Clear Sky Science · fr
Réseau bayésien amélioré avec attention sur graphe et algorithme de connaissances a priori pour l’analyse des causes profondes de pannes de moteurs d’avion
Pourquoi les problèmes cachés du moteur comptent
Chaque vol commercial repose sur des turboréacteurs qui tournent des milliers d’heures sous des températures et des pressions extrêmes. Quand quelque chose tourne mal, les compagnies aériennes peuvent perdre des millions à cause de retards, d’annulations et de réparations imprévues. Les causes profondes des pannes graves commencent souvent par de minuscules fissures ou des dommages chimiques à l’intérieur des pièces métalliques — des phénomènes que les capteurs ne détectent pas directement. Cet article présente une nouvelle méthode pour retracer les pannes jusqu’à ces origines cachées, même lorsque les données sont rares et biaisées vers des incidents mineurs et fréquents.
Le défi d’identifier le véritable coupable
Les moteurs modernes sont si fiables que les défaillances graves sont rares. C’est positif pour la sécurité, mais cela crée un problème de données : les bases de maintenance sont pleines d’enregistrements d’incidents fréquents et peu impactants, tandis que les causes profondes réellement dangereuses n’apparaissent que quelques fois. De plus, les capteurs suivent généralement des symptômes de haut niveau — perte de poussée ou vibrations anormales — et non les dommages microscopiques comme l’oxydation au niveau des joints de grains ou les très petites fissures. Les méthodes statistiques traditionnelles et les réseaux bayésiens classiques, qui apprennent principalement les liens de cause à effet à partir de cooccurrences, ont tendance à se concentrer sur ces événements communs mais moins graves. Ils manquent ainsi souvent les causes rares et profondément ancrées qui provoquent véritablement l’arrêt d’un moteur.
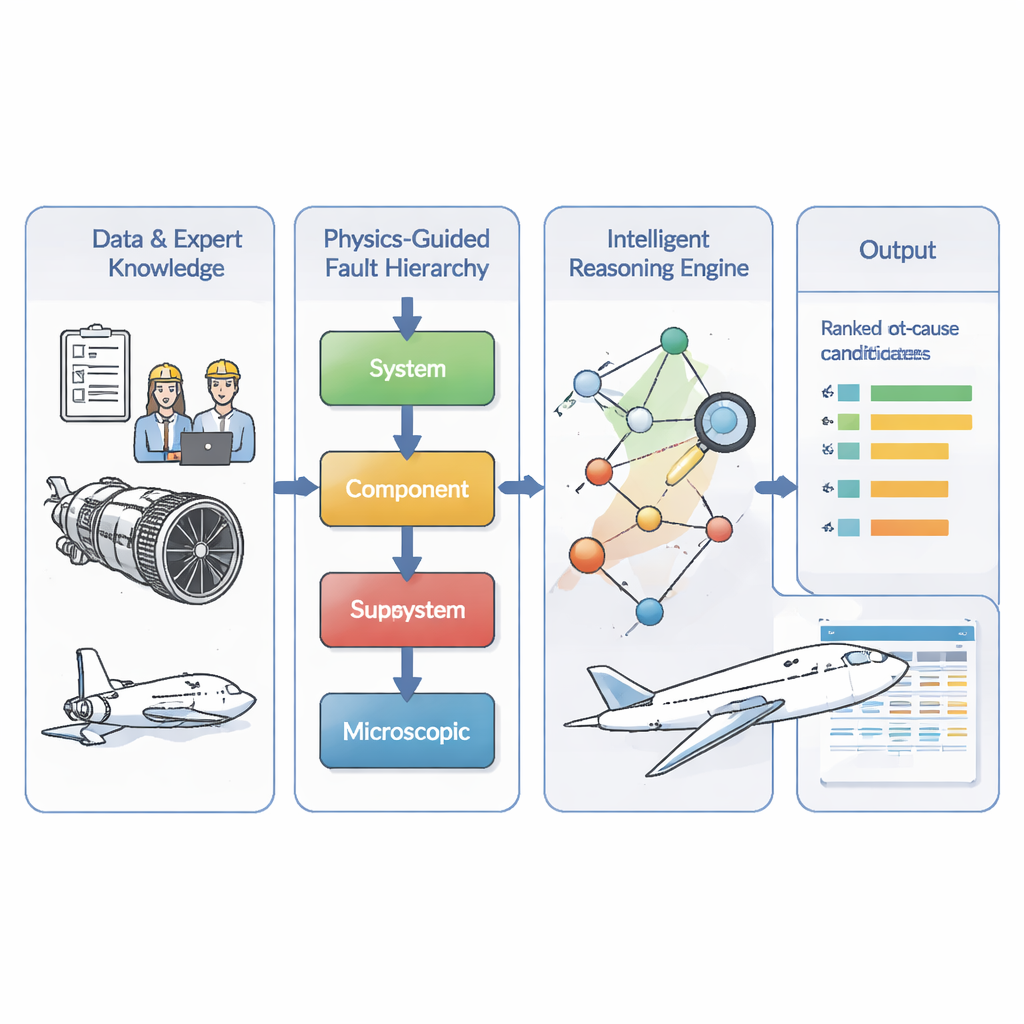
Une carte en couches de la propagation des pannes
Les auteurs s’attaquent à ce problème en codant d’abord la compréhension des ingénieurs sur le déroulement des pannes. Ils divisent les défaillances en quatre niveaux : dommages matériels microscopiques, défaillance d’une pièce spécifique, dysfonctionnement d’un sous‑système comme le carburant ou la lubrification, et enfin conséquences au niveau système comme un arrêt en vol. Leur modèle impose une règle simple : les causes doivent aller des niveaux profonds vers les niveaux supérieurs — du dommage micro vers la