Clear Sky Science · fr
Application de l’apprentissage automatique à la prédiction des résultats du traitement du cancer du côlon
Pourquoi il est important de prédire les résultats du cancer du côlon
Le cancer du côlon est l’un des cancers les plus fréquents dans le monde, et de nombreux patients et leurs proches veulent savoir une chose simple et pressante : « Quelles sont mes chances, et que peut-on faire pour les améliorer ? » Cette étude menée en Iran examine comment des techniques informatiques modernes, appelées apprentissage automatique, peuvent analyser des dossiers médicaux détaillés pour mieux prédire quels patients présentent un risque accru après une chirurgie. En affinant ces prédictions, les médecins pourraient adapter le traitement et le suivi de façon plus précise, offrant ainsi aux patients vulnérables de meilleures chances de survie à long terme.
Transformer les dossiers hospitaliers en motifs utiles
Les chercheurs se sont appuyés sur dix ans de données provenant de 764 personnes ayant subi une chirurgie pour cancer du côlon dans un grand centre de Shiraz, en Iran. Pour chaque patient, ils ont recueilli 44 éléments d’information, notamment l’âge, les analyses sanguines, la taille de la tumeur, le stade du cancer, les symptômes, ainsi que les détails de l’intervention et des traitements tels que la chimiothérapie. Ces dossiers ont été nettoyés et vérifiés avec soin : les valeurs de laboratoire impossibles ont été corrigées, les patients non suivis ont été exclus, et les données manquantes ont été complétées par des estimations raisonnables. L’équipe a ensuite divisé les données de sorte que la majeure partie serve à entraîner les modèles informatiques, tandis qu’une portion séparée était réservée pour tester la capacité de ces modèles à prédire qui serait vivant ou décédé au moment du suivi.
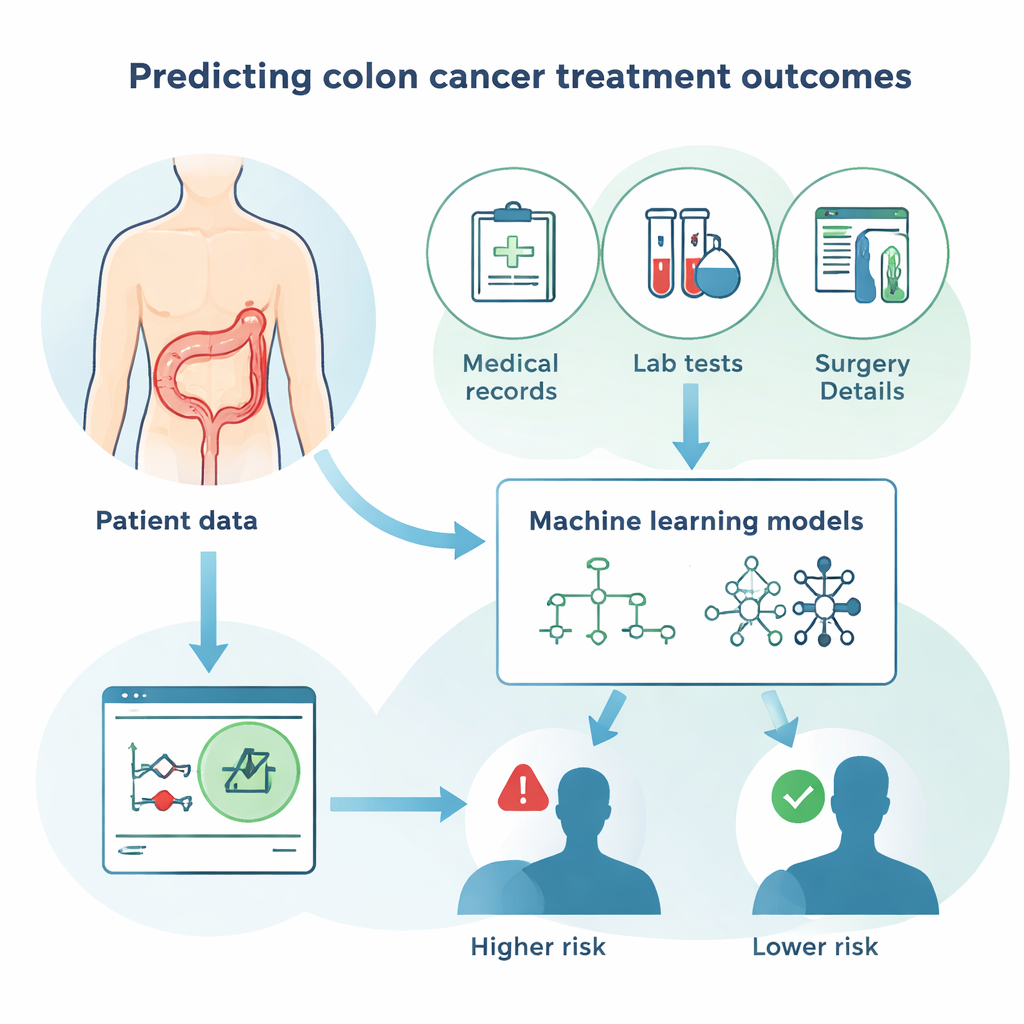
Comment les algorithmes apprennent à partir des patients
