Clear Sky Science · fr
Estimation de variance par apprentissage automatique sous échantillonnage en deux phases utilisant des données des secteurs de la santé et de l’éducation
Pourquoi des moyennes plus intelligentes comptent pour les décisions réelles
Chaque fois que des médecins étudient la tension artérielle ou que des enseignants suivent les notes des élèves, ils ne s’intéressent pas seulement à la moyenne ; ils doivent savoir dans quelle mesure les individus s’écartent de cette moyenne. Cette dispersion, appelée variabilité, oriente le nombre de patients à recruter pour un essai, la taille d’un programme de tutorat, ou le degré de confiance que l’on peut accorder aux décisions politiques. L’article résumé ici propose une nouvelle méthode statistiquement fondée pour mesurer cette variabilité plus précisément en mariant des idées classiques d’échantillonnage avec l’apprentissage automatique moderne, testée sur des données de santé et d’éducation.
Mesurer la dispersion quand l’information est incomplète
Dans un monde idéal, les chercheurs sauraient des détails supplémentaires sur chaque personne d’une population avant de lancer une enquête : âges, habitudes d’étude, antécédents médicaux, etc. En réalité, ces informations sont souvent partielles ou coûteuses à recueillir. Les auteurs travaillent dans le cadre d’un plan dit d’échantillonnage en deux phases pour gérer cette situation. Lors de la première phase, ils prélèvent un grand échantillon relativement bon marché et enregistrent des informations de fond simples, comme l’âge ou l’accès à Internet. Lors de la deuxième phase, ils tirent un sous-échantillon plus petit et mesurent un résultat plus coûteux ou long à obtenir, comme la pression artérielle systolique ou les notes finales. Le défi consiste à utiliser ces deux niveaux d’information pour estimer à quel point le résultat varie réellement dans l’ensemble de la population.
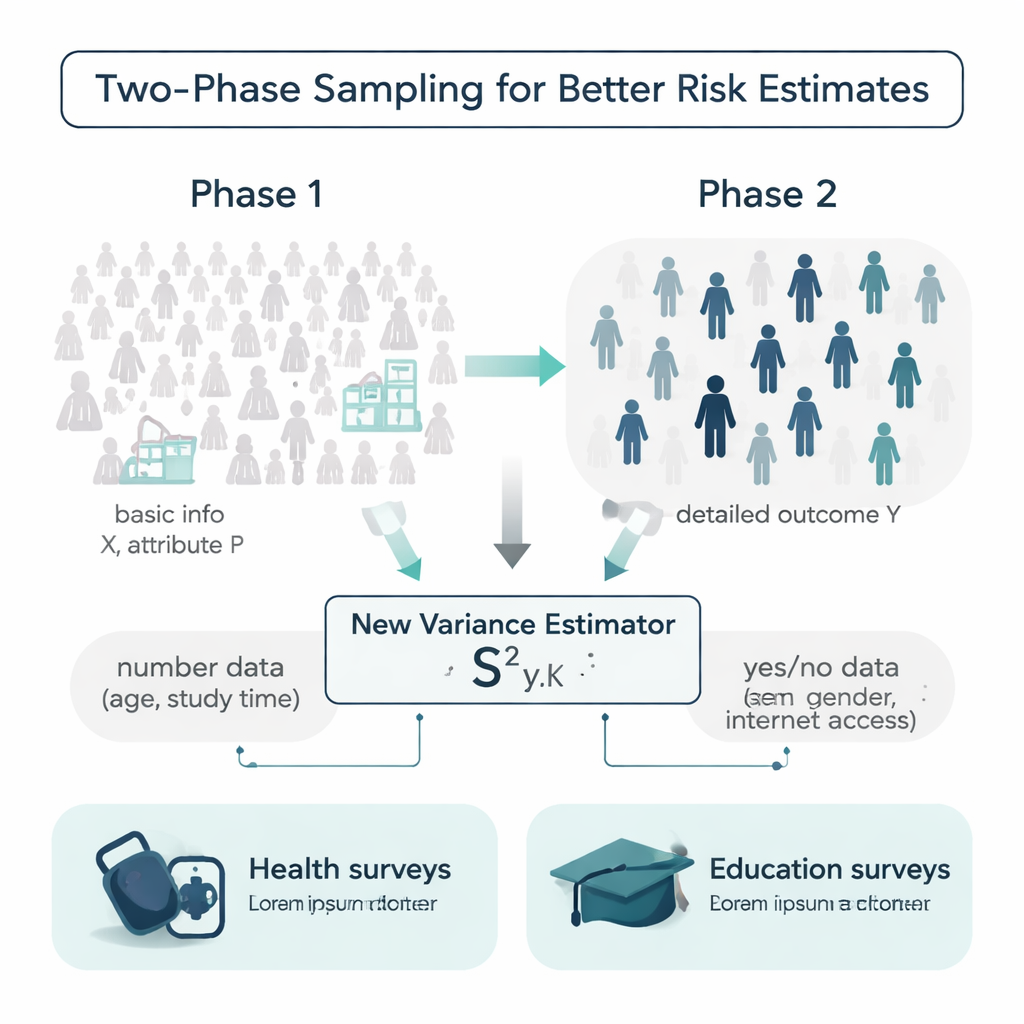
Un nouvel estimateur qui utilise à la fois des nombres et des caractéristiques oui/non
