Clear Sky Science · fr
Reconnaissance intelligente du comportement des élèves pour des environnements d’apprentissage intelligents
Pourquoi les salles de classe plus intelligentes doivent voir ce que font les élèves
Dans de nombreuses classes, les enseignants doivent deviner qui suit le cours, qui est perdu et qui est discrètement hors tâche. Cet article explore comment l’intelligence artificielle peut reconnaître automatiquement ce que font les élèves — par exemple lire, écrire ou lever la main — à partir de photos de classe ordinaires. En transformant des images brutes en mesures fiables de l’activité en classe, le système vise à fournir aux enseignants un retour en temps réel sur l’engagement sans recourir à des observations longues ou à une surveillance intrusive.
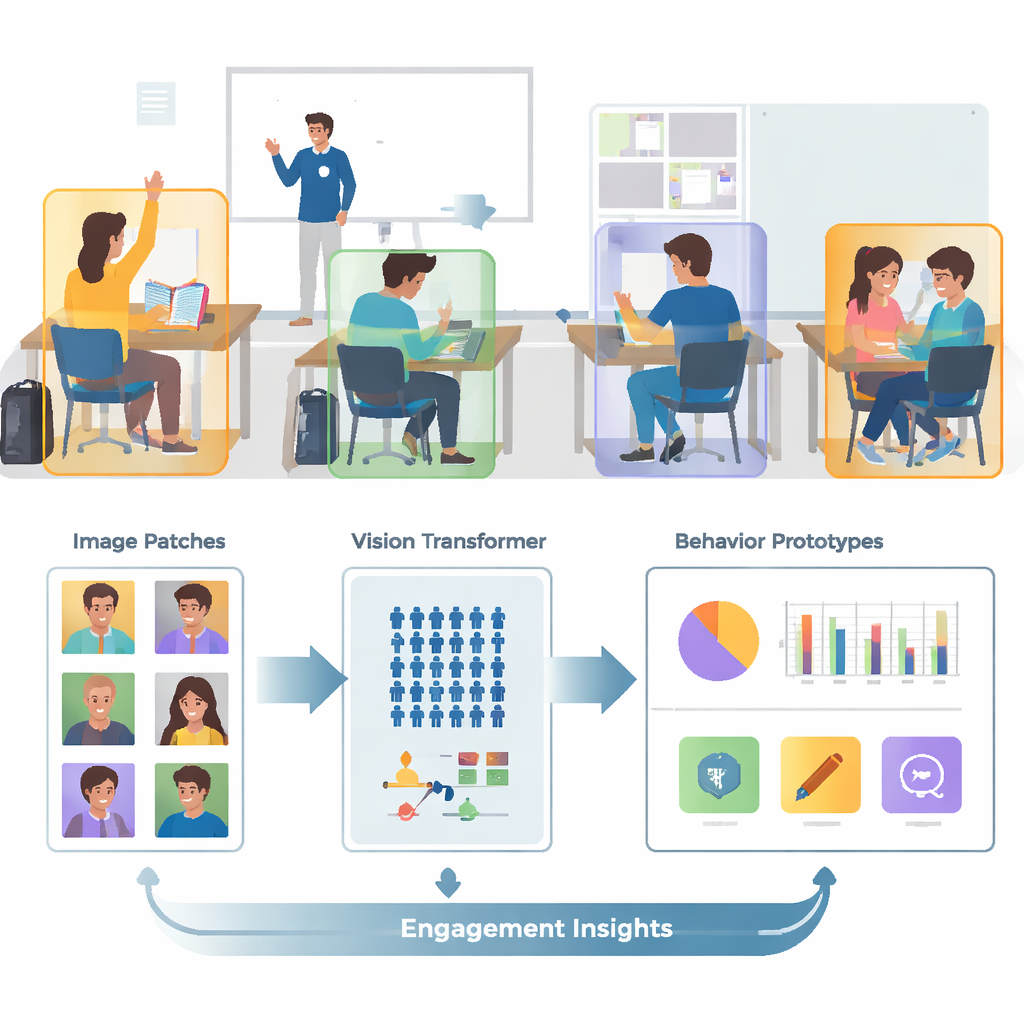
Des photos désordonnées à des instantanés ciblés
Les classes réelles sont encombrées, animées et visuellement confuses. Une seule image peut contenir des dizaines d’élèves, des corps qui se chevauchent et des détails d’arrière‑plan distrayants comme des murs, des écrans et des affiches. Les auteurs s’appuient sur une collection d’images publique appelée SCB‑05, qui contient des milliers de photos de classe étiquetées avec des comportements spécifiques — comme lever la main, lire, écrire, se tenir debout, parler ou interagir au tableau. Plutôt que d’envoyer des scènes entières à l’ordinateur, le système utilise d’abord des fichiers d’annotation pour recadrer uniquement les régions autour de chaque élève ou enseignant. Cette étape de prétraitement supprime une grande partie du désordre visuel, de sorte que le modèle peut se concentrer sur la posture, la position des mains et d’autres indices qui distinguent un comportement d’un autre.
