Clear Sky Science · fr
Vérifier l’authenticité des informations en ourdou par apprentissage profond avec concaténation d’embeddings BERT et GloVe
Pourquoi il est important de repérer les fausses informations en ourdou
Au Pakistan et dans le monde, davantage de personnes consultent désormais les nouvelles via des sites web et les réseaux sociaux plutôt que par les journaux papier ou la télévision. Ce changement facilite la diffusion rapide de récits faux, en particulier dans des langues nationales comme l’ourdou où les outils numériques sont limités. Cette étude s’attaque à une question simple mais urgente : l’intelligence artificielle moderne peut‑elle distinguer automatiquement les informations réelles des informations fausses en ourdou, aidant ainsi les lecteurs ordinaires, les journalistes et les plateformes à se protéger contre les contenus trompeurs ?
Le défi croissant de la désinformation en ligne
Les auteurs commencent par expliquer comment des titres fabriqués et des récits déformés peuvent façonner l’opinion publique, alimenter des tensions politiques et même nuire à la santé et aux finances des personnes. Alors que de nombreux sites de vérification des faits et projets de recherche se concentrent sur l’anglais, les langues régionales comme l’ourdou sont souvent laissées pour compte. Les ressources ourdou existantes ne comptent que quelques milliers d’articles, beaucoup étant des traductions de l’anglais et centrées sur des sujets restreints comme la politique. Cela complique l’entraînement de systèmes informatiques fiables capables de reconnaître des contenus suspects dans la langue que la plupart des Pakistanais lisent réellement.
Constituer une grande collection d’articles ourdous
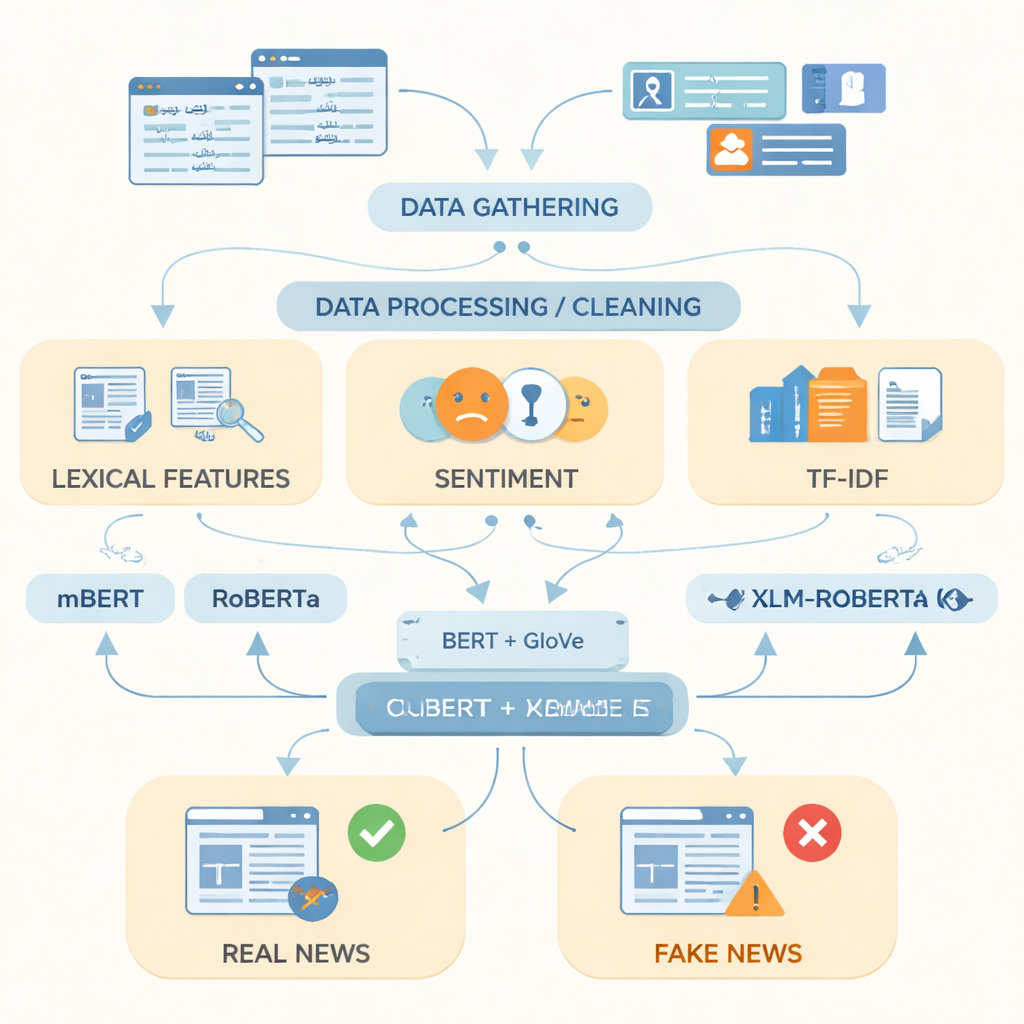