Plutôt que de s’appuyer uniquement sur la statistique traditionnelle, l’étude compare plusieurs approches informatiques modernes côte à côte. Celles-ci incluent différentes méthodes de « forêt » et de « boosting », qui combinent de nombreuses règles de décision simples, ainsi que des réseaux de neurones, qui imitent de façon lâche la manière dont les cellules cérébrales se connectent. L’objectif pour chaque méthode était le même : utiliser les informations des patients pour deviner si chaque personne survivrait, puis comparer ces prédictions avec la réalité. Les modèles ont été évalués sur leur exactitude globale, leur capacité à détecter les patients décédés, et leur aptitude à éviter les fausses alertes pour ceux qui ont survécu. Les méthodes les plus performantes ont atteint environ 80 % d’exactitude globale, un résultat solide au regard de la complexité des issues liées au cancer.
Quels modèles et facteurs ont le plus compté
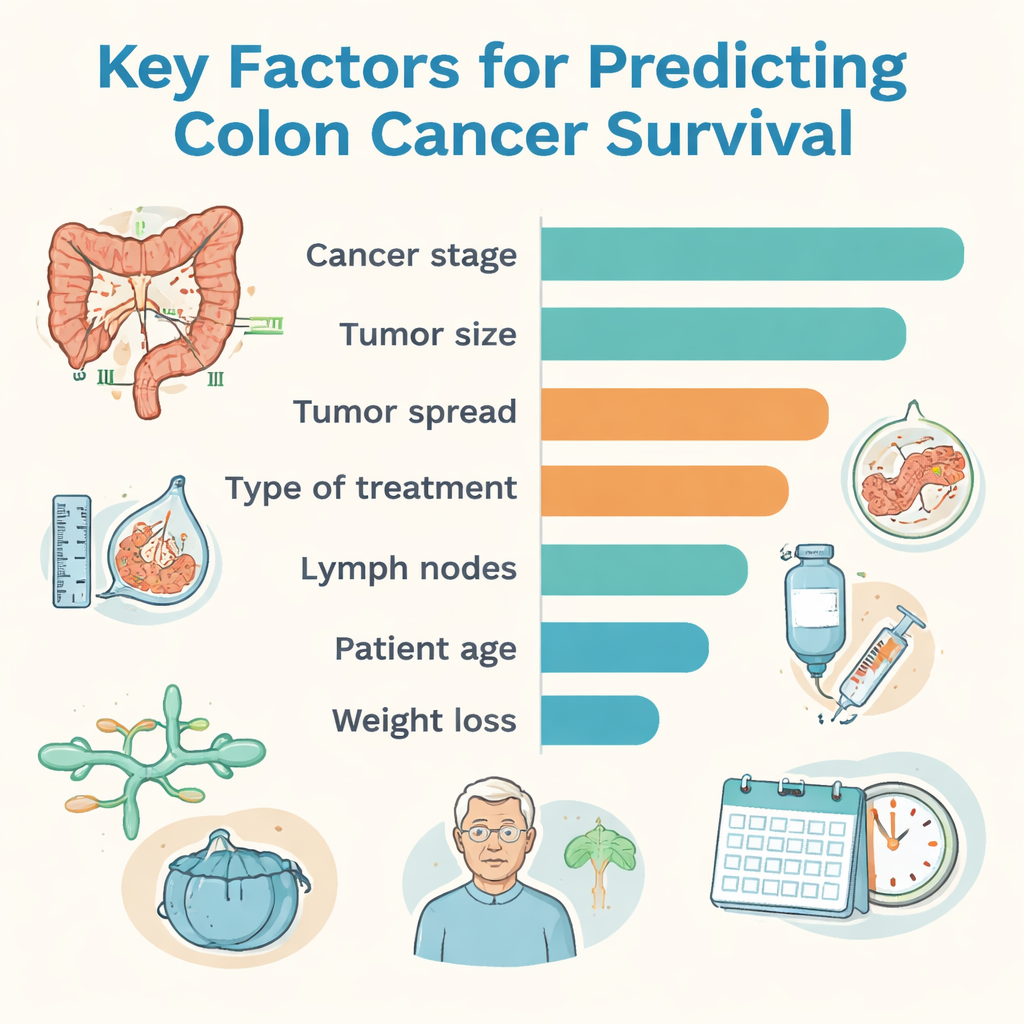
Parmi toutes les approches, une méthode appelée CatBoost a fourni la meilleure exactitude globale, tandis qu’un modèle de forêt aléatoire a montré le meilleur équilibre entre la détection correcte des patients à haut risque et l’absence de sur-détection du risque chez ceux qui s’en sont bien sortis. Pour rendre les résultats plus compréhensibles pour les médecins, l’équipe a utilisé un outil d’explication qui classe les éléments d’information ayant le plus influencé les décisions de l’ordinateur. Le stade du cancer — une synthèse de la taille de la tumeur, de l’atteinte des ganglions lymphatiques et de la présence d’extensions — est apparu comme le facteur le plus déterminant. La taille de la tumeur, la profondeur d’invasion de la paroi colique, la présence de métastases, le type de traitement, le grade de la tumeur (degré d’anomalie cellulaire), l’atteinte des vaisseaux lymphatiques et sanguins, l’âge du patient et la perte de poids ont également joué des rôles importants dans la formation des prédictions de survie.
Des chiffres aux décisions cliniques
