Clear Sky Science · fr
Renforcer la résistance adversaire du cache sémantique pour les systèmes sécurisés de génération augmentée par récupération
Pourquoi une mémoire IA plus intelligente compte
À mesure que les chatbots et assistants IA s’introduisent dans les lieux de travail, les salles de classe et même les hôpitaux, ils s’appuient de plus en plus sur un artifice consistant à « se souvenir » des questions précédentes pour répondre plus rapidement et à moindre coût à des questions similaires. Cette mémoire, appelée cache sémantique, peut réduire considérablement les coûts et les délais — mais elle peut aussi ouvrir une porte dérobée permettant à des attaquants de tromper les systèmes pour qu’ils fuient des secrets ou fournissent de mauvaises réponses. Cet article explore ces risques cachés et présente un nouveau dispositif, SAFE-CACHE, qui vise à conserver la rapidité de la mémoire de l’IA tout en la rendant beaucoup plus difficile à exploiter.
Comment les assistants IA réutilisent aujourd’hui des réponses passées
Les grands modèles de langage (LLM) modernes fonctionnent souvent dans une architecture dite de génération augmentée par récupération (RAG). Lorsqu’on pose une question, le système récupère d’abord des documents pertinents puis le LLM rédigent une réponse à partir de ce matériel. Comme beaucoup d’utilisateurs posent des questions quasiment identiques mais formulées différemment, les entreprises ajoutent désormais un cache sémantique : un stockage de anciennes questions et réponses, accompagné d’empreintes mathématiques de leurs sens. Lorsqu’une nouvelle requête arrive, le système vérifie si son empreinte est « suffisamment proche » d’une déjà présente dans le cache ; si c’est le cas, il réutilise simplement l’ancienne réponse au lieu d’exécuter tout le processus de recherche et de génération. Cette idée, déployée par des outils comme GPTCache et des plateformes cloud de Microsoft et Google, fait économiser de l’argent et accélère les réponses dans les assistants de support client, les outils de chat d’entreprise et autres services IA à fort trafic. 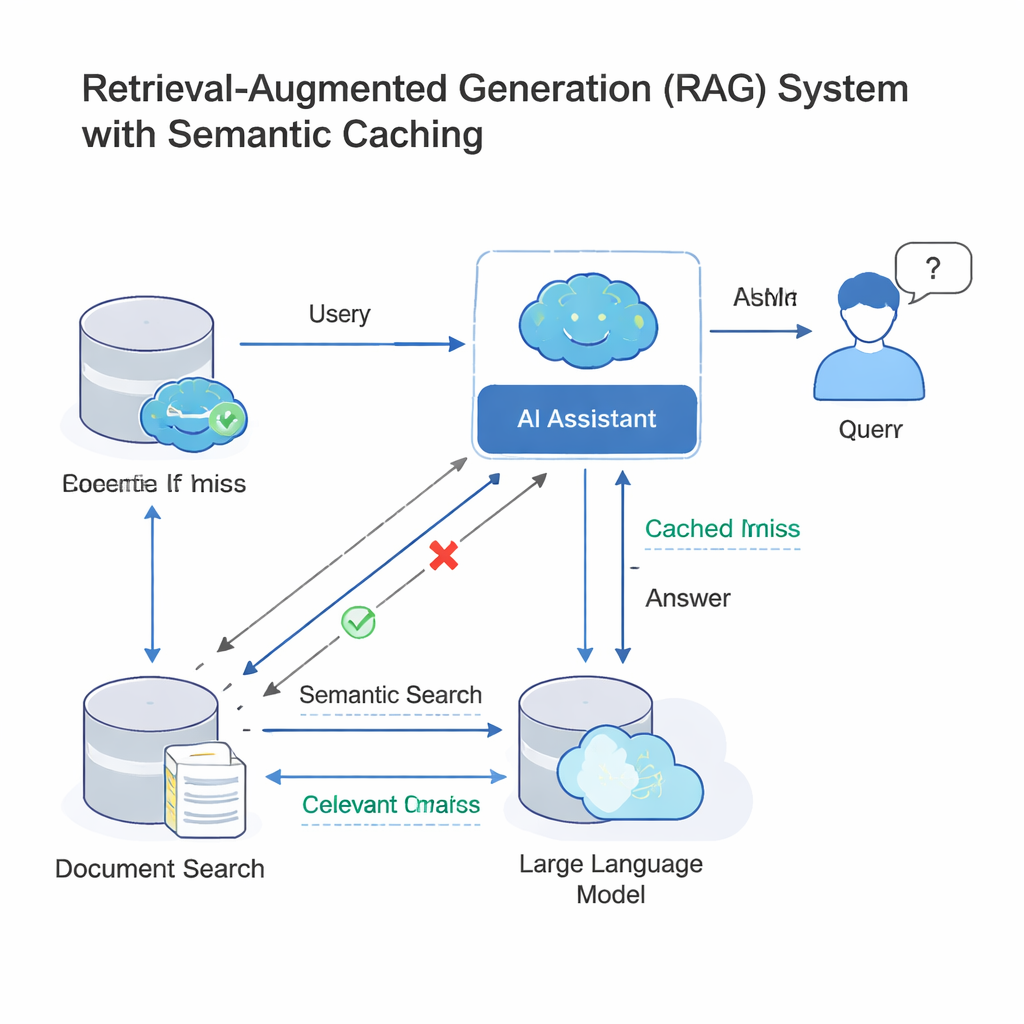
Quand une formulation ingénieuse devient une faille de sécurité