Pour combler ce vide, les chercheurs ont rassemblé ce qu’ils décrivent comme le jeu de données le plus étendu d’articles ourdous sur les fausses informations à ce jour, contenant 14 178 articles collectés entre 2017 et 2023 sur des sites d’information pakistanais reconnus et des plateformes en ligne. Les articles couvrent quinze domaines de la vie quotidienne, notamment la politique, la santé, l’éducation, les affaires, la criminalité, le sport et l’environnement. En s’appuyant sur des sources de vérification des faits comme PolitiFact, FactCheck et des API d’actualités spécialisées, chaque élément a été étiqueté comme réel ou faux ; les articles partiellement vrais ont été regroupés avec les articles réels pour refléter un reportage plus nuancé. L’équipe a ensuite nettoyé les textes en supprimant les doublons, les adresses web et la ponctuation superflue, en découpant les phrases en mots et en éliminant les mots de remplissage très fréquents.
Apprendre aux ordinateurs à reconnaître les fausses informations
Après la préparation des données, les auteurs se sont intéressés à la meilleure façon de représenter le texte ourdou pour un ordinateur. Ils ont combiné des indicateurs simples, tels que les mots fréquemment utilisés, la tonalité émotionnelle du langage et les scores de fréquence de termes, avec deux techniques puissantes de représentation des mots. La première, appelée GloVe, traite chaque mot comme un vecteur numérique fixe basé sur la fréquence d’apparition conjointe avec d’autres mots dans l’ensemble du corpus. La seconde, fondée sur des modèles de type BERT, considère chaque mot dans son contexte de phrase et lui attribue une signification dépendant du contexte. En joignant ces deux vues du langage en une représentation unique et plus riche, le système peut saisir à la fois les schémas globaux et les variations subtiles de formulation qui distinguent souvent les récits faux des récits réels.
Tester des modèles de langage avancés
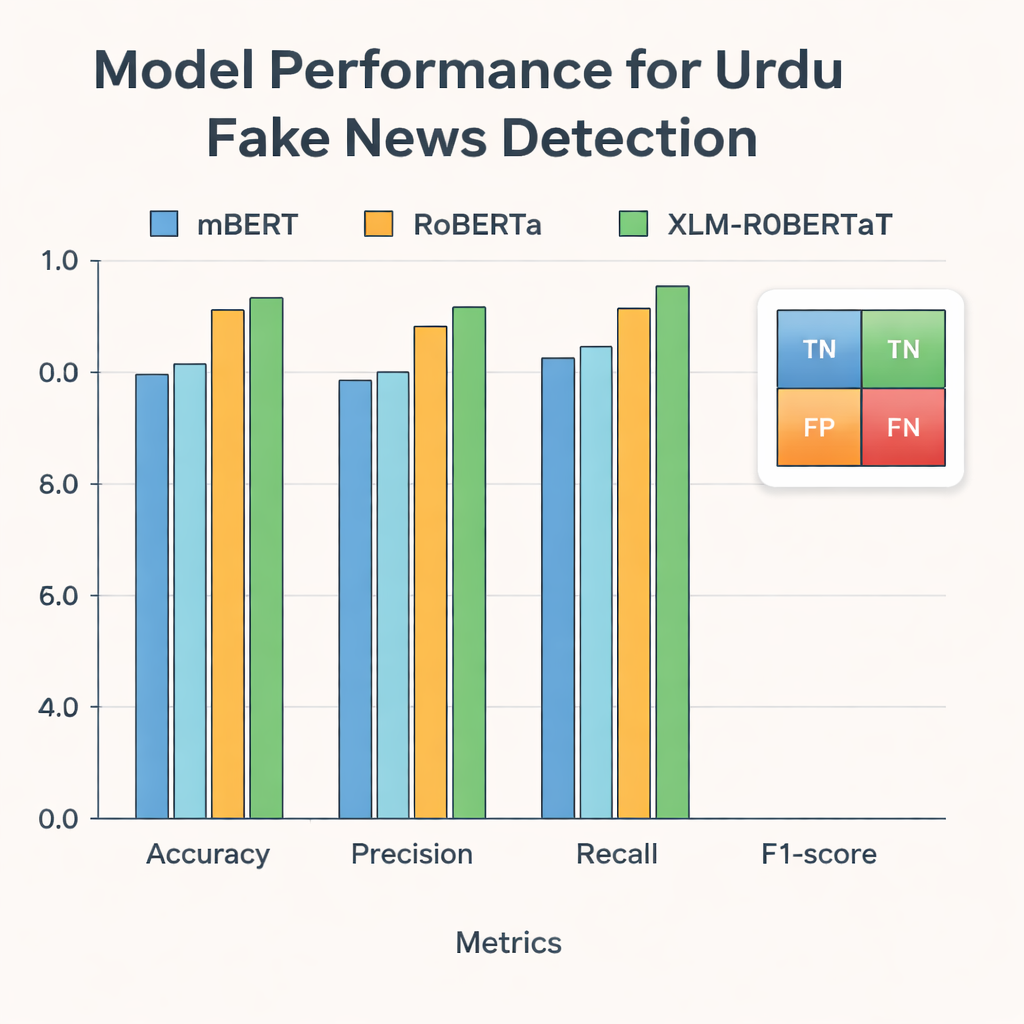
