Clear Sky Science · fr
Représentation collaborative et apprentissage semi‑supervisé dirigé par la confiance pour la classification d’images hyperspectrales
Des yeux plus précis sur les couleurs cachées de la Terre
Pour suivre la santé des cultures ou surveiller les zones humides, les scientifiques s’appuient de plus en plus sur des images hyperspectrales — des photographies détaillées qui capturent des dizaines voire des centaines de longueurs d’onde invisibles à l’œil nu. Ces données riches promettent des cartes d’occupation du sol et de végétation plus précises, mais elles sont notoirement difficiles à analyser. Cette étude présente une nouvelle méthode, appelée GCN‑ARE, qui interprète ces images complexes de façon plus fiable et efficace, ouvrant la voie à un meilleur suivi environnemental, à une agriculture plus intelligente et à une planification urbaine améliorée.
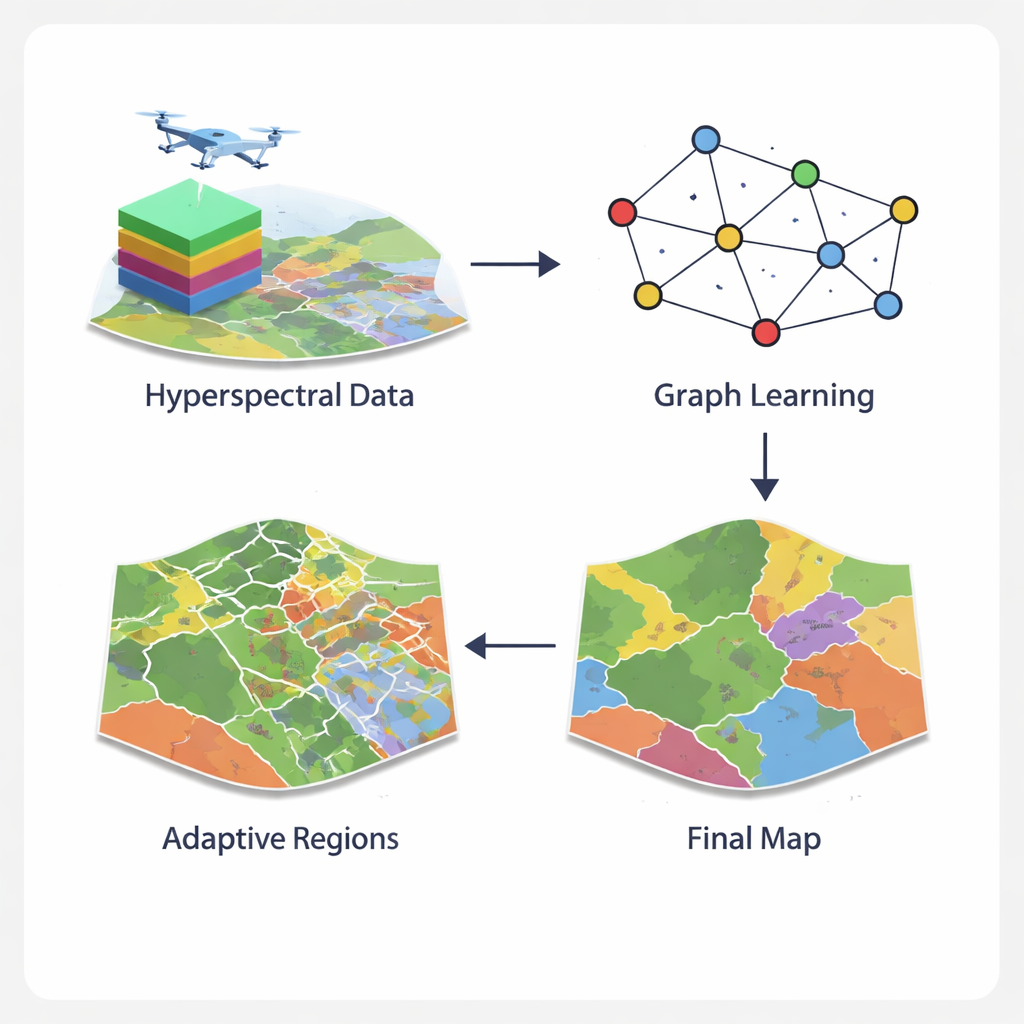
Pourquoi les images hyperspectrales sont si difficiles
Contrairement à une photo ordinaire, une image hyperspectrale enregistre un spectre de couleurs complet pour chaque pixel. Cela permet, par exemple, de distinguer une herbe saine d’une herbe stressée, ou différents types de cultures qui paraissent presque identiques en imagerie classique. Mais cette richesse pose des défis. Les zones voisines peuvent mélanger plusieurs types d’occupation du sol, les classes sont souvent déséquilibrées (certaines couvertures sont rares) et le relief peut être irrégulier — pensez à une végétation morcelée ou à des blocs urbains enchevêtrés. L’apprentissage automatique traditionnel dépend de caractéristiques conçues manuellement et manque souvent des motifs subtils, tandis que les réseaux profonds modernes comme les réseaux convolutionnels et les Transformers peuvent peiner avec des formes irrégulières et exigent une forte puissance de calcul. En conséquence, des modèles performants sur une scène peuvent échouer sur une autre.