défaillance de pièce, puis vers le problème de sous‑système, et enfin vers les symptômes globaux du moteur. Cela crée une « carte des pannes » dirigée qui reflète la réalité physique et exclut les raccourcis impossibles ou les boucles de rétroaction que les données limitées pourraient suggérer par hasard. À partir des dossiers de maintenance de 634 événements moteurs réels, l’équipe utilise une procédure de recherche standard pour remplir les liens probables au sein de cette structure en couches, puis fait examiner et corriger le réseau résultant par des experts.
Apprendre au modèle ce que les données ne montrent pas
Parce que les pannes les plus dangereuses sont rares, l’équipe ajoute deux types d’intelligences complémentaires. D’abord, elle extrait de l’ensemble des données des règles d’association — des motifs du type « quand ce palier casse, une basse pression d’huile est souvent observée » — en utilisant un algorithme classique de type panier d’achats. Ces règles sont traitées comme des connaissances a priori sur la probabilité qu’un problème en entraîne un autre. Un mécanisme d’attention léger apprend ensuite à quel point il faut faire confiance à ces a priori à chaque niveau de la hiérarchie. Par exemple, lorsque le modèle estime les probabilités pour des causes microscopiques avec très peu d’exemples, il s’appuie automatiquement davantage sur les motifs globaux et moins sur des statistiques locales fragiles. Ce mélange adaptatif aide à corriger la sous‑estimation des pannes profondes qui résulterait d’un comptage brut des occurrences.
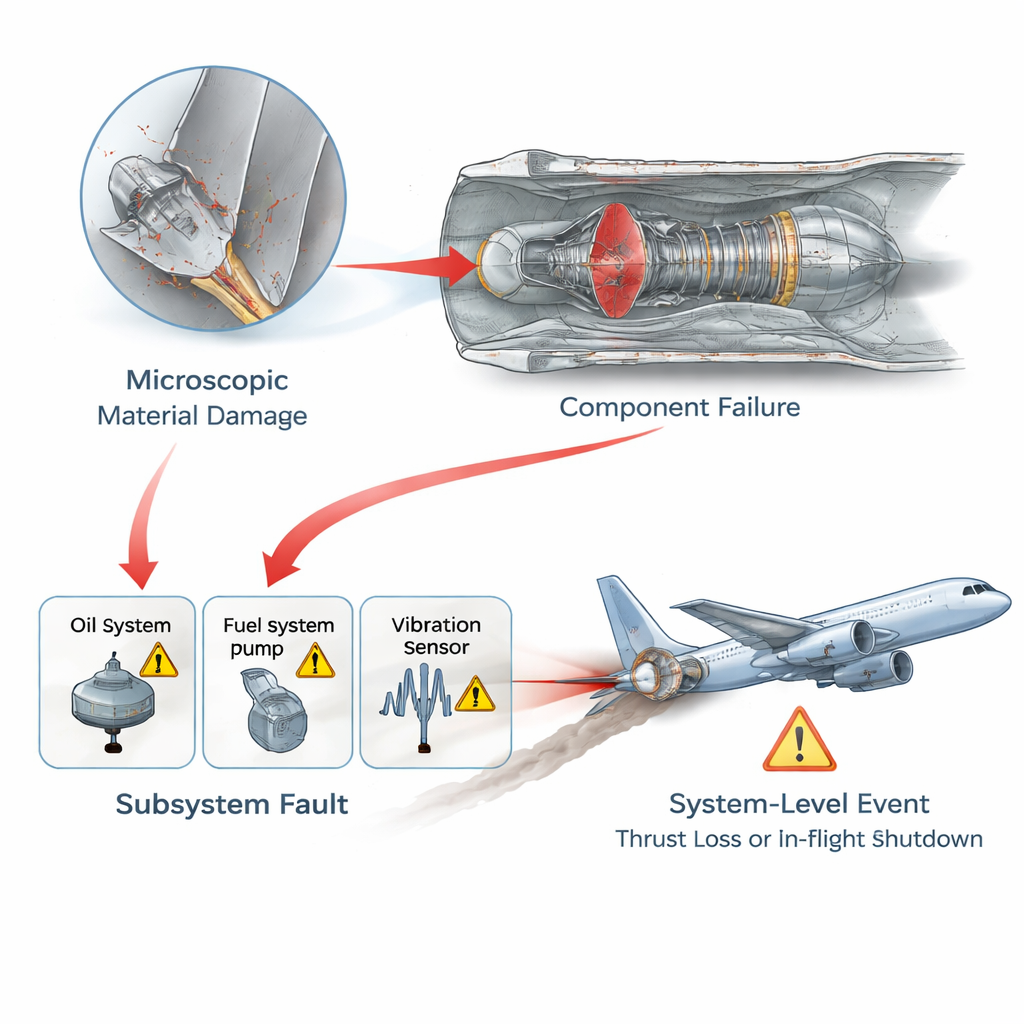
Permettre au réseau de mettre en avant les pannes réellement critiques
Ensuite, les auteurs ajoutent un module d’attention sur graphe qui analyse la structure même du réseau de pannes. Chaque nœud — représentant une panne ou un symptôme spécifique — apprend une empreinte numérique compacte basée sur ses voisins et sur la façon dont l’information circule dans le graphe. À partir de cela, le modèle attribue à chaque nœud un « score de criticité » qui reflète son rôle central dans les chaînes de pannes graves, pas seulement sa fréquence d’apparition. Il produit également une estimation distincte, fondée sur la structure, de la probabilité qu’un nœud cause un autre. La probabilité finale pour tout lien de panne est alors un mélange pondéré de l’estimation issue des données et de cet a priori neural, où le poids dépend de la criticité du nœud. En termes simples, les alertes fréquentes mais peu importantes sont discrètement relativisées, tandis que les causes profondes rares mais structurellement cruciales reçoivent une attention renforcée.
