Clear Sky Science · fr
Généralisabilité et transférabilité des modèles d’apprentissage automatique utilisant des données de réflectance hyperspectrales pour les caractères du maïs
Pourquoi scanner les feuilles des plantes compte pour notre alimentation future
Nourrir une population en croissance dans un climat changeant exige des cultures capables de prospérer sous la chaleur, la sécheresse et d’autres stress. Les sélectionneurs cherchent à savoir quelles plantes possèdent la bonne combinaison de structure foliaire, de chimie et de performance photosynthétique — mais mesurer directement ces caractères sur des milliers de plantes est lent et destructif. Cette étude examine si le simple balayage des feuilles de maïs avec un capteur hyperspectral, associé à l’apprentissage automatique, peut remplacer de manière fiable des mesures de laboratoire fastidieuses, même lorsque les plantes sont cultivées lors d’années différentes et dans des conditions de champ changeantes.
Les empreintes lumineuses des feuilles de maïs
Chaque feuille réfléchit la lumière selon un motif qui dépend de ses pigments, de sa teneur en eau et de sa structure interne. Les capteurs hyperspectraux capturent ce motif sur des centaines de longueurs d’onde, du visible au proche infrarouge court, créant une « empreinte » détaillée de chaque feuille. Les chercheurs ont collecté ces empreintes sur une population diversifiée de maïs cultivée durant trois saisons de terrain consécutives, ainsi que 25 caractères décrivant l’anatomie foliaire (comme la surface foliaire spécifique et l’équilibre carbone–azote), les échanges gazeux (comment les feuilles absorbent le CO2 et perdent de l’eau) et la fluorescence de la chlorophylle (une fenêtre sur l’efficacité et la régulation de la photosynthèse). Cet ensemble de données riche leur a permis de tester dans quelle mesure différents modèles statistiques pouvaient convertir des spectres lumineux en estimations de caractères.
Apprendre aux machines à lire les feuilles
L’équipe s’est concentrée sur deux approches d’apprentissage automatique largement utilisées et relativement simples : la régression par moindres carrés partiels (PLSR) et la régression par vecteurs de support linéaire (SVR linéaire). Les deux méthodes compressent les spectres très détaillés en un plus petit nombre de caractéristiques informatives avant de les relier aux caractères mesurés. Les scientifiques ont comparé avec soin les façons d’ajuster les modèles, en particulier le nombre de composantes à utiliser pour PLSR, et comment éviter le surapprentissage. Ils ont également examiné s’il était préférable d’alimenter les modèles avec des mesures foliaires individuelles, des moyennes par parcelle, ou des moyennes sur toutes les plantes d’un même génotype. Un cadre rigoureux de validation croisée emboîtée — essentiellement des cycles répétitifs d’entraînement et de test — a été utilisé pour vérifier les performances et l’incertitude.
Quels caractères sont les plus faciles à prédire
Certains caractères foliaires se sont révélés beaucoup plus « lisibles » à partir des spectres lumineux que d’autres. Les caractères structuraux et biochimiques, tels que la surface foliaire spécifique et la teneur en azote, ont été prédits avec une grande précision, notamment lorsque les données étaient moyennées au niveau du génotype pour réduire le bruit de mesure. Certaines capacités photosynthétiques et quelques indicateurs de fluorescence de la chlorophylle liés au comportement du photosystème II à la lumière ont montré une prévisibilité modérée. En revanche, les caractères liés à des processus rapides et de courte durée — comme la vitesse à laquelle les feuilles activent ou relâchent la dissipation d’énergie protectrice — ont été mal captés. Pour ces derniers, le signal spectral est soit faible soit facilement noyé par la variation environnementale au moment de la mesure.
