Clear Sky Science · fr
Intégration QLSA-MOEAD pour l’ordonnancement précis des tâches dans des environnements informatiques hétérogènes
Pourquoi un meilleur ordonnancement des calculs compte
Des simulations sismiques aux télescopes spatiaux, la science moderne s’appuie sur des systèmes informatiques étendus qui mêlent plusieurs types de puces — processeurs classiques, processeurs graphiques et matériels reconfigurables. Décider quelle puce doit exécuter quelle unité de travail, et dans quel ordre, est étonnamment difficile et peut gaspiller du temps et de l’énergie si c’est mal fait. Cet article présente une nouvelle manière d’orchestrer ces charges complexes afin que les gros travaux se terminent plus vite, que le matériel soit mieux utilisé et, dans certains cas, que la consommation d’énergie diminue.
Des puces différentes, des tâches entrelacées
Les ordinateurs haute performance modernes sont « hétérogènes » : ils combinent CPU, GPU, FPGA et autres accélérateurs, chacun avec des atouts distincts. Les applications scientifiques et industrielles fragmentent souvent leur travail en nombreuses petites tâches reliées par des dépendances de données, formant naturellement un graphe orienté acyclique (DAG). Certaines tâches doivent se terminer avant que d’autres ne commencent, et l’exécution peut être plus ou moins rapide selon la puce choisie. Le défi consiste à affecter des centaines de tâches interdépendantes à un ensemble de processeurs de façon à minimiser le temps d’achèvement global, à maintenir les machines occupées plutôt qu’inactives et, pour certains flux, à garder la consommation d’énergie sous contrôle. Mathématiquement, il s’agit d’un problème NP‑difficile : une recherche exhaustive est impraticable pour des systèmes réalistes.
Pourquoi les méthodes anciennes montrent leurs limites
Les approches d’ordonnancement traditionnelles supposent souvent un environnement stable et se concentrent sur un seul objectif, par exemple minimiser le temps d’achèvement. Des heuristiques bien connues comme HEFT ordonnent les tâches par priorité, tandis que des métaheuristiques telles que l’algorithme de recuit simulé ou la recherche tabou explorent l’espace des ordonnancements possibles à la recherche d’améliorations. Ces méthodes peuvent bien fonctionner sur des systèmes plus petits ou plus simples, mais elles partent généralement d’ordonnancements initiaux aléatoires, ne s’adaptent pas lorsque les conditions changent et peinent à concilier plusieurs objectifs à la fois — temps, équilibre de charge et énergie. Des ordonnanceurs basés sur l’apprentissage automatique ajoutent de l’adaptativité, mais nécessitent souvent de grands jeux de données d’entraînement et manquent encore d’une méthode structurée pour produire un ensemble complet de solutions de compromis pour plusieurs objectifs.
Un système hybride qui planifie et affine
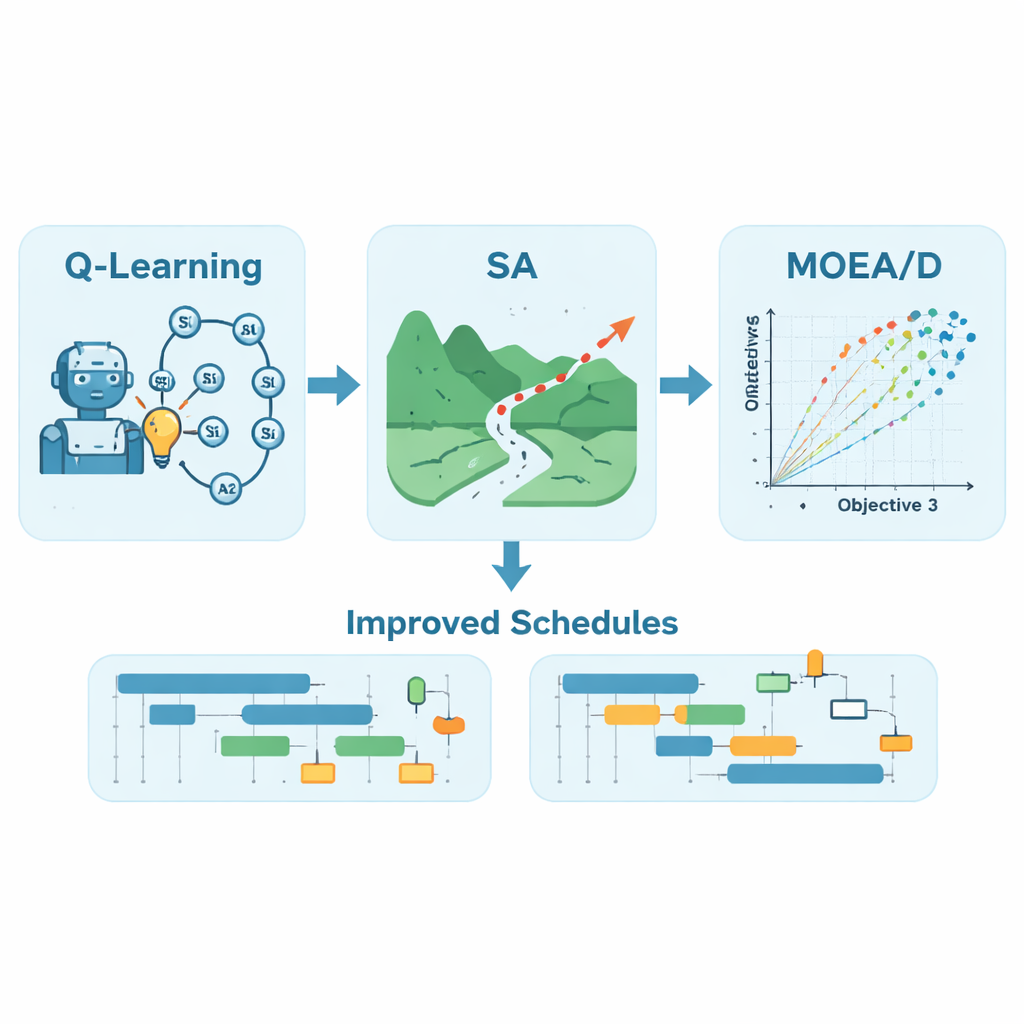
Les auteurs proposent QLSA‑MOEAD, un cadre hybride qui combine trois idées : le Q‑learning, le recuit simulé et une technique évolutionniste multi‑objectif appelée MOEA/D. D’abord, un agent de Q‑learning est entraîné à construire des ordonnancements de tâches par essais et erreurs. Il construit à plusieurs reprises des plannings, observe leur durée d’exécution et met à jour une table de « valeurs Q » qui capture les choix susceptibles de conduire à de meilleurs résultats. Plutôt que de s’appuyer sur des règles fixes, l’agent apprend progressivement des schémas efficaces pour mapper les tâches aux processeurs, y compris comment réagir quand de nouvelles tâches apparaissent pendant l’exécution. En s’appuyant sur cette politique apprise, le système génère un ordonnancement initial solide au lieu d’un ordre aléatoire, donnant ainsi une avance au processus d’optimisation.
