Clear Sky Science · fr
Autoencodeur guidé par l’importance des caractéristiques pour la réduction de dimensionnalité dans les systèmes de détection d’intrusion
Pourquoi des défenses cybernétiques plus intelligentes comptent
Tous les e-mails que vous envoyez, les vidéos que vous diffusez et les achats que vous effectuez transitent sur des réseaux constamment ciblés par des attaques. Les systèmes de détection d’intrusion (IDS) jouent le rôle d’alarmes pour ces réseaux, repérant les comportements suspects avant qu’ils ne dégénèrent en compromission. Mais les données réseau modernes sont vastes et complexes, et trier tous ces détails peut ralentir les systèmes ou les amener à manquer des attaques subtiles. Cet article explore une nouvelle façon de réduire ces données de manière intelligente afin que les outils IDS deviennent à la fois plus rapides et meilleurs pour détecter des cyberattaques rares et difficiles à repérer. 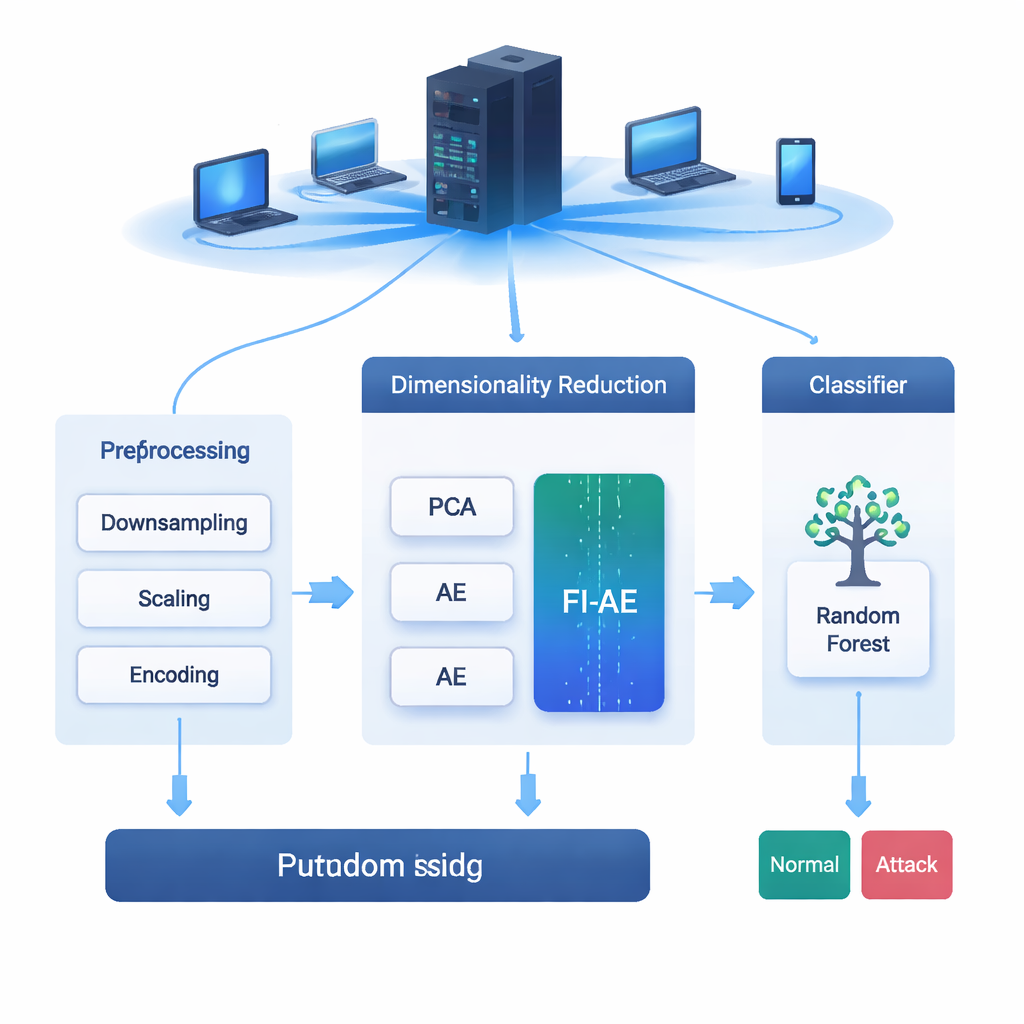
Le problème d’un excès de données réseau
Les enregistrements de trafic réseau contiennent des dizaines à des centaines de mesures pour chaque connexion — comme la durée, le nombre d’octets et les taux d’erreur. Les modèles IDS basés sur l’apprentissage automatique s’appuient sur ces mesures pour décider si le trafic est normal ou malveillant. Cependant, utiliser l’ensemble de ces mesures peut ralentir la détection et parfois même nuire à la précision, en particulier lorsque certaines attaques sont beaucoup plus rares que d’autres. Les méthodes courantes de réduction de dimensionnalité, comme l’analyse en composantes principales (ACP) et les autoencodeurs classiques, compressent les données mais se concentrent surtout sur la reconstruction du trafic global. Cela signifie qu’elles peuvent accorder plus d’attention à la majorité des connexions quotidiennes et négliger les motifs faibles et distinctifs qui caractérisent des types d’attaque minoritaires.
