Clear Sky Science · fr
Modélisation taxonomique et classification dans le rapport d'incidents matériels spatiaux
Identifier des motifs dans les incidents de vol spatial
Chaque mission spatiale repose sur d'innombrables composants matériels qui doivent fonctionner sans faille, des boulons et câbles aux systèmes de survie. Lorsqu'un incident survient, les ingénieurs rédigent des rapports détaillés de divergence, mais la NASA possède aujourd'hui plus de 54 000 de ces fiches — bien trop pour que des personnes les lisent une à une. Cette étude montre comment des outils modernes de langage et d'apprentissage automatique peuvent transformer cette montagne de textes en connaissances organisées, aidant les ingénieurs à repérer des motifs de défaillance, améliorer les conceptions et renforcer la sécurité des astronautes.
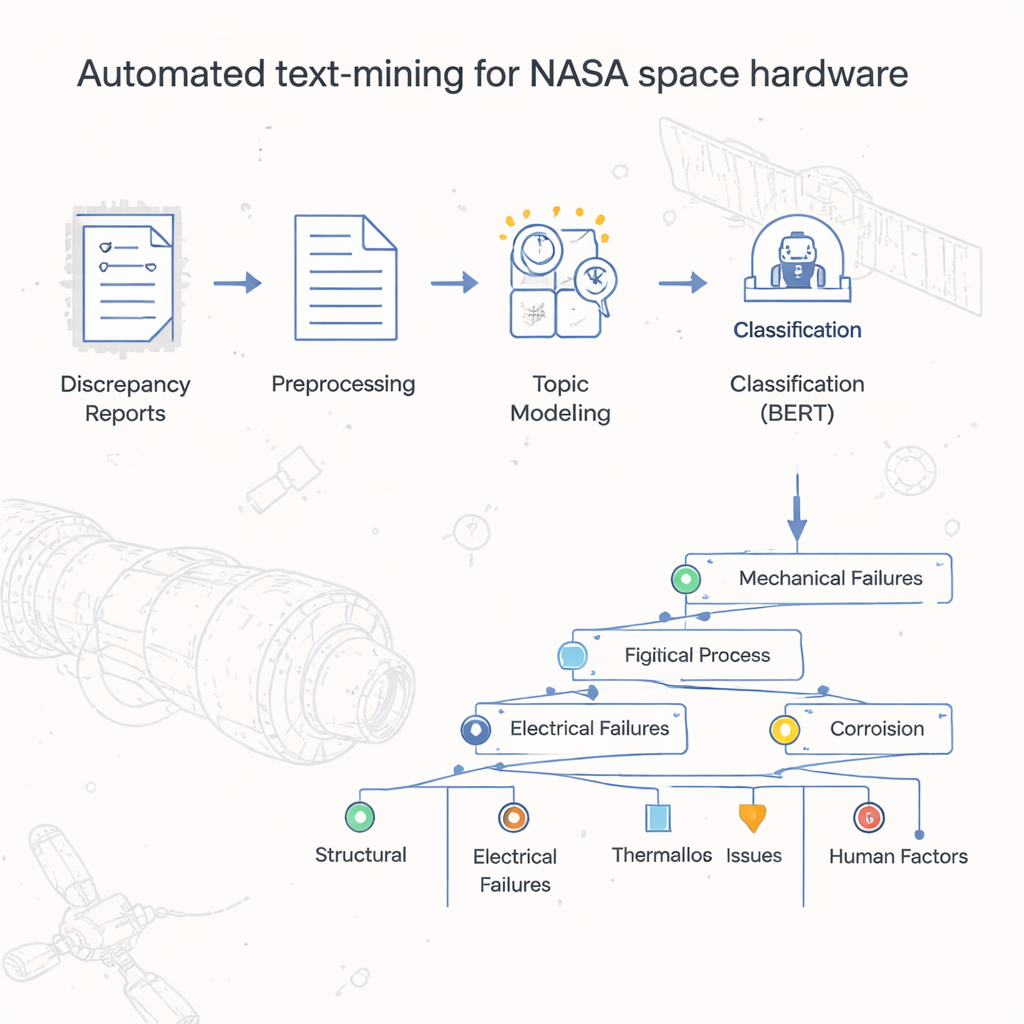
Des piles de rapports à une vision structurée
Pendant des décennies, le Johnson Space Center de la NASA a conservé les rapports de défaillance et de divergence matérielle sous forme de documents numériques, souvent comparables à des versions numérisées d'anciens formulaires papier. Des totaux simples sur tableur révélaient quels codes officiels de défaut revenaient le plus souvent, mais l'histoire réelle — les causes spécifiques, les étapes et les conditions ayant mené aux incidents — était enfouie dans des champs de texte libre. Lire et catégoriser à la main plus de 54 000 rapports prendrait un temps prohibitif. Les auteurs ont entrepris de construire une méthode automatisée pour classer et regrouper ces rapports, créant une sorte de « carte » ou taxonomie qui capture comment le matériel spatial échoue réellement dans la pratique quotidienne.