Transformer les pixels en un réseau intelligent
Le cadre GCN‑ARE s’attaque à ces problèmes en repensant la façon dont les images hyperspectrales sont représentées. Plutôt que de traiter chaque pixel isolément ou de les forcer dans des voisinages carrés rigides, la méthode construit un graphe — un réseau où les pixels sont des nœuds et où les pixels proches sont connectés. Un opérateur de graphe spécialisé maintient la stabilité du flux d’information, évitant des problèmes numériques qui peuvent perturber l’entraînement lorsque le terrain est chaotique. Un réseau convolutionnel de graphe propage et affine ensuite l’information le long de ce réseau, combinant ce que chaque pixel « voit » dans son spectre avec ce que révèlent ses voisins. Cette vue en graphe capture plus naturellement des agencements spatiaux complexes, tels que des limites de champs dentelées ou une végétation urbaine fragmentée, mieux que les filtres d’image standard.
Réduire la taille des régions complexes
Même avec un modèle de graphe puissant, certaines parties d’une image restent difficiles à classer — par exemple les zones frontières où des cultures rencontrent des routes ou où la végétation se mêle à des sols nus. GCN‑ARE règle cela en scindant de manière adaptative la scène en régions selon la qualité de leur classification. Si une région performe mal, elle est automatiquement subdivisée en morceaux plus petits et plus homogènes via une étape de clustering qui regroupe les pixels semblables. Ce processus est guidé par des règles statistiques, ce n’est donc pas qu’un artifice visuel : les auteurs montrent que, en théorie, ces divisions réduisent l’erreur attendue du modèle, l’aidant à distinguer des différences subtiles d’occupation du sol de manière plus fiable.
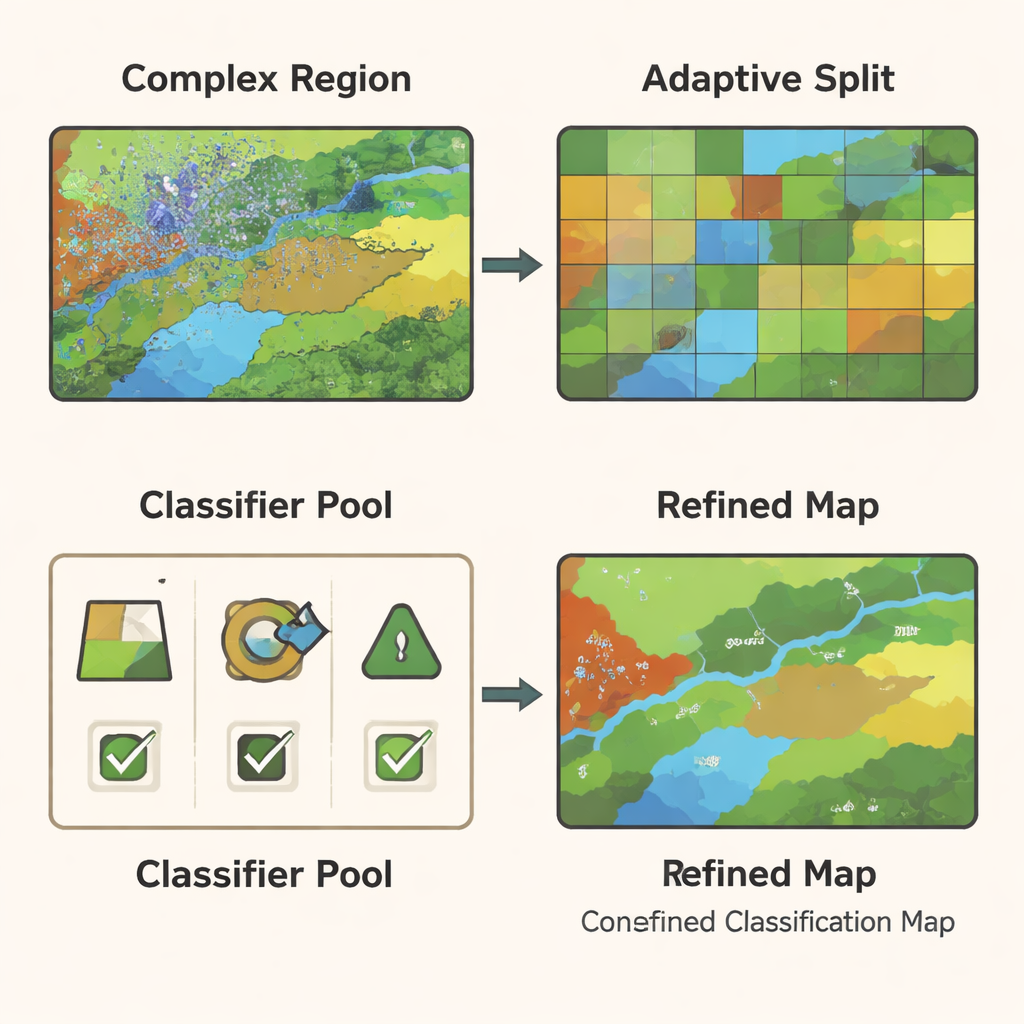
Laisser plusieurs classifieurs voter — mais intelligemment
Différents types de classifieurs — tels que les arbres de décision, les machines à vecteurs de support et les forêts aléatoires — excellent dans des conditions différentes. Plutôt que de parier sur un seul modèle, GCN‑ARE entraîne un petit ensemble de ces classifieurs sur les caractéristiques dérivées du graphe puis choisit entre eux région par région. Le choix n’est pas laissé au hasard : un outil mathématique appelé inégalité de Hoeffding est utilisé pour montrer que, à mesure qu’une région contient plus de données, la probabilité de sélectionner réellement le meilleur classifieur augmente rapidement. En pratique, le système compare les prédictions des classifieurs. S’ils sont d’accord, il accepte la décision consensuelle ; s’ils divergent, il active le classifieur « meilleur » choisi pour la région. Cet ensemble adaptatif rend la carte finale stable dans les zones faciles et plus précise dans les zones difficiles.