Une nouvelle façon de classer ce qui compte vraiment
Les auteurs présentent un schéma de classement des caractéristiques appelé importance des caractéristiques un-contre-tous (one-versus-all, OVA) pour remédier à ce déséquilibre. Plutôt que de demander « Quelles mesures sont les plus utiles globalement ? », OVA pose la question séparément pour chaque type d’attaque. Pour chaque classe (par exemple, trafic normal, déni de service ou tentative de devinette de mot de passe), un modèle de forêt aléatoire est entraîné pour distinguer cette classe de toutes les autres. Les scores d’importance intégrés du modèle révèlent alors quelles mesures sont particulièrement utiles pour cette classe spécifique. En répétant ce processus classe par classe puis en prenant, pour chaque mesure, la plus grande importance qu’elle atteint pour n’importe quelle classe, la méthode construit un vecteur de poids unique qui met en avant les caractéristiques utiles pour au moins un type d’attaque — même si cette attaque est rare dans les données.
Apprendre à un autoencodeur à se concentrer sur les signaux clés
Pour tirer parti de ces poids, les chercheurs conçoivent un autoencodeur basé sur l’importance des caractéristiques (FI-AE). Comme un autoencodeur conventionnel, le FI-AE compresse l’entrée en une représentation « goulot d’étranglement » de faible dimension puis reconstruit les données originales. La différence se situe dans l’objectif d’entraînement : au lieu de traiter toutes les erreurs de reconstruction de la même façon, le modèle utilise une erreur quadratique moyenne pondérée qui multiplie l’erreur de chaque caractéristique par son importance basée sur OVA. En termes simples, le FI-AE est davantage pénalisé lorsqu’il mal représente des mesures cruciales pour distinguer les attaques, et moins pour des détails moins informatifs. L’architecture elle-même reste compacte, comprimant les enregistrements réseau en seulement 16 nombres tout en adoptant des techniques standards telles que la normalisation par batch, le dropout et l’optimiseur Adam pour stabiliser l’apprentissage.
