Clear Sky Science · fr
Améliorer l’estimation de la profondeur à longue portée via un encodage hétérogène CNN-transformer et une fusion sémantique inter-dimensionnelle
Voir la profondeur avec un seul œil
Les robots modernes, les voitures autonomes et les drones s’appuient souvent sur des capteurs 3D coûteux pour évaluer les distances. Cette étude montre comment des caméras couleur ordinaires, comme celles des smartphones, peuvent être poussées bien plus loin : les auteurs conçoivent une nouvelle manière pour un ordinateur d’inférer la profondeur à partir d’une seule image, en se concentrant sur la partie la plus difficile du scénario — les grandes distances, où les obstacles sont petits, flous et faciles à mal estimer.
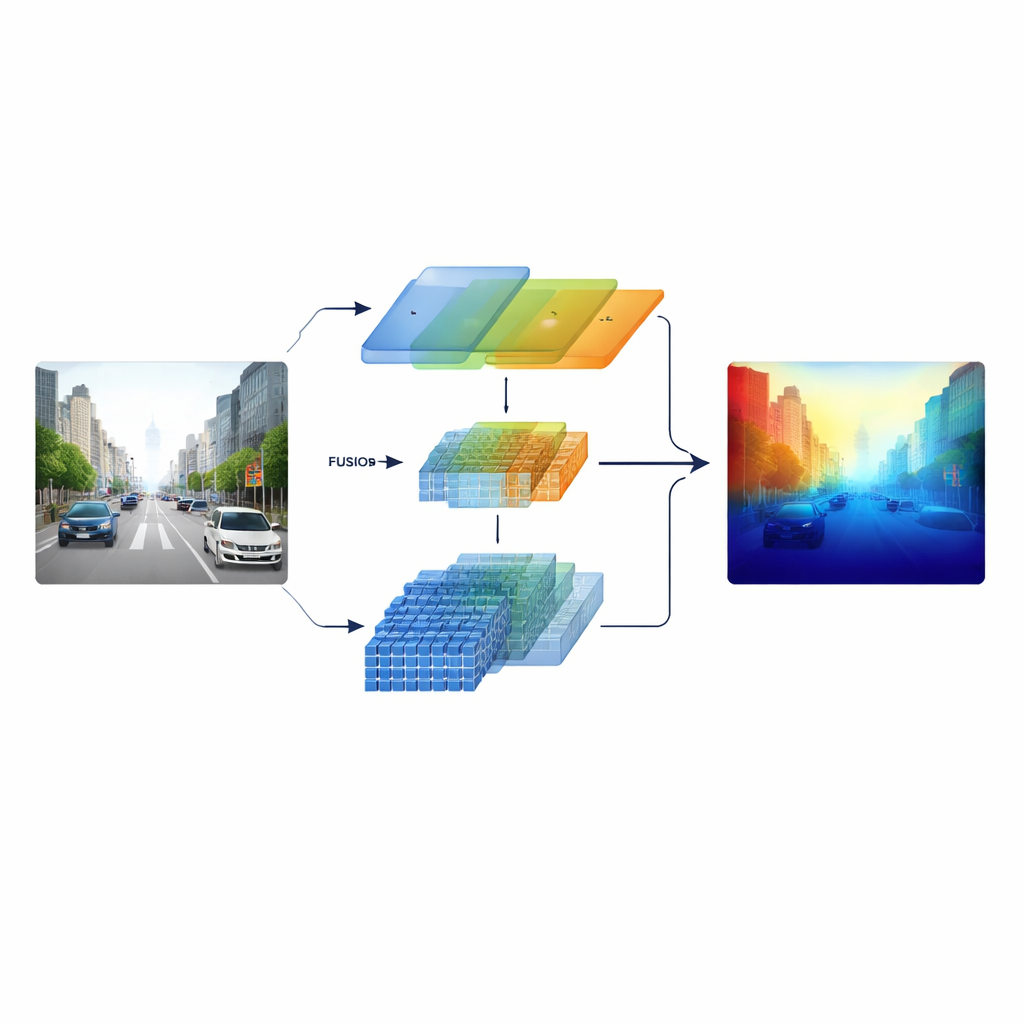
Pourquoi il est si difficile d’évaluer les objets lointains
L’estimation de la profondeur à partir d’une seule image, appelée estimation monoculaire de la profondeur, est une sorte d’illusion visuelle assistée par l’apprentissage. Les objets proches couvrent de nombreux pixels et présentent des textures nettes, si bien que les réseaux neuronaux actuels performent déjà bien à courte et moyenne distance. Plus loin, en revanche, les voitures rétrécissent à quelques pixels et les marquages routiers se perdent dans la brume. Les réseaux convolutifs classiques sont efficaces pour repérer des détails locaux fins mais peinent à saisir la vue d’ensemble d’une rue entière. Les modèles Transformer, plus récents, captent bien le contexte global mais sont moins sensibles aux arêtes et textures fines. En conséquence, ces deux familles de méthodes échouent souvent précisément là où une navigation sûre a le plus besoin d’estimations fiables : sur de longues distances.