Les chercheurs ont ensuite alimenté ces représentations dans trois modèles modernes d’apprentissage profond entraînés sur des textes en plusieurs langues : mBERT, RoBERTa et XLM‑RoBERTa. Les trois modèles ont été affinés sur le jeu de données ourdou pour prédire si chaque article était réel ou faux. Leur performance a été évaluée avec des mesures standard : l’exactitude (fréquence de réponses correctes), la précision (proportion des articles signalés comme faux qui étaient réellement faux), le rappel (part des articles faux détectés) et le score F1, qui équilibre précision et rappel. Si tous les modèles ont obtenu de bons résultats, XLM‑RoBERTa combiné à la représentation fusionnée BERT et GloVe s’est imposé comme le meilleur, classant correctement environ 96 % des articles de test et atteignant un score F1 de 0,956 — supérieur aux systèmes ourdou antérieurs qui utilisaient des jeux de données plus petits ou des méthodes plus simples.
Ce que cela signifie pour les lecteurs au quotidien
Pour le grand public, le message est simple : avec suffisamment de données ourdou de qualité et le bon type d’IA, il est désormais possible de construire des outils qui signalent automatiquement avec une grande fiabilité les articles probablement faux. L’étude montre que des représentations linguistiques plus riches et des modèles multilingues donnent aux ordinateurs une bien meilleure compréhension de la manière dont l’ourdou est réellement écrit selon les régions et les sujets. Bien que ce travail se concentre pour l’instant uniquement sur le texte et n’analyse pas encore les images ou les comportements sur les réseaux sociaux, il pose une base solide pour des systèmes futurs pouvant fonctionner entre langues et types de médias. En termes pratiques, cette recherche rapproche le Pakistan d’extensions de navigateur, de tableaux de bord pour salles de rédaction ou de filtres de réseaux sociaux qui aident les gens à séparer le vrai du faux dans la langue qu’ils utilisent au quotidien.
Citation: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Mots-clés: détection des fausses informations, langue ourdou, apprentissage profond, BERT et GloVe, désinformation en ligne