Le même raccourci qui améliore la vitesse peut aussi être retourné contre le système. Des attaquants peuvent concevoir des requêtes qui semblent proches en structure mais signifient autre chose — en changeant une date, en substituant une personne ou un lieu, ou en inversant le sens d’une question. Parce que les caches actuels se fient principalement à la similarité numérique des embeddings (ces empreintes de sens), une requête malveillante peut « entrer en collision » avec une requête bénigne dans cet espace vectoriel, même si l’intention a changé. Cette collision peut amener le cache à renvoyer la mauvaise réponse, exposant potentiellement des informations confidentielles ou faisant stocker de mauvaises données pour une réutilisation ultérieure. Des travaux antérieurs ont déjà montré que les bases de données vectorielles et les caches sémantiques peuvent être empoisonnés de cette manière, notamment lorsque de nombreux utilisateurs partagent le même cache sous-jacent dans des systèmes multi‑locataires.
Transformer des questions dispersées en clusters d’intention stables
Les auteurs soutiennent que le problème fondamental est de traiter chaque requête isolément. Leur solution, SAFE-CACHE, regroupe les paires question–réponse passées en clusters représentant des intentions sous-jacentes — par exemple « qui a remporté l’élection sénatoriale de l’Arizona en 2022 ? » ou « quel est le prix du logiciel Full Self-Driving de Tesla ? ». Plutôt que d’apparier les nouvelles requêtes directement à des anciennes individuelles, SAFE-CACHE les compare au centre, ou centroïde, de chaque cluster. Pour construire ces clusters, il embedde d’abord chaque question-plus-réponse complète (et pas seulement la question) afin que les différences de réponses — comme un refus de divulguer des données sensibles — influencent aussi le regroupement. Il utilise ensuite un algorithme de détection de communautés pour trouver des clusters naturels et des tests statistiques pour signaler les groupes bruyants qui pourraient mélanger différentes intentions ou contenir des entrées adverses. Ces clusters suspects sont nettoyés et scindés à l’aide d’un bi‑encodeur spécialement entraîné qui a appris à rapprocher les exemples honnêtes et à éloigner les exemples empoisonnés.