Mêler deux façons de voir
Les chercheurs s’attaquent à ce problème en construisant un encodeur « hétérogène » qui exécute en parallèle deux types différents de traitement visuel. Une branche repose sur un réseau convolutionnel de type ResNet classique, spécialisé dans les motifs locaux nets comme les marquages au sol, les poteaux et les contours d’objets. L’autre branche utilise un Swin Transformer, conçu pour capturer des connexions à longue portée à travers l’image, telles que l’organisation d’un corridor routier ou la ligne d’horizon des bâtiments lointains. Plutôt que de ne combiner ces deux visions qu’en fin de traitement, le système conserve des caractéristiques multi-échelles issues des deux branches et les injecte dans une étape de fusion soigneusement conçue, de sorte que la structure fine et le contexte large s’éclairent mutuellement tout au long du processus.
Traverser canaux, espace et échelle
Au cœur du modèle se trouve un module de Fusion Sémantique Inter-dimensionnelle qui joue le rôle d’une salle de réunion intelligente pour les deux flux d’informations. D’abord, il décide quels canaux — différents types de motifs visuels appris — méritent plus d’attention, en équilibrant les signaux provenant des textures détaillées et des indices de scène de haut niveau. Ensuite, il analyse séparément les directions horizontale et verticale, particulièrement signifiantes dans des scènes peuplées de routes, bâtiments et arbres, afin de mettre en avant les structures importantes qui s’étendent à travers l’image. Enfin, il mêle des caractéristiques superficielles riches en détails avec des caractéristiques plus profondes et abstraites sur plusieurs échelles. Une étape de pondération apprenante permet au réseau de décider combien faire confiance à chaque branche pour chaque région, de sorte que les petits objets lointains ne soient pas submergés par le paysage proche.
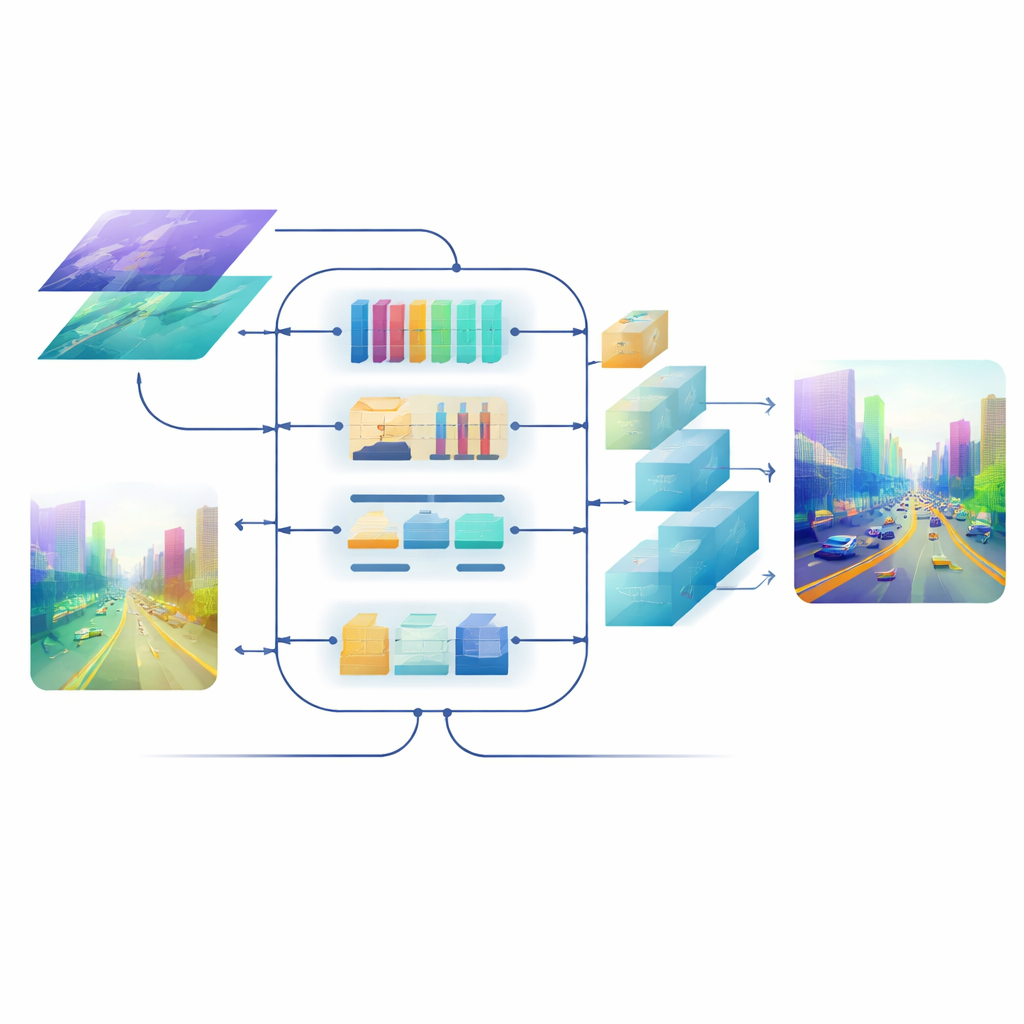
Aiguiser l’image finale
Même avec de bonnes caractéristiques fusionnées, les reconvertir en une carte de profondeur en pleine résolution peut estomper les contours et effacer les structures fines. Pour éviter cela, l’équipe conçoit un décodeur piloté par l’attention. Ses blocs de remontée en résolution utilisent des convolutions depth-wise légères pour agrandir la carte sans