Mise à l’épreuve de la méthode
Les chercheurs comparent leur modèle complet — appelé GAT‑BN — à plusieurs alternatives, y compris des réseaux bayésiens standard, un classifieur forêt aléatoire, un réseau de convolution sur graphe, et une approche d’ingénierie traditionnelle basée sur des arbres de défaillance et des analyses des modes de défaillance. En utilisant deux mesures intuitives — la fréquence à laquelle la véritable cause racine apparaît parmi la première ou les trois premières prédictions, et la proximité des probabilités prédites avec la réalité — la nouvelle méthode l’emporte sur tous les fronts. Elle est particulièrement performante lorsque les données sont rares, que certains enregistrements sont incomplets, et lorsque la cause racine est une panne microscopique peu fréquente. Bien que GAT‑BN soit plus coûteux en calcul que des modèles plus simples, les auteurs soutiennent que ses temps d’entraînement et d’inférence restent pratiques pour une utilisation sur des postes de travail d’ingénierie modernes.
Ce que cela signifie pour des vols plus sûrs
Pour les non‑spécialistes, le message principal est que ce travail propose une façon plus intelligente de trier des données de maintenance désordonnées et des connaissances expertes complexes pour identifier le point de départ réel des pannes moteurs. En combinant une échelle de pannes fondée sur la physique, des motifs extraits des archives historiques, et un réseau qui apprend quelles pannes sont réellement importantes, le modèle GAT‑BN peut mieux signaler les conditions rares mais dangereuses avant qu’elles n’escaladent. Bien que l’étude se concentre sur un jeu de moteurs d’avion et adopte une vision statique des pannes, l’approche ouvre une voie plus générale : les futurs systèmes de diagnostic pourraient dépendre moins de jeux de données massifs et parfaitement équilibrés et davantage de connaissances structurées mêlées à un apprentissage automatique ciblé.
Citation: Yuan, L., Han, G. & Dong, P. Improved bayesian network with graph attention and prior algorithm for aircraft engine fault root cause analysis. Sci Rep 16, 5924 (2026). https://doi.org/10.1038/s41598-026-36883-7
Mots-clés: pannes de moteurs d’avion, analyse des causes profondes, réseaux bayésiens, attention sur graphe, maintenance prédictive