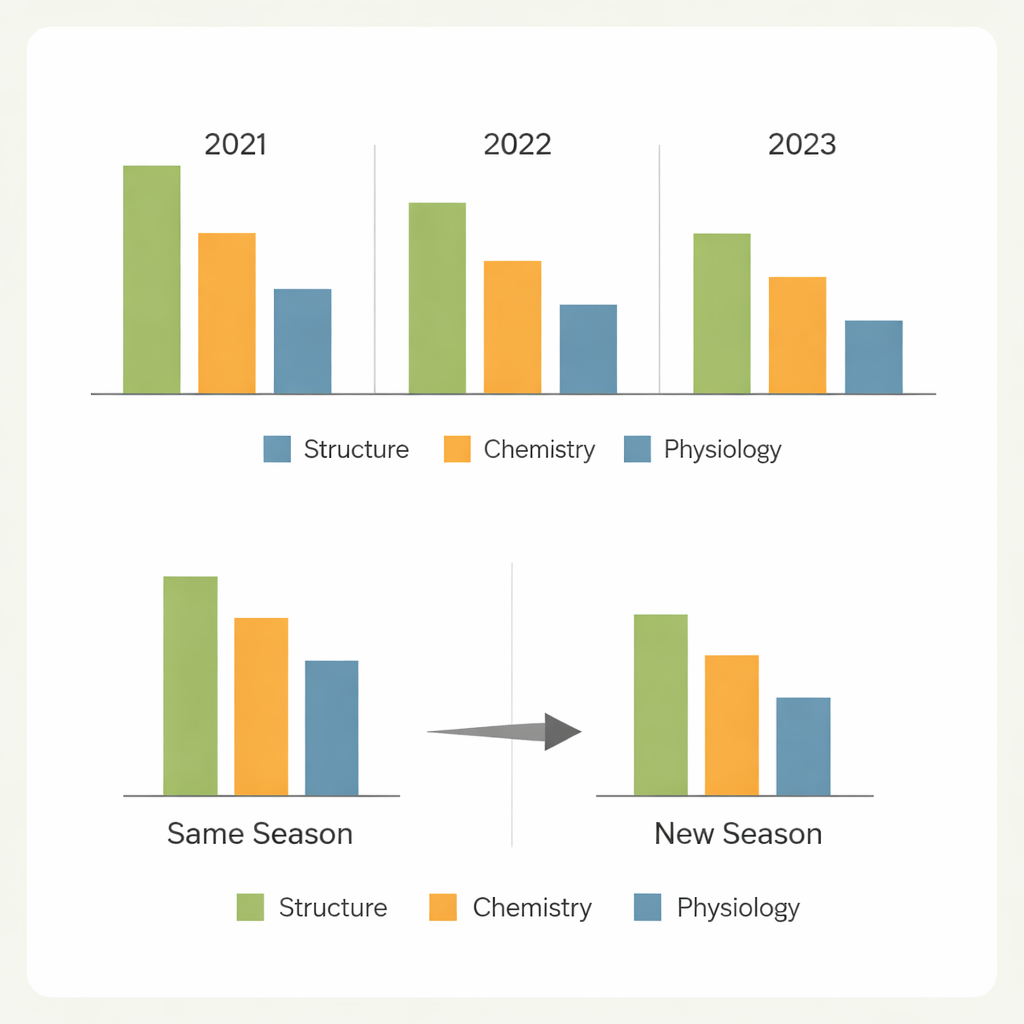
D’une saison à l’autre
Une question clé pour la sélection en conditions réelles est de savoir si un modèle entraîné dans un jeu de conditions peut être fiable ailleurs. Lorsque les modèles ont prédit des plantes aléatoires au sein de la même saison, les performances étaient généralement bonnes pour les caractères les plus faciles. Prédire des génotypes entièrement nouveaux cultivés la même saison entraînait seulement de modestes baisses pour les caractères structuraux et liés à l’azote, mais des déclins beaucoup plus marqués pour les caractères d’échange gazeux. Le test le plus sévère — prédire de nouveaux génotypes une année différente — a révélé de grosses pertes d’exactitude, en particulier pour les caractères fortement façonnés par l’environnement. Les différences de météo, d’état du champ et de composition des génotypes ont suffisamment déplacé les motifs spectraux pour limiter la transférabilité, une saison se distinguant comme particulièrement difficile à prédire à partir des autres.
Ce que cela signifie pour la sélection et la télédétection
Pour les sélectionneurs et les scientifiques des cultures, l’étude offre à la fois un encouragement et une mise en garde. Le balayage hyperspectral associé à des méthodes d’apprentissage automatique relativement simples est déjà un outil puissant pour l’estimation à haut débit de caractères stables et intégratifs comme la structure foliaire et l’état azoté, et peut se généraliser raisonnablement bien entre génotypes et années pour ces cibles. En revanche, la même approche est beaucoup moins fiable pour des caractères physiologiques rapides et sensibles à l’environnement lorsque les modèles sont appliqués en dehors des conditions sur lesquelles ils ont été entraînés. Les auteurs concluent que les méthodes hyperspectrales sont prêtes à soutenir le criblage à grande échelle de certains caractères clés du maïs, mais que prédire le comportement physiologique dynamique à travers les environnements exigera des données d’entraînement plus riches, des modèles plus avancés et peut-être des types de mesures complémentaires.
Citation: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Mots-clés: réflectance hyperspectrale, maïs, apprentissage automatique, phénotypage des plantes, photosynthèse