perdre le contexte, et un mécanisme d’auto-attention multi-échelle regroupe les canaux de caractéristiques afin que le calcul de l’attention soit efficace. Cette étape affine les prédictions de profondeur à chaque échelle tout en maîtrisant le coût de calcul. Le résultat est un champ de profondeur lisse et cohérent où les bords des objets — comme le profil d’un cycliste lointain ou les barreaux d’un lit superposé — restent nets.
Quelle efficacité en conditions réelles
La méthode est testée sur plusieurs jeux de données standards. Sur KITTI, une vaste collection de scènes de conduite, le modèle atteint des performances de pointe sur la plupart des métriques courantes et, surtout, produit l’erreur la plus faible dans les zones spécialement dédiées aux longues distances. Il fournit également des contours de profondeur plus propres autour des objets que les systèmes concurrents. Sur NYU Depth V2, qui contient des scènes intérieures, et sur la référence SUN RGB-D, le même modèle se généralise avec succès, reconstruisant meubles et agencements de pièces en nuages de points 3D convaincants. Des études d’ablation — tests systématiques qui retirent ou remplacent des composants — montrent que chaque élément proposé, de l’encodeur hybride au module de fusion en passant par le bloc d’attention du décodeur, améliore de manière mesurable les performances, en particulier pour les zones lointaines à faible texture.
Ce que cela signifie pour la technologie du quotidien
En termes simples, ce travail apprend à un réseau neuronal à utiliser à la fois une loupe et un objectif grand-angle, et à les combiner judicieusement. En équilibrant mieux les détails locaux et la compréhension globale de la scène, le cadre proposé améliore significativement la capacité d’une seule caméra à estimer la profondeur loin sur la route ou à travers une pièce. Cela rend plus pratique l’équipement de robots, véhicules et drones avec des capteurs moins coûteux tout en leur fournissant une perception 3D riche du monde — une étape importante vers des systèmes autonomes plus sûrs, plus performants et plus abordables.
Citation: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Mots-clés: estimation de profondeur monoculaire, vision par ordinateur, fusion transformer et CNN, conduite autonome, reconstruction de scènes 3D