Clear Sky Science · fr
Combler l’écart de performance : optimisation systématique des LLM locaux pour l’extraction d’IPM en japonais
Pourquoi cela compte pour la confidentialité des patients
Les hôpitaux possèdent d’immenses collections de notes médicales susceptibles d’améliorer les soins et la recherche, mais ces dossiers contiennent des informations sensibles comme des noms, adresses et dates. Les puissants systèmes d’IA basés sur le cloud excellent pour masquer ces informations, toutefois de nombreux établissements ne sont pas autorisés à envoyer des données brutes de patients vers des serveurs externes. Cette étude montre qu’avec un réglage soigné, de plus petits modèles d’IA exécutés entièrement sur place peuvent se rapprocher étonnamment des performances des meilleurs systèmes cloud — offrant une façon d’utiliser l’IA tout en maintenant les données des patients en sécurité sur site.
Le dilemme confidentialité versus progrès
Les modèles de langage modernes repèrent et suppriment de manière fiable les informations de santé protégées (IPM) dans les textes médicaux, atteignant souvent plus de 90 % de précision. Toutefois, l’envoi de notes de patients non éditées vers des services cloud soulève des enjeux juridiques et éthiques sous des réglementations comme la HIPAA, le RGPD et la loi japonaise APPI. Beaucoup d’institutions exigent une « souveraineté des données » totale, c’est‑à‑dire que l’information ne quitte jamais leurs propres ordinateurs. Jusqu’à présent, les modèles locaux capables de tourner sur le matériel interne manquaient généralement davantage d’identifiants, forçant les hôpitaux à choisir : analyses puissantes dans le cloud ou protection plus stricte avec des outils moins performants. Les auteurs ont cherché à savoir si cet écart pouvait être suffisamment réduit pour un usage clinique réel.
Un plan en étapes pour une IA locale plus intelligente