Ajustement fin et équilibre des objectifs concurrents
Puis, le recuit simulé affine l’ordonnancement appris en échangeant des paires de tâches et en acceptant parfois des options moins bonnes pour sortir d’impasses locales, un peu comme secouer un puzzle pour atteindre une configuration meilleure. Enfin, MOEA/D considère le problème d’ordonnancement comme véritablement multi‑objectif. Plutôt que de réduire tous les objectifs à un seul score, il décompose le problème en de nombreux sous‑problèmes, chacun représentant un compromis différent entre la rapidité d’achèvement et l’équilibre de charge — et, pour le flux de travail de risque sismique CyberShake, aussi la réduction de la consommation d’énergie. Un processus évolutionniste explore ces compromis en parallèle, échangeant des informations entre sous‑problèmes voisins pour produire un front de Pareto diversifié d’ordonnancements où améliorer un objectif détériorerait un autre.
Mise à l’épreuve de la méthode
Pour évaluer les performances, QLSA‑MOEAD a été testé sur 20 cas de flux de travail, incluant des charges synthétiques de transformée de Fourier rapide et moléculaires, un large flux d’assemblage d’images astronomiques (Montage) et la simulation sismique réelle CyberShake. Sur 16 cas synthétiques, la nouvelle méthode a fourni la meilleure qualité de solution dans 14 d’entre eux, réduisant les temps d’achèvement et améliorant l’utilisation du matériel par rapport à plusieurs références avancées. Pour CyberShake, où l’énergie était aussi optimisée, elle a obtenu des améliorations de deux à quatre fois sur une mesure de qualité multi‑objectif standard par rapport à l’état de l’art précédent, tout en conservant une bonne diversité de solutions de compromis. Dans des tests dynamiques où de nouvelles tâches arrivent en continu, l’ordonnanceur appris a pu réagir en moins de deux millisecondes, ajustant les plans bien plus vite que le recalcul complet, bien que parfois au prix d’une perte d’optimalité lorsque les latences de communication étaient extrêmes.
Quelles conséquences pour l’informatique de tous les jours
Pour un non‑spécialiste, le message est que des ordonnanceurs plus intelligents, basés sur l’apprentissage, peuvent rendre les grands ordinateurs à puces mixtes à la fois plus rapides et plus écologiques sans réglages humains constants. En combinant un planificateur fondé sur l’expérience (Q‑learning), une recherche locale soignée (recuit simulé) et un explorateur de compromis (MOEA/D), le cadre proposé trouve de manière systématique des ordonnancements qui terminent les gros travaux plus tôt, maintiennent mieux utilisés des matériels coûteux et, pour certaines applications, réduisent la consommation d’énergie. Il existe encore des limites — coût d’entraînement et baisses de performance dans les conditions les plus extrêmes — mais l’étude indique une voie pratique vers une orchestration plus autonome et efficace des flux scientifiques et industriels complexes.
Citation: Saad, A., Abd el-Raouf, O., Hadhoud, M. et al. QLSA-MOEAD integration for precision task scheduling in heterogeneous computing environments. Sci Rep 16, 7194 (2026). https://doi.org/10.1038/s41598-026-36916-1
Mots-clés: ordonnancement de tâches, informatique hétérogène, apprentissage par renforcement, optimisation multi‑objectif, flux de travail économe en énergie