Ces résultats suggèrent qu’un modèle informatique soigneusement entraîné, alimenté par des informations cliniques de routine, peut aider les médecins à repérer les patients qui présentent un risque élevé mais discret après une chirurgie pour cancer du côlon. Dans la pratique quotidienne, un tel outil pourrait être intégré au dossier médical électronique et combiner instantanément les détails sur la tumeur et l’état général du patient en une estimation simple du risque. Ce chiffre ne remplacerait pas le jugement du médecin, mais il pourrait orienter des décisions telles que la fréquence des contrôles, l’intérêt d’un traitement supplémentaire au regard des effets secondaires, ou le besoin d’un second avis. Parce que les facteurs les plus importants identifiés par la machine correspondent à ce que les spécialistes du cancer considèrent déjà comme cruciaux, le système est plus facile à faire confiance et à expliquer aux patients.
Ce que cela signifie pour les patients et l’avenir
Pour les patients et leurs familles, le message principal est que les ordinateurs peuvent désormais utiliser des données médicales courantes pour soutenir une prise en charge plus personnalisée du cancer du côlon. Bien que l’étude ait été réalisée dans un seul centre en Iran et doive encore être testée dans d’autres hôpitaux et avec des données plus riches, comme des informations génétiques et d’imagerie, elle montre que l’apprentissage automatique peut mettre en évidence qui mérite une attention accrue et pourquoi. Avec le temps, à mesure que de nouvelles données seront ajoutées et que les modèles seront affinés, ces outils pourraient aider les médecins du monde entier à proposer des traitements non seulement fondés sur des preuves, mais aussi finement ajustés à la situation particulière de chaque patient et à son cancer.
Citation: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Mots-clés: cancer du côlon, apprentissage automatique, résultats de traitement, prévision du risque, données cliniques