L’équipe a conçu un cadre d’optimisation en cinq étapes pour améliorer progressivement les performances des modèles linguistiques locaux sur la suppression d’IPM dans des rapports de radiologie en japonais. Ils ont commencé avec 14 modèles différents de tailles variées, tous exécutés sur un ordinateur isolé et sans accès Internet, destiné à reproduire la sécurité hospitalière. En utilisant 160 rapports synthétiques soigneusement élaborés — réalistes mais entièrement fictifs — ils ont mesuré dans quelle mesure chaque modèle détectait et séparait huit types d’identifiants, des noms et numéros d’identification aux dates et services. Après un test de référence initial, ils ont créé des invites générales plus utiles, puis des instructions adaptées aux particularités de chaque modèle, ajouté une boucle automatisée de « vérification et correction » par le modèle lui‑même, et enfin évalué les meilleurs candidats sur un ensemble réservé de rapports. 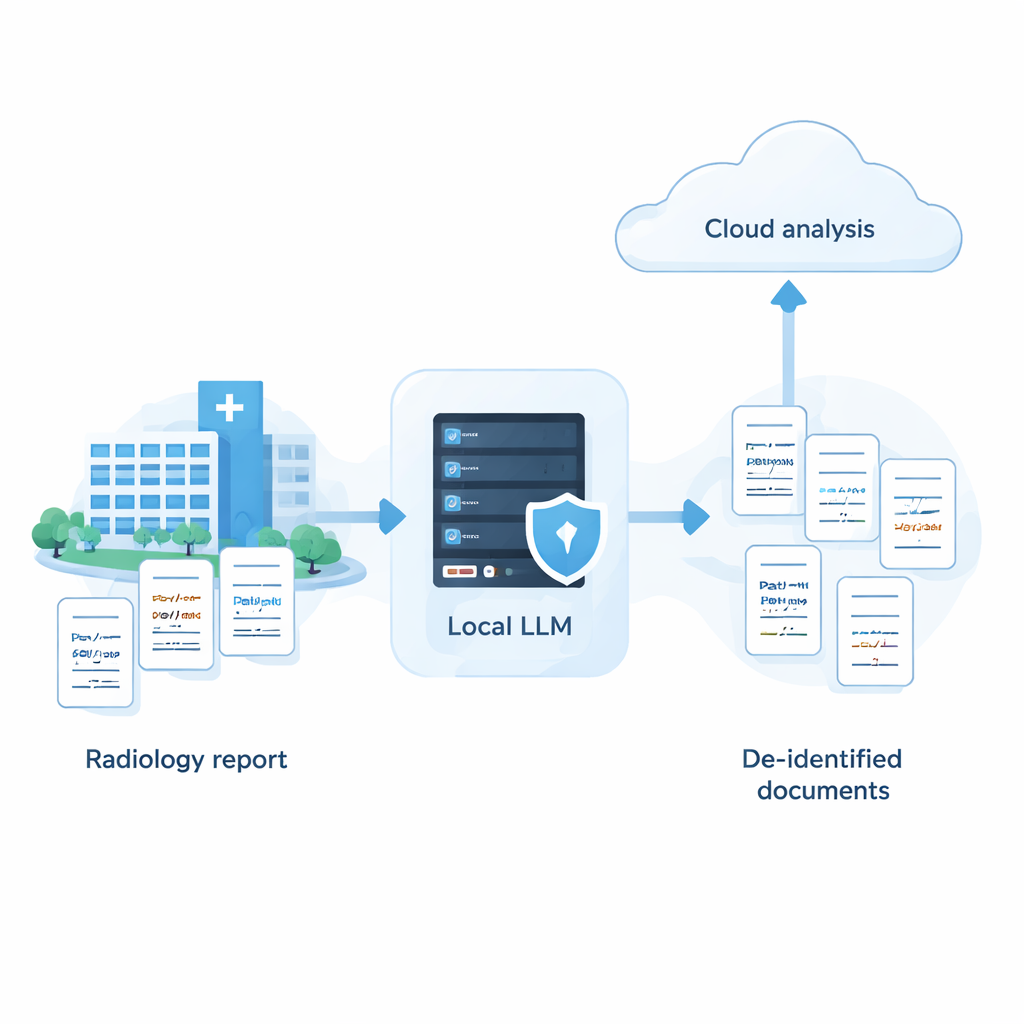
Se rapprocher des performances cloud
Grâce à ce processus par étapes, les chercheurs ont découvert que la taille brute du modèle n’était pas l’élément déterminant ; certains très grands systèmes se sont avérés médiocres. En revanche, les modèles les plus prometteurs étaient ceux qui répondaient bien à une conception d’instructions soignée et à l’analyse d’erreurs. Un système de taille moyenne, Mistral‑Small‑3.2, est devenu le gagnant clair après des invites personnalisées et une étape d’auto‑amélioration où le modèle a réexaminé et corrigé sélectivement sa propre sortie. Sur les 60 cas de test finaux, cette configuration locale optimisée a obtenu 91,54 sur 100 — soit environ 97,8 % des 93,56 points du modèle cloud leader — tout en respectant parfaitement les règles de formatage. En termes pratiques, le déficit restant a été jugé cliniquement mineur. Le principal coût était la vitesse : le traitement local prenait environ 25 secondes par rapport typique, contre moins de 2 secondes dans le cloud, mais cela a été considéré comme acceptable pour des traitements par lots routiniers et non urgents. 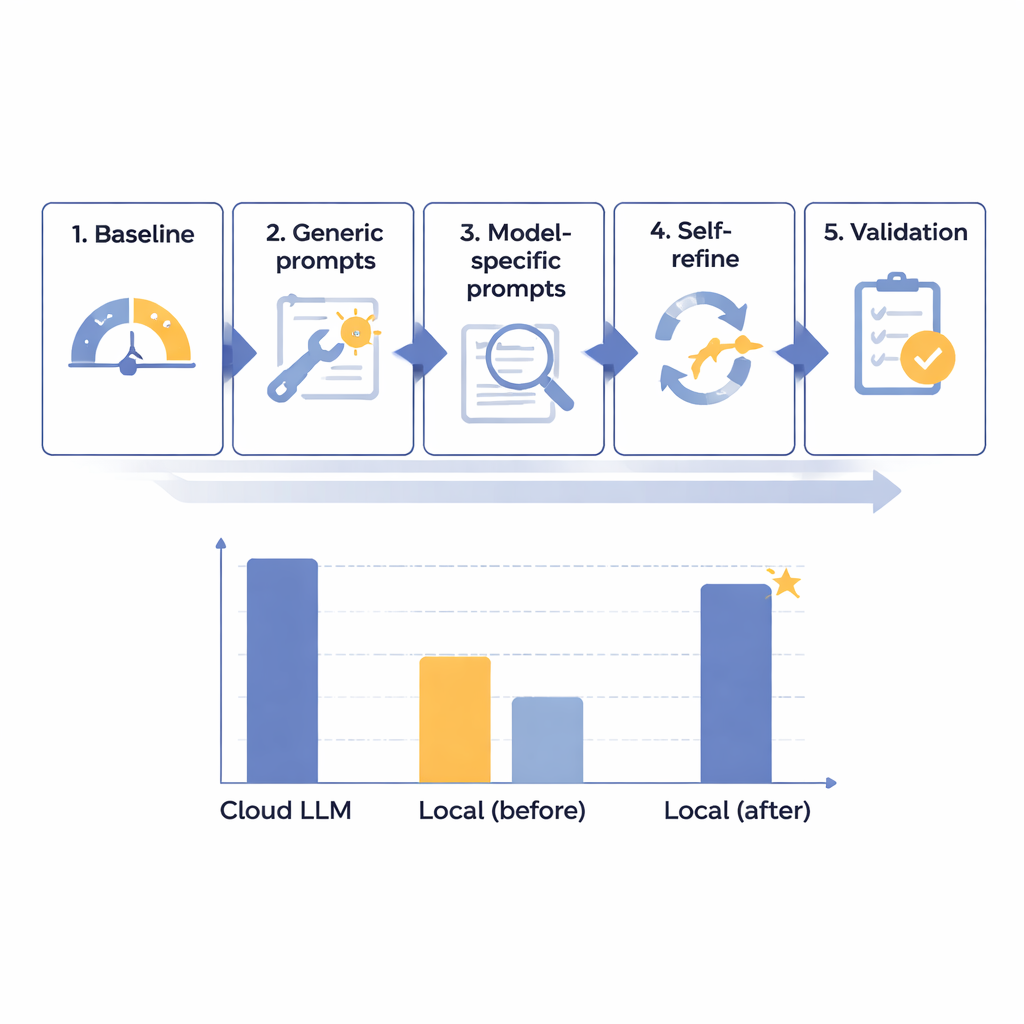
Un seuil surprenant pour l’auto‑correction