La plupart des outils traditionnels pour mesurer la variabilité s’appuient uniquement sur le résultat lui-même ou sur une seule variable auxiliaire, et supposent souvent que les données suivent des formes en cloche commodes. Les auteurs proposent un nouvel estimateur de la variance qui exploite simultanément deux types d’informations supplémentaires : un auxiliaire numérique (par exemple l’âge ou le temps d’étude hebdomadaire) et un attribut binaire (comme le genre ou l’accès à Internet). Ils montrent mathématiquement comment cet estimateur « mixté » se comporte, en dérivant des formules pour son biais et son erreur quadratique moyenne — deux mesures clés de l’exactitude. Sous des conditions raisonnables, l’estimateur est pratiquement non biaisé et son erreur attendue est inférieure à celle des formules concurrentes largement utilisées, ce qui signifie qu’il devrait fournir des estimations d’incertitude plus précises avec la même quantité de données.
Tester les performances à travers de nombreux mondes de données
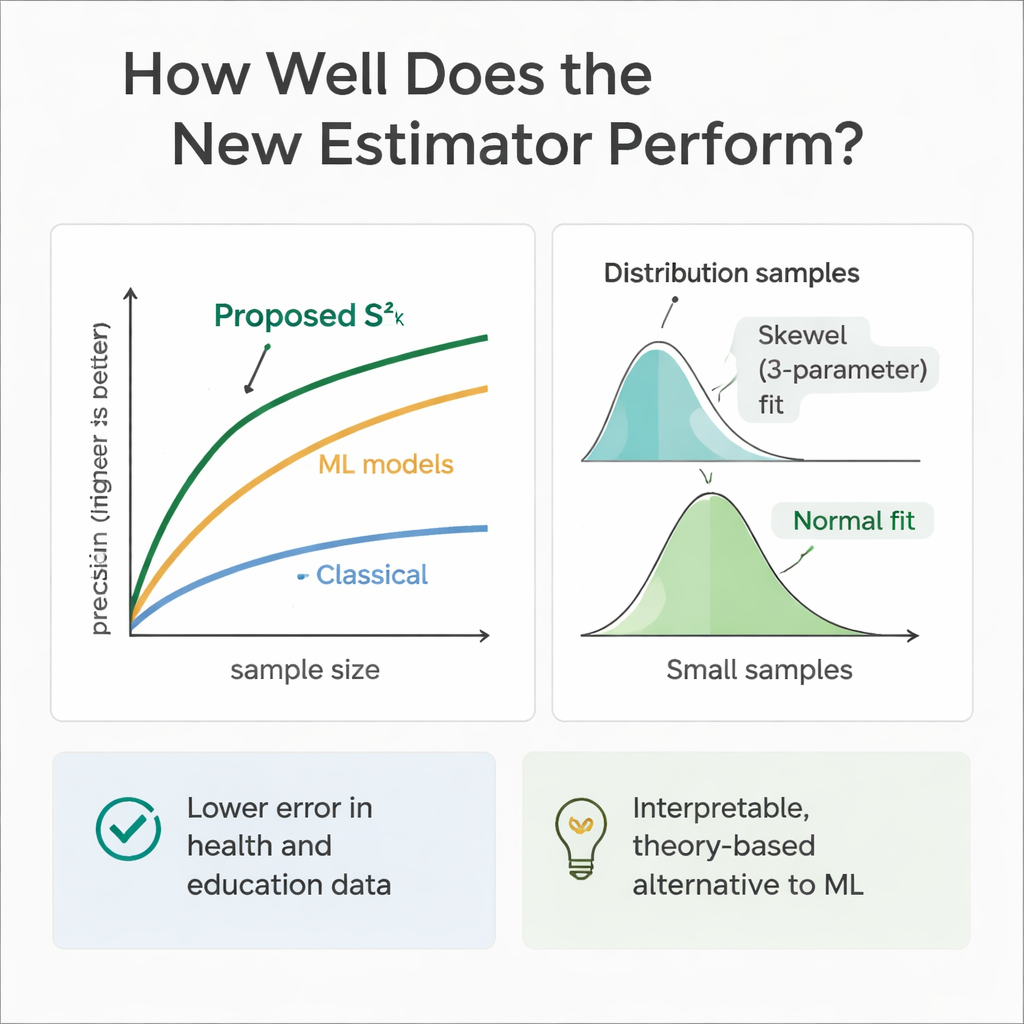
Pour vérifier si la théorie correspond à la pratique, l’équipe a réalisé de vastes expériences informatiques. Ils ont simulé des populations où les variables auxiliaires et le résultat suivaient une gamme de lois, allant de symétriques (Normale et Uniforme) à asymétriques (Gamma et Weibull). Grâce à des tirages répétés, ils ont comparé l’erreur du nouvel estimateur avec celle de plusieurs méthodes établies pour différentes tailles d’échantillons. Dans presque tous les cas, et surtout lorsque la taille des échantillons augmentait, la nouvelle approche a montré une efficacité relative bien supérieure — réduisant souvent l’erreur de 30 à 70 % par rapport à l’estimateur de variance classique. Les auteurs ont également étudié la distribution d’échantillonnage de l’estimateur lui‑même, constatant qu’une courbe de Weibull à trois paramètres la décrit le mieux pour des échantillons modestes, tandis qu’elle tend vers une forme normale lorsque la taille des échantillons devient grande.
Données réelles de cliniques et de salles de classe
La méthode a ensuite été appliquée à deux études de cas réelles. Dans un jeu de données en santé, le résultat était la pression artérielle systolique, avec l’âge comme auxiliaire numérique et le genre comme attribut binaire. Dans un jeu de données en éducation, le résultat était la note finale du cours, l’auxiliaire était le temps d’étude hebdomadaire et l’attribut était l’accès à Internet par l’étudiant. Dans les deux cas, l’estimateur proposé a produit la plus faible erreur quadratique moyenne parmi tous les concurrents statistiques testés, resserrant sensiblement l’estimation de la variabilité autour de la tension artérielle moyenne et autour des performances moyennes des étudiants. Cette amélioration se traduit par des intervalles de confiance plus précis et des comparaisons entre groupes ou interventions plus fiables.