Comment l’IA apprend de nouveaux comportements à partir de très peu d’exemples
Un obstacle majeur est que certains comportements en classe sont courants dans les données (comme la lecture) tandis que d’autres sont rares (comme de brèves interactions sur scène). Recueillir suffisamment d’images annotées pour chaque comportement possible est coûteux et soulève des questions de confidentialité. Pour surmonter cela, les auteurs utilisent une stratégie appelée « apprentissage par peu d’exemples » (few‑shot learning), dans laquelle le modèle est entraîné à reconnaître de nouvelles classes à partir d’une poignée d’exemples. Ils organisent l’entraînement sous la forme de nombreuses petites tâches, chacune contenant seulement quelques comportements et quelques images d’exemple par comportement. Pour chaque tâche, le système forme un simple « prototype » pour chaque comportement en moyennant sa représentation interne de ces exemples. Les nouvelles images sont alors classées en fonction du prototype auquel elles sont les plus proches, permettant au modèle de s’adapter rapidement même lorsque les données sont rares.
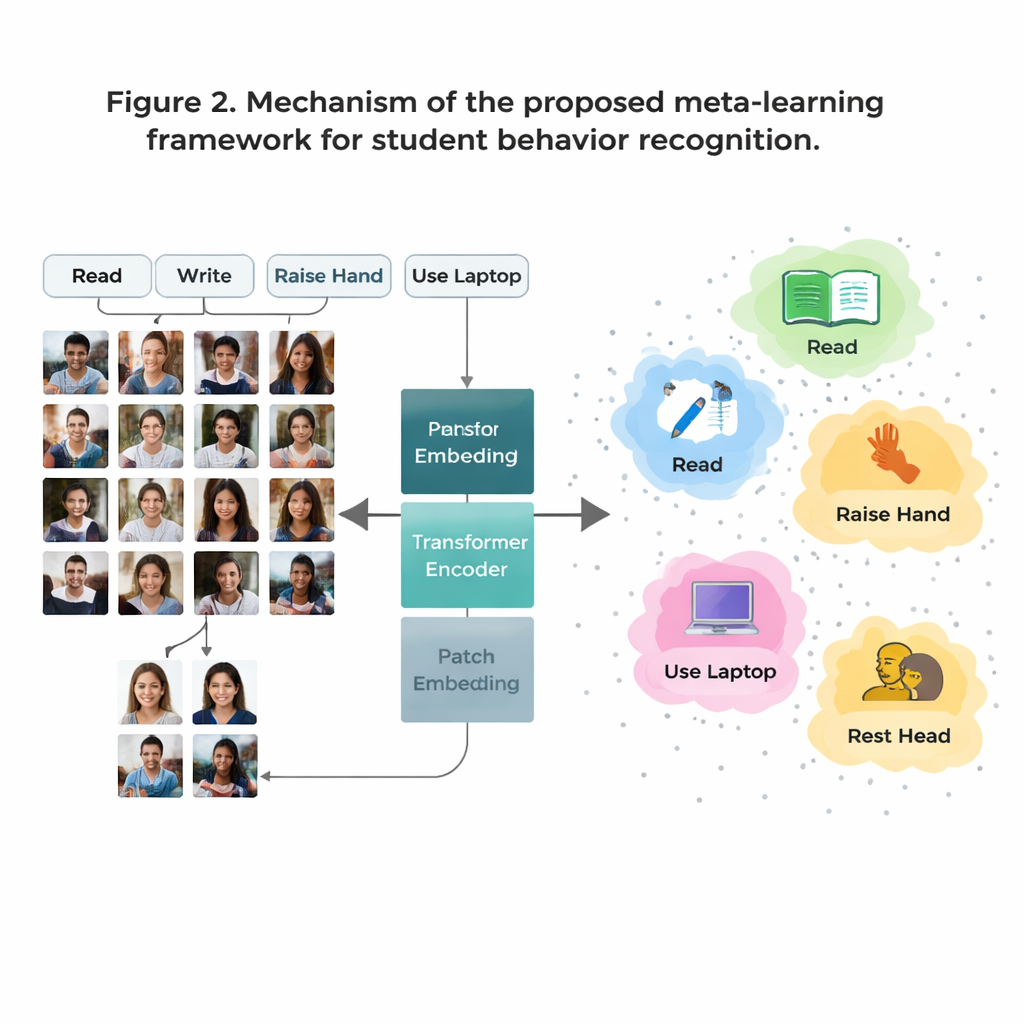
Voir la classe dans son ensemble, pas seulement les petits détails
Les systèmes d’image traditionnels appelés réseaux de neurones convolutionnels ont tendance à se focaliser sur de petits motifs locaux, comme des contours ou des textures. Cela peut être limitant lorsque deux comportements, comme lire et écrire, se ressemblent beaucoup de près. Ce travail remplace ces anciens réseaux par un Vision Transformer, un modèle qui découpe chaque image en patchs et apprend comment tous les patchs se relient entre eux. Cette vue globale aide le système à comprendre des différences subtiles de posture et des indices à longue portée — comme la relation entre une main levée et un enseignant au devant de la salle. L’équipe affine en outre le modèle en l’entraînant à rapprocher les images du même comportement tout en éloignant celles de comportements voisins mais différents, en mettant un accent supplémentaire sur les cas « durs » et confus. Cela rend la cartographie interne des comportements plus nette et plus facile à séparer.