Apprendre à un petit modèle à renforcer la mémoire de l’IA
Certaines intentions n’apparaissent que quelques fois dans le trafic réel, rendant leurs clusters fragiles. Pour les stabiliser, SAFE-CACHE utilise un modèle de langage léger affiné (une variante Gemma-3 d’environ 1 milliard de paramètres) pour générer des paraphrases qui conservent la même intention tout en variant la formulation. Ces exemples supplémentaires densifient les clusters et rendent leurs centroïdes plus fiables, sans nécessiter que des humains étiquettent des milliers de variantes. À l’exécution, chaque nouvelle requête est embeddee et comparée à ces centroïdes. Si sa similarité avec le centroïde le mieux assorti dépasse un seuil finement ajusté, la réponse en cache est renvoyée ; sinon, le système retombe sur la chaîne RAG complète et décide ensuite comment regrouper la nouvelle paire. Dans des expériences utilisant des méthodes d’attaque robustes basées sur la réécriture métamorphique et GPT‑4.1, SAFE-CACHE a réduit les tentatives d’empoisonnement réussies d’environ deux tiers à trois quarts par rapport à une conception de type GPTCache, tout en maintenant pratiquement inchangée la rapidité de réponse. 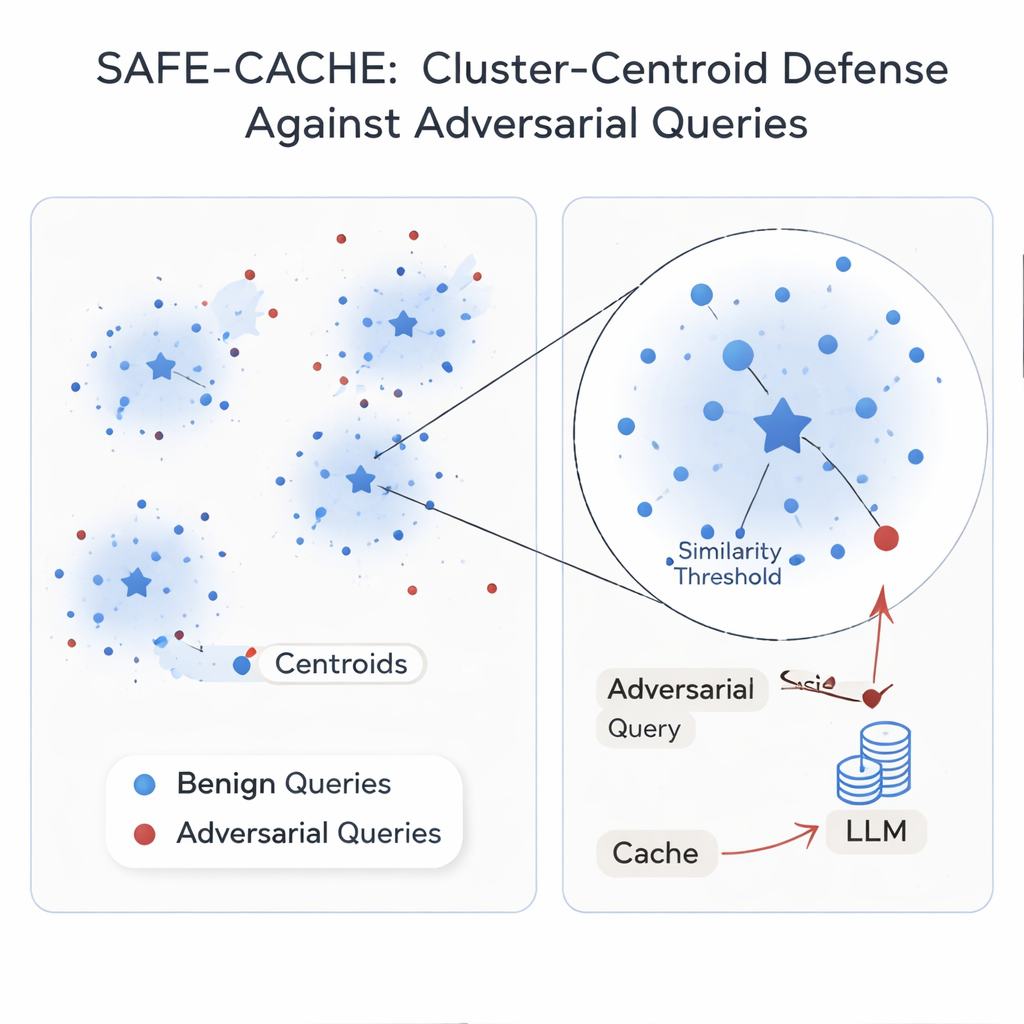
Ce que cela signifie pour les utilisateurs d’IA au quotidien
Pour les non‑spécialistes, la conclusion est que doter les systèmes d’IA d’une « mémoire » n’est pas sans coût : des conceptions naïves peuvent faire fuiter des secrets ou être détournées pour diffuser de mauvaises réponses. SAFE-CACHE montre qu’en organisant la mémoire autour de schémas d’intention plus profonds et en renforçant ces schémas par des paraphrases ciblées, il est possible de conserver les avantages de vitesse et de coût du cache sémantique tout en réduisant fortement le risque d’attaque. Alors que les assistants IA deviennent une porte d’entrée vers des données sensibles — des dossiers d’entreprise aux informations personnelles — des approches comme SAFE-CACHE seront essentielles pour garantir que ce dont l’IA se souvient ne puisse pas être facilement retourné contre nous.
Citation: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Mots-clés: cache sémantique, génération augmentée par récupération, attaques adverses, défense basée sur le clustering, sécurité des LLM