Clear Sky Science · fr
Le recalage des moyennes de noyau améliore l’estimation du risque sous des changements de distribution spatiale
Pourquoi il est important d’estimer le risque quand la carte change
Les modèles d’apprentissage automatique sont de plus en plus utilisés pour prévoir où vivront des espèces, comment les tumeurs sont organisées dans les tissus ou comment la pollution se propage. Pourtant, les données utilisées pour entraîner ces modèles sont souvent collectées dans des lieux très spécifiques — échantillonnage dense près des villes, des hôpitaux ou des sites de terrain faciles d’accès — tandis que les modèles sont appliqués à des régions beaucoup plus larges et différentes. Ce décalage entre l’origine des données et les zones de prédiction peut donner une impression de sécurité et de précision des modèles qui n’est pas méritée. L’article « Kernel mean matching enhances risk estimation under spatial distribution shifts » pose une question apparemment simple : quand le monde diffère de vos données d’entraînement, à quel point votre modèle peut-il se tromper, et comment le détecter ?
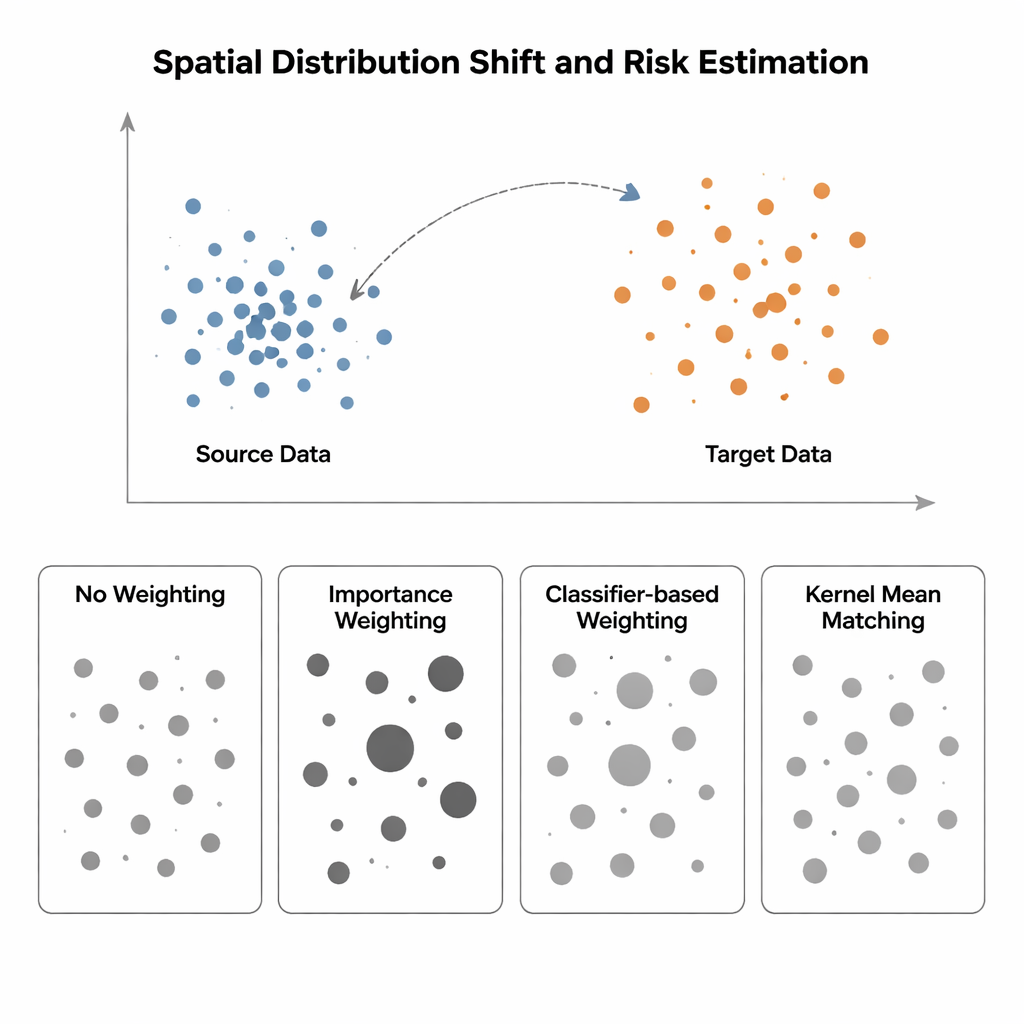
Quand entraînement et test vivent dans deux mondes différents
En statistique, le « risque » d’un modèle est son erreur attendue sur de nouvelles données non vues. Les méthodes d’évaluation standard — comme la validation croisée ou la mise à l’écart aléatoire d’un jeu de test — supposent silencieusement que les données d’entraînement et de test sont tirées de la même distribution. Les données spatiales rompent cette hypothèse. Les gradients environnementaux, l’échantillonnage en grappes et le changement climatique signifient que les conditions où l’on entraîne un modèle peuvent différer fortement de celles où on le déploie. Par exemple, les observations d’espèces sont souvent concentrées près des routes, alors que les décisions de conservation concernent des zones isolées ; des échantillons de tumeurs peuvent provenir d’une partie d’un tissu, alors que des prédictions sont nécessaires ailleurs. Dans de tels cas, les estimations conventionnelles du risque tendent à être trop optimistes, masquant à quel point un modèle peut échouer dans de nouveaux emplacements.