Apprendre aux ordinateurs à lire le langage de l'ingénierie
L'équipe a d'abord nettoyé le texte de chaque rapport pour que les ordinateurs puissent le traiter efficacement. Ils ont supprimé les symboles et chiffres parasites qui ajoutaient du bruit, découpé les phrases en mots individuels et converti ces mots en une forme de base plus simple (par exemple, transformer « leaked » et « leaking » en « leak »). Les mots courants peu porteurs de sens, comme « the » ou « and », ont été filtrés. Une fois le texte standardisé, les chercheurs l'ont converti en nombres exploitables par des algorithmes d'apprentissage automatique, en utilisant des techniques établies qui saisissent la fréquence des mots et leur capacité à caractériser un document. Ce travail préparatoire leur a permis d'appliquer des outils puissants, initialement développés pour des tâches de langage général, à l'univers très spécialisé des rapports matériels spatiaux.
Construire un arbre des types de défaillance
Au cœur du projet se trouve un modèle en deux étapes que les auteurs appellent LDA-BERT. La première étape, Latent Dirichlet Allocation (LDA), découvre automatiquement des thèmes — appelés topics — en recherchant des motifs de mots qui tendent à apparaître ensemble à travers des milliers de rapports. Un même rapport peut combiner plusieurs topics, reflétant la réalité où un problème matériel peut avoir plusieurs facteurs contributifs. La seconde étape utilise BERT, un modèle de langage moderne, pour vérifier et affiner la qualité de la séparation entre ces topics. En traitant les topics issus de la LDA comme des étiquettes provisoires et en entraînant BERT à les prédire, les chercheurs ont pu identifier le nombre et la combinaison de topics qui donnaient des classifications stables et précises. Ils ont ensuite subdivisé chaque topic en sous-topics, en employant le clustering et des contrôles statistiques, afin de construire une taxonomie arborescente qui organise les rapports de défaillance depuis les codes de défaut larges jusqu'aux étiquettes détaillées au niveau des processus.
Transformer la taxonomie en tendances exploitables
Une fois la taxonomie en place, l'équipe l'a visualisée au moyen de tableaux de bord et d'outils interactifs. Chaque branche et sous-branche de l'arbre pouvait être reliée à d'autres informations contenues dans les rapports : moment où le problème a été signalé, durée jusqu'à sa clôture, organisation responsable et décision finale prise. Des graphiques temporels montraient si certains types de problèmes — tels que des omissions lors des inspections ou des problèmes de données de tolérance — devenaient plus ou moins fréquents au fil des années. Des cartes lexicales donnaient une impression rapide du langage utilisé dans chaque groupe sans avoir besoin de lire chaque rapport. Ces vues aident les responsables à cibler les défaillances de processus à forte croissance et à fort impact, guidant la formation, l'évolution des procédures ou les modifications de conception là où elles seront les plus utiles.
Limites de la recherche automatique de causes profondes
Les chercheurs ont également exploré des outils qui tentent d'aller au-delà du simple étiquetage et de la détection de tendances pour inférer des relations directes de cause à effet à partir du texte. Ils ont testé des systèmes comme INDRA-Eidos et des règles personnalisées construites avec la bibliothèque spaCy. Bien que ces outils aient pu extraire certaines paires cause-effet et les visualiser sous forme de réseaux interactifs, beaucoup des liens suggérés étaient trop vagues ou déroutants pour être utiles. En pratique, les modèles ont peiné parce que les rapports originaux n'énonçaient souvent pas clairement les causes profondes ; les ingénieurs les suggéraient ou les laissaient pour une enquête ultérieure. L'étude conclut que l'automatisation fiable de la découverte des causes profondes exigerait à la fois une saisie de données plus riche — par exemple des champs explicites pour les causes probables — et un entraînement de modèles beaucoup plus coûteux et fortement adapté, ce qui n'est pas justifié pour cette analyse ponctuelle.
Pourquoi cela compte pour les missions futures
En transformant une grande archive non structurée de rapports de défaillance en une taxonomie claire et hiérarchisée, ce travail offre à la NASA un moyen pratique de surveiller comment et pourquoi les problèmes matériels surviennent au fil du temps. Même si les méthodes ne peuvent pas encore remplacer le jugement humain pour une analyse approfondie des causes profondes, elles excellent pour analyser de vastes quantités de texte afin de mettre en évidence où les problèmes se concentrent et quels types de processus sont généralement impliqués. Ce type d'alerte précoce et d'information structurée peut aider les équipes d'ingénierie à cibler leur attention, affiner les procédures et concevoir des systèmes plus robustes — des mesures concrètes pour des missions vers la Lune, Mars et au-delà plus sûres et plus fiables.
Citation: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Mots-clés: défaillances du matériel spatial, traitement du langage naturel, modélisation thématique, analyse des risques en ingénierie, rapports de divergence de la NASA