Mettre la méthode à l’épreuve
L’équipe évalue le FI-AE sur trois jeux de données largement utilisés en détection d’intrusion : NSL-KDD, UNSW-NB15 et CIC-IDS2017, qui couvrent ensemble des millions de connexions et une large gamme de types d’attaque. Avant l’entraînement, ils préparent les données en rééquilibrant des distributions de classes extrêmement biaisées, en mettant à l’échelle les caractéristiques numériques et en encodant les catégories d’une manière qui préserve leur relation avec les étiquettes cibles. Ils comparent ensuite trois pipelines qui aboutissent tous à un classificateur forêt aléatoire : l’un utilisant l’ACP, l’un un autoencodeur standard et l’un le FI-AE pour la réduction de dimensionnalité. Sur les trois jeux de données, le FI-AE offre systématiquement une meilleure précision et de meilleurs scores F1, avec des gains particulièrement marqués sur les attaques minoritaires et rares où les méthodes traditionnelles peinent généralement. 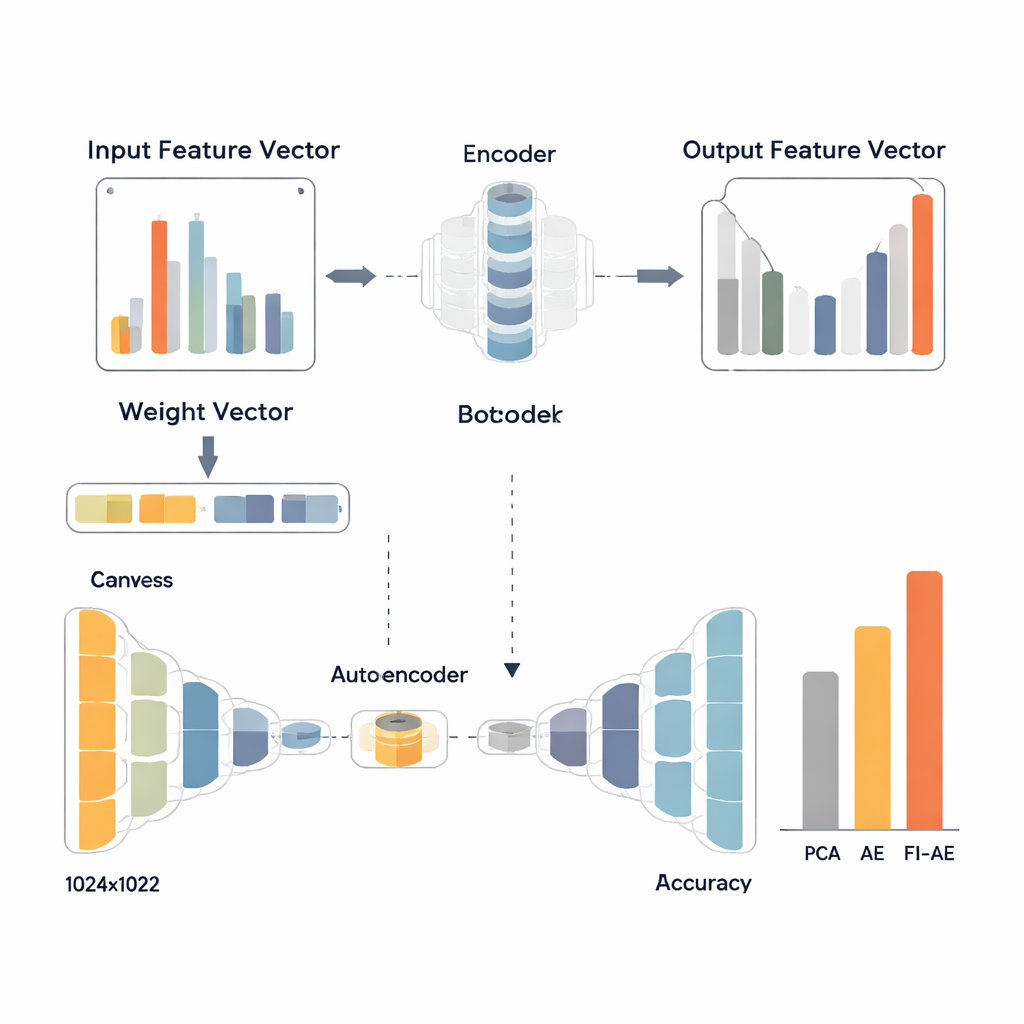
Ce que cela signifie pour la sécurité de tous les jours
Pour les non-spécialistes, le message clé est que ce travail propose une lentille plus discriminante pour la surveillance réseau. Plutôt que de simplement compresser les données pour les rendre plus petites, le FI-AE apprend à préserver les mesures qui comptent vraiment pour détecter différents types d’attaques, y compris les rares qui peuvent être les plus dommageables. Avec seulement 16 caractéristiques distillées, les systèmes de détection d’intrusion fondés sur cette approche peuvent fonctionner plus efficacement tout en atteignant ou en surpassant la précision de détection de pointe. En pratique, cela signifie que les outils de sécurité peuvent analyser plus de trafic, réagir plus rapidement et offrir une meilleure protection aux services numériques sur lesquels les gens comptent au quotidien.
Citation: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Mots-clés: détection d’intrusion, sécurité réseau, réduction de dimensionnalité, autoencodeur, importance des caractéristiques