Une des découvertes les plus intrigantes fut une sorte de point de bascule autour de 87–88 points sur l’échelle de 100 des auteurs. Les modèles qui se situaient en dessous de ce niveau au départ — comme Mistral‑Small‑3.2 — ont beaucoup profité de la boucle d’auto‑amélioration, gagnant près de sept points en corrigeant une petite fraction de leurs propres erreurs. Les modèles qui commençaient déjà au‑dessus de ce seuil ont montré presque aucune amélioration, et ont parfois gaspillé des efforts à « corriger » des réponses correctes. Cela suggère que les outils d’optimisation avancés devraient être réservés aux modèles bons mais pas encore excellents, permettant aux hôpitaux de concentrer la puissance de calcul et le temps du personnel là où le rendement est maximal. Les auteurs précisent que ce seuil repose sur seulement deux modèles et nécessite confirmation, mais il offre une première règle empirique pour la planification de déploiement.
Ce que cela signifie pour les hôpitaux et les patients
L’étude soutient que les hôpitaux n’ont pas à choisir entre forte confidentialité et forte IA. Avec une approche systématique — tester de nombreux modèles, ajuster les invites selon leurs forces et faiblesses, et ajouter une étape intelligente d’auto‑révision — il est possible pour un système entièrement local de se rapprocher de la précision des meilleurs services cloud pour la suppression d’informations sensibles dans le texte médical. En pratique, cela ouvre la voie à une stratégie hybride : les IPM sont supprimées en toute sécurité sur des machines appartenant à l’hôpital, et seuls des rapports anonymisés, dépourvus de noms et autres identifiants, sont envoyés dans le cloud pour des analyses plus avancées. Bien que le travail présenté repose sur des rapports de radiologie japonais synthétiques et doive être testé sur des données réelles et d’autres langues, il propose une feuille de route opérationnelle pour les institutions souhaitant exploiter l’IA tout en maintenant la confiance et la confidentialité des patients au centre de leurs préoccupations.
Citation: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Mots-clés: dé-identification médicale, confidentialité des patients, modèles linguistiques locaux, IA en santé, rapports de radiologie