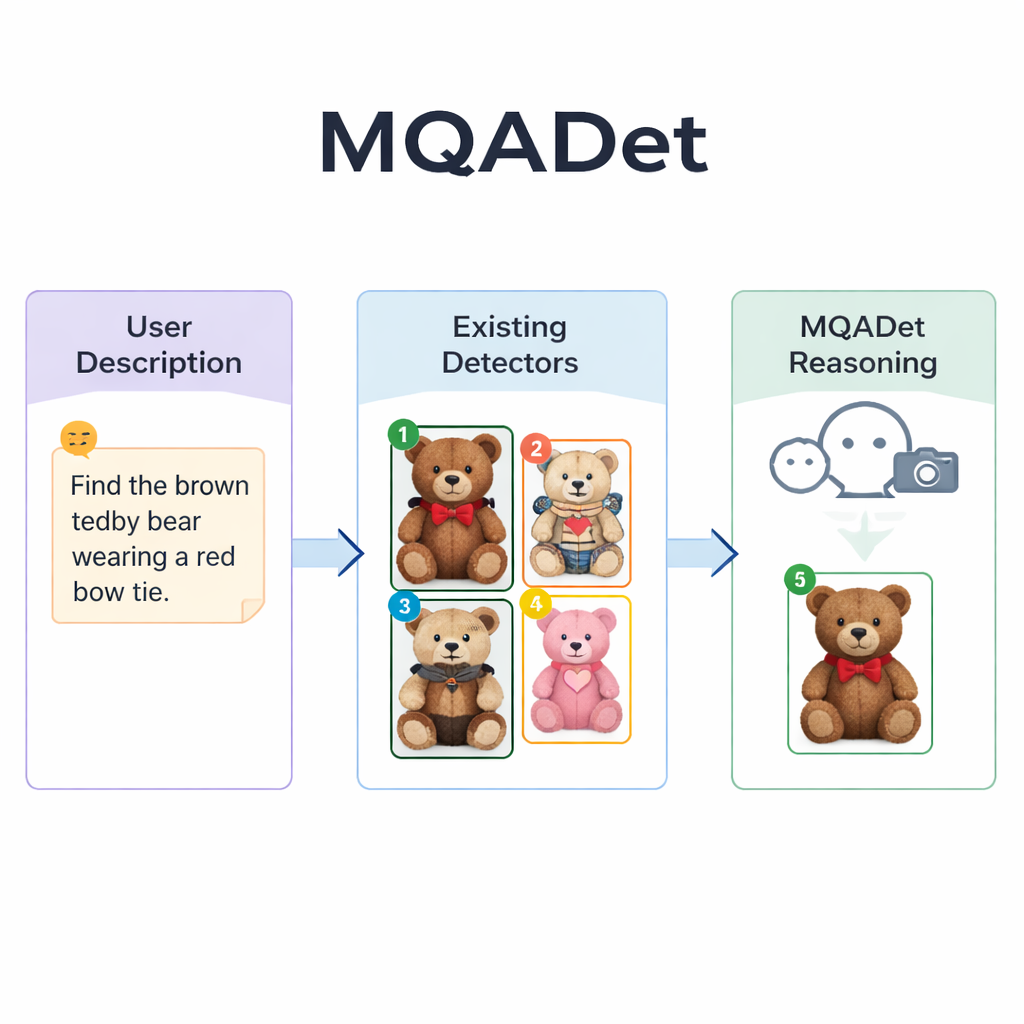
Laisser les modèles de langage guider la recherche
MQADet aborde ces problèmes en plaçant un grand modèle de langage multimodal — un système capable d’analyser des images et de lire du texte — au‑dessus des détecteurs existants dans un processus en trois étapes de question‑réponse. D’abord, une étape appelée Extraction de Sujet Sensible au Texte lit la phrase complète de l’utilisateur et en extrait les cibles réelles, par exemple « parapluie » et « piéton » à partir d’une description longue. Cela reflète la façon dont une personne identifie rapidement les noms principaux dans une phrase avant de balayer une scène. Crucialement, cette étape exploite la forte maîtrise du langage naturel par le modèle, ce qui lui permet de traiter des phrases longues et descriptives plutôt que de simples mots isolés.
Marquer des objets candidats dans l’image
Lors de la deuxième étape, Positionnement Multimodal d’Objets Guidé par le Texte, MQADet transmet ces sujets extraits ainsi que l’image à un détecteur à vocabulaire ouvert existant — par exemple Grounding DINO, YOLO‑World ou OmDet‑Turbo. Le détecteur propose plusieurs emplacements possibles dans l’image où chaque sujet pourrait se trouver, dessinant une boîte autour de chaque candidat et plaçant un numéro simple à l’intérieur. Le résultat est une « image marquée » montrant toutes les options plausibles. Il est important de noter que MQADet ne réentraîne pas ces détecteurs ; il les utilise tels quels. Cela rend l’approche plug‑and‑play : lorsqu’un meilleur détecteur apparaît, il peut être intégré au pipeline sans données supplémentaires ni réglages.

Raisonner pour trouver la meilleure correspondance
La troisième étape, appelée Sélection Optimale d’Objets Pilotée par les MLLM, transforme le choix final en une question à choix multiple pour le modèle de langage : étant donné la description d’origine et l’image marquée avec des boîtes numérotées, quel numéro correspond le mieux au texte ? Parce que le modèle voit à la fois la formulation détaillée et la disposition visuelle, il peut peser des indices fins — motifs, couleurs, relations spatiales comme « à gauche », et interactions entre objets. Les auteurs montrent que supprimer cette étape de raisonnement réduit nettement la précision, ce qui souligne son importance. Grâce à ce design en trois étapes, MQADet améliore la précision sur quatre benchmarks exigeants composés de phrases naturelles longues, augmentant souvent la performance des détecteurs existants de 10 à 40 points de pourcentage sans modifier leurs poids internes.
Ce que cela signifie pour la technologie quotidienne
Pour un non‑spécialiste, le message clé est que nous n’avons plus besoin de reconstruire les détecteurs d’objets depuis zéro pour les rendre plus intelligents. MQADet agit comme un assistant intelligent posé sur les systèmes actuels, les aidant à interpréter des descriptions humaines riches et à choisir le bon objet dans des scènes complexes. Cela pourrait rendre la recherche visuelle, les outils d’assistance et les machines autonomes plus fiables face à la façon naturelle de parler des gens — pleine de détails, de nuances et de contexte — ouvrant la voie à des interactions visuelles plus intuitives pilotées par le langage.
Citation: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Mots-clés: détection d’objets à vocabulaire ouvert, grands modèles de langage multimodaux, question-réponse visuelle, vision par ordinateur, compréhension d’image