Quelle est son efficacité et pourquoi cela compte
Sur le benchmark SCB‑05, la méthode proposée atteint environ 91 % de précision globale et de bons scores sur des mesures plus exigeantes qui tiennent compte du déséquilibre des données. Les comportements courants comme la lecture et le fait de lever la main sont reconnus particulièrement bien, tandis que les plus rares, comme l’écriture au tableau, restent plus difficiles mais présentent tout de même de meilleures performances que les systèmes antérieurs. Des inspections visuelles des grappes internes du modèle montrent que les différents comportements forment des groupes serrés et bien séparés, indiquant que l’IA a appris des « signatures » distinctes des actions en classe. Lorsqu’elle est testée sur un autre jeu de données de classe avec de nouveaux angles de caméra et aménagements, la performance a légèrement chuté, suggérant que la représentation apprise n’est pas liée à une seule salle ou école.
Ce que cela signifie pour l’enseignement et l’apprentissage
En termes concrets, l’étude montre que les ordinateurs peuvent repérer de manière fiable de nombreux comportements clés des élèves à partir d’images fixes, même lorsqu’ils n’ont vu que quelques exemples de chaque. Plutôt que de remplacer les enseignants, de tels systèmes pourraient résumer discrètement qui est engagé, qui cherche fréquemment de l’aide ou quelles activités tendent à provoquer une perte d’attention — le tout sans suivre l’identité des élèves. Avec des travaux supplémentaires sur la confidentialité, l’équité et l’analyse vidéo dans le temps, ce type d’IA sensible au comportement pourrait devenir un allié puissant pour les éducateurs souhaitant concevoir des environnements d’apprentissage plus réactifs et inclusifs.
Citation: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Mots-clés: salle de classe intelligente, comportement des élèves, vision par ordinateur, apprentissage par peu d’exemples, vision transformer