Comment il se compare à l’apprentissage automatique
Parce que les modèles d’apprentissage automatique excellent en prédiction, les auteurs ont également entraîné des arbres de régression, des forêts aléatoires et des machines à vecteurs de support sur les mêmes scénarios simulés de santé et d’éducation. Ces modèles, alimentés par les mêmes variables auxiliaires, ont souvent égalé ou légèrement surpassé le nouvel estimateur en termes de précision prédictive pure. Cependant, ils se comportent comme des boîtes noires : il est difficile de retracer précisément comment ils combinent l’information, et ils manquent des formules claires nécessaires à l’inférence d’enquêtes traditionnelle. L’estimateur proposé, en revanche, est transparent et ancré dans la théorie de l’échantillonnage, ce qui le rend plus facile à justifier dans des contextes réglementaires, cliniques ou politiques où l’explicabilité compte autant que la performance brute.
Ce que cela signifie pour les enquêtes en pratique
En termes simples, ce travail montre que les chercheurs peuvent obtenir des mesures de dispersion plus fiables sans augmenter drastiquement la taille des échantillons, simplement en utilisant de manière disciplinée des informations supplémentaires, même minimales, qu’ils collectent déjà. En combinant un facteur numérique (comme l’âge ou le temps d’étude) avec un attribut binaire (comme le genre ou l’accès à Internet) dans un plan d’échantillonnage en deux étapes, le nouvel estimateur fournit des estimations de variance plus nettes et plus stables que les méthodes traditionnelles. Alors que les outils avancés d’apprentissage automatique demeurent des références utiles, cette approche offre un compromis pratique et interprétable, aidant les analystes en santé et en éducation à tirer des conclusions plus solides à partir de données limitées.
Citation: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Mots-clés: échantillonnage d’enquête, estimation de la variance, apprentissage automatique, données de santé, recherche en éducation