Des preuves de performance sur des cas réels
Les auteurs ont testé GCN‑ARE sur quatre jeux de données bien connus : des zones humides au Botswana, une zone urbaine autour de Houston, des terres agricoles en Indiana (Indian Pines) et une scène agricole haute résolution en Chine (WHU‑Hi‑LongKou). Sur l’ensemble de ces cas, leur méthode a obtenu une précision globale plus élevée, une meilleure précision moyenne par classe et des scores d’accord plus forts que des approches de pointe telles que les graph attention networks et les Vision Transformers — améliorant typiquement la précision globale de l’ordre de 1,5 à 5,7 points de pourcentage. Elle a été particulièrement performante pour reconnaître les classes rares et les frontières complexes, et ce avec des temps de calcul et une empreinte mémoire modestes. Des expériences d’ablation ont montré que la subdivision adaptative des régions et l’ensemble dynamique étaient essentiels — la suppression de l’un ou l’autre réduisait sensiblement les performances.
Ce que cela signifie pour les applications courantes
Concrètement, GCN‑ARE est une manière plus intelligente de transformer des données hyperspectrales brutes en cartes fiables. En combinant une représentation en graphe stable, un affinage ciblé des régions et une sélection de modèles fondée sur des principes statistiques, il produit des cartes d’occupation du sol plus nettes même lorsque les données annotées sont rares et que le paysage est chaotique. Pour les agriculteurs, cela peut signifier un suivi des cultures plus précis avec moins de mesures sur le terrain ; pour les agences environnementales, un suivi plus fiable des zones humides, des forêts ou de l’étalement urbain. Bien que la méthode actuelle fasse encore face à des défis à très grande échelle, les auteurs envisagent des pistes pour la rendre plus rapide et légère, suggérant que de tels outils de cartographie adaptatifs et pilotés par la confiance deviendront de plus en plus importants à mesure que les capteurs hyperspectraux se déploieront depuis les satellites vers les avions et les drones.
Citation: Chen, Y., Lu, H. & Huang, X. Collaborative representation and confidence-driven semi-supervised learning for hyperspectral image classification. Sci Rep 16, 6180 (2026). https://doi.org/10.1038/s41598-026-36806-6
Mots-clés: imagerie hyperspectrale, cartographie de l’occupation du sol, réseaux de neurones graphiques, apprentissage par ensemble, télédétection