Les outils anciens peinent face au biais spatial
L’étude compare quatre méthodes pour estimer le risque d’un modèle quand la distribution d’entrée change d’une région « source » (où les étiquettes sont connues) vers une région « cible » (où les étiquettes sont rares ou absentes). La méthode la plus simple, dite Sans Pondération, mesure simplement l’erreur moyenne sur les données disponibles et suppose que source et cible se ressemblent — hypothèse qui échoue en présence de biais spatial. La pondération d’importance tente de corriger cela en redimensionnant chaque échantillon source selon la fréquence de ce type de point dans la cible par rapport à la source. En théorie, cela permet de retrouver le risque correct, mais en pratique cela exige d’estimer des densités de probabilité en grande dimension. Quand les données source sont fortement regroupées et les données cible plus dispersées — situation typique en écologie spatiale ou en imagerie médicale — ces estimations de densité deviennent peu fiables, et quelques échantillons reçoivent des poids énormes, rendant l’estimation du risque très instable. Les approches basées sur un classifieur, qui entraînent un modèle pour distinguer points source et cible puis convertissent ses probabilités en poids, évitent l’estimation explicite de densité mais produisent souvent des risques mal calibrés parce qu’elles optimisent la précision de classification, pas l’alignement des distributions.
Une autre voie : faire correspondre les distributions directement
Les auteurs préconisent le Kernel Mean Matching (KMM), une approche qui évite complètement l’estimation de densité. Plutôt que d’essayer de calculer la probabilité de chaque point sous les distributions source et cible, KMM recherche des poids sur les échantillons source qui font correspondre leur « empreinte » moyenne dans un espace de caractéristiques défini par un noyau flexible à celle des échantillons cible. Intuitivement, elle étire ou réduit l’influence de chaque point source afin que, collectivement, le nuage de points source pondéré ressemble au nuage cible. Une fois ces poids trouvés, le risque est estimé comme une moyenne pondérée des erreurs sur la source. Un outil complémentaire, la fonction de corrélation locale, quantifie à quel point les données sont regroupées dans l’espace ; il sert de diagnostic pour indiquer quand les décalages de distribution sont suffisamment forts pour que la repondération ait une utilité.
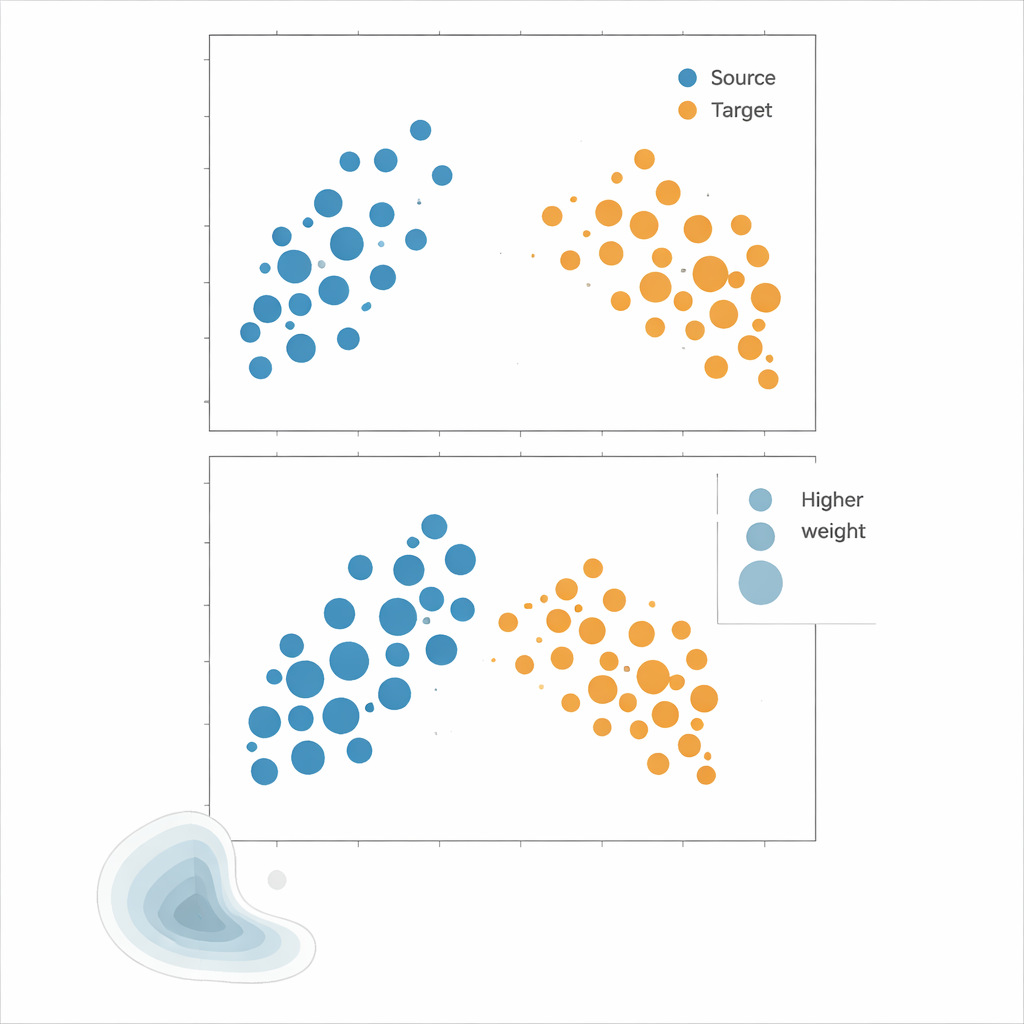
Mettre les méthodes à l’épreuve
Pour savoir quelle stratégie fonctionne le mieux, les auteurs réalisent des expériences étendues sur des données synthétiques et réelles. Les « paysages » synthétiques sont construits à partir de mélanges de grappes gaussiennes dont l’étendue, la forme et la couverture du domaine peuvent être précisément contrôlées, permettant des tests structurés comme le rognage d’une partie du domaine, le changement de schémas de corrélation entre caractéristiques, ou la bascule entre des motifs de points très regroupés et presque uniformes. Les jeux de données réels incluent des occurrences d’espèces végétales nordiques, décrites par le climat et la localisation, ainsi que des dispositions spatiales de cellules immunitaires dans des tumeurs. Dans ces scénarios, les modèles sont entraînés sur des données source regroupées et évalués sur des données cible moins regroupées, reproduisant des biais d’échantillonnage courants. Les performances sont évaluées selon plusieurs métriques d’erreur, en se concentrant sur la proximité entre le risque estimé par chaque méthode et l’erreur réelle sur la cible.
Un risque plus fiable dans des espaces encombrés et de haute dimension
Dans presque tous les cas synthétiques et sur les jeux de données réels, KMM fournit les estimations de risque les plus précises et les plus stables. Il réduit l’erreur moyenne en pourcentage absolu d’environ 12 à 87 % par rapport aux alternatives, et évite surtout l’« explosion des poids » qui affecte la pondération d’importance en haute dimension. Dans des configurations difficiles de disposition des cellules tumorales, par exemple, la pondération d’importance peut conduire à des erreurs dépassant plusieurs milliers de pourcents, tandis que KMM reste dans des limites gérables. La repondération basée sur un classifieur améliore généralement les méthodes naïves mais reste inférieure à KMM, reflétant son objectif de discrimination plutôt que d’un appariement fidèle des distributions. Ces résultats suggèrent que pour les applications spatiales — où les données sont regroupées, biaisées et de haute dimension — KMM offre une manière principled d’estimer combien on peut faire confiance aux prédictions d’un modèle.
Quelles conséquences pour les décisions du monde réel
Pour les non-spécialistes employant l’apprentissage automatique en écologie, sciences de l’environnement ou biomédecine, le message est simple : les scores de test standards peuvent être dangereusement trompeurs lorsque la région de déploiement diffère de l’origine de vos données. Le Kernel Mean Matching offre un moyen de corriger cela en rééquilibrant l’influence des échantillons d’entraînement pour qu’ils ressemblent statistiquement aux lieux ou tissus qui vous intéressent. L’étude montre que cette approche fournit de façon consistante des estimations d’erreur de modèle plus honnêtes, même sous un biais spatial sévère et avec de nombreuses variables d’entrée. En pratique, cela signifie des recommandations plus fiables pour choisir entre modèles et une image plus claire des endroits où les prédictions sont dignes de confiance — et où la prudence s’impose.
Citation: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Mots-clés: décalage de distribution, modélisation spatiale, recalage des moyennes de noyau, estimation du risque du modèle